Модель U-net
Модель U-net [1] осуществляет семантическую сегментацию, используя свёрточный кодировщик и декодировщик.
Кодировщик постепенно сжимает пространственное разрешение, применяя свёртки 3x3 без расширения (padding), а также используя пулинги 2x2 с шагом 2. Сжатие разрешения компенсируется увеличением числа слоёв после каждого пулинга.
Декодировщик постепенно увеличивает пространственное разрешение, используя операции повышения пространственного разрешения (upsampling) с одновременным уменьшением числа каналов. В декодировщике также применяются свёртки 3x3.
Проблема недостаточно точного восстановления границ из низкоразмерного промежуточного представления кодировщика решается тем, что внутренние представления кодировщика с более высоким пространственным разрешением передаются на соответствующие слои декодировщика, как показано серыми линиями на схеме [1]:
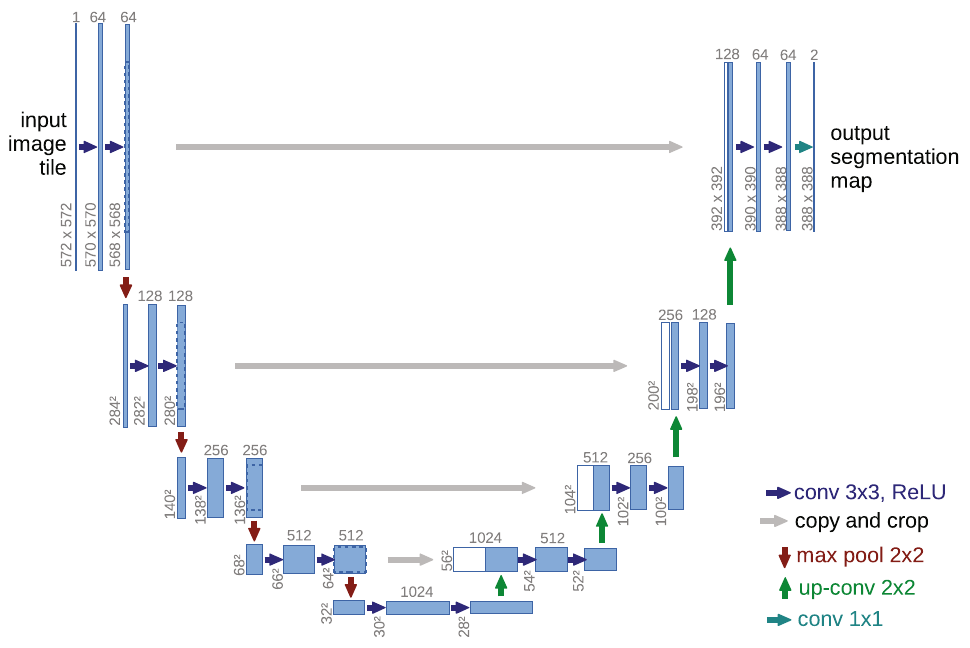
Объединение информации из декодировщика и кодировщика происходит путём конкатенации (объединения) внутренних представлений вдоль каналов.
Выходом U-net является тензор , где
-
- высота и ширина сегментируемого изображения;
-
- число классов, включая фоновый (на схеме ).
К выходу для каждого пикселя применяется SoftMax преобразование, чтобы получить вероятности классов. Модель настраивается, используя кросс-энтропийную функцию ошибки.
Поскольку в сети многократно применяются свёртки 3x3 без расширения, то пространственная размерность постепенно снижается на границах. Поэтому при переносе внутренних представлений с кодировщика, они обрезаются по краям, чтобы конкатенировались тензоры одинакового пространственного разрешения.
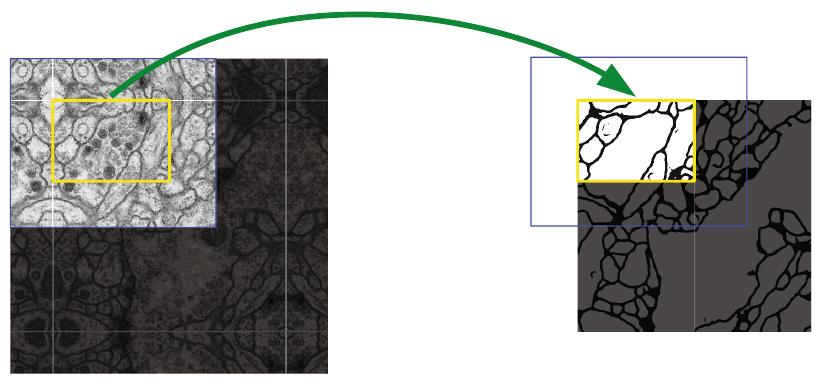
Для того, чтобы после всех свёрток на выходе получить ту же пространственную размерность, которой обладало сегментируемое изображение, входное изображение представляет собой сегментируемое изображение, расширенное с помощью отражения пикселей по краям (mirror padding), как показано на рисунке [1]:
Сеть настраивалась, используя максимизируя взвешенное правдоподобие каждого пикселя
Вес учёта каждого пикселя считался по формуле
где
-
- гиперпараметры,
-
- вес класса (выше для более редких, чтобы классы вносили сопоставимый вклад в оптимизацию),
-
- минимальные расстояние до ближайшей границы с областью другого класса и ближайшее расстояние до границы ещё одного другого класса.
Такое взвешивание позволяло сильнее учитывать редкие классы, а также точнее выделять границы между областями разных классов.
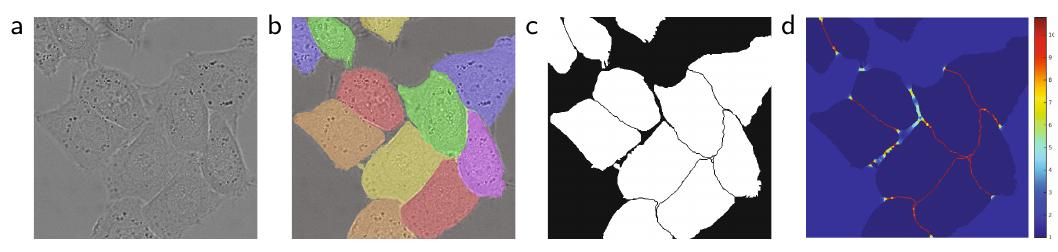
Ниже на графике (d) показана пространственная карта весов для сегментируемого изображения (a), корректной сегментации (b) и сегментационной карты (с) [1]:
Архитектура U-net задала стандарт переноса промежуточных представлений кодировщика в декодировщик и сейчас э�тот принцип используется во многих image-to-image задачах.