Нормализация признаков
Входные признаки в большинстве случаев будут иметь разный масштаб (диапазон изменения значений признака): одни признаки могут изменяться в диапазоне , другие - в и т.д. Как мы впоследствии увидим из описаний методов машинного обучения, для большинства из них масштаб признаков будет оказывать влияние на прогноз. Для таких моделей чем выше разброс значений признака, тем сильнее он будет влиять на прогноз, перекрывая влияние признаков меньшего масштаба.
Рассмотрим в качестве примера классификацию методом ближайшего соседа (nearest neighbor), который для каждого объекта назначает тот класс, к которому принадлежит ближайший к нему объект из обучающей выборки. Для простоты рассмотрим классификацию на 2 класса (зелёный и красный) в двумерном пространстве признаков. Обучающая выборка состоит из двух объектов и требуется построить прогноз для точки в начале координат.
Исходная обучающая выборка приведена на рисунке слева:
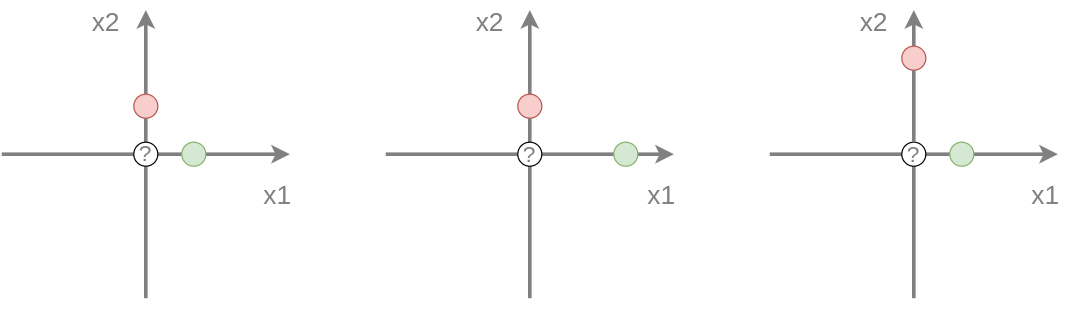
Как видим, обучающие объекты равноудалены от точки, для которой требуется сделать прогноз, поэтому оба класса равновероятны. Если мы умножим первый признак на два , то прогнозом станет красный класс, как более близкий (в центре изображения). А если умножим на два второй признак , то прогнозом будет уже зелёный класс (справа)!
Чем выше разброс вдоль определённого признака, тем сильнее он влияет на прогноз, поэтому, чтобы влияние всех признаков было одинаковым, их необходимо нормализовать, то есть привести к одному масштабу. Наиболее распространены следующие способы:
| Название | Преобразование | Выходные свойства |
|---|---|---|
| Стандартизация | нулевое среднее и единичная дисперсия | |
| Диапазонное шкалирование | принадлежит интервалу [0,1] | |
| Нормализация средним | нулевое среднее, с единичным диапазоном |
Каждый вид шкалирования применяется к каждому признаку (столбц�у в матрице объекты-признаки X) независимо.
Самым популярным методом нормализации признака является стандартизация признака (standardization, standard scaler). Вторым по популярности является диапазонное шкалирование (min-max scaler). Оно хорошо тем, что значения признака из отрезка [0,MAX] переводятся в отрезок [0,1], причём ноль переходит в ноль, что полезно для разреженных данных (sparse data), в которых большинство значений - нули. Такие данные часто возникают на практике и эффективно кодируются разреженными матрицами (sparse matrix, [1]), которые экономично их хранят и производят операции над ними, оперируя только ненулевыми элементами. Диапазонное шкалирование позволяет сохранить свойство разреженности.
Влияние выбросов
Наличие выбросов (аномально больших или малых значений) искажает результат нормализации, так наличие даже одного выбр�оса может существенно сместить среднее, дисперсию, минимум или максимум. Поэтому важно предварительно отфильтровать выбросы из выборки. Альтернативно можно заменить неустойчивые к выбросам статистики на устойчивые по схеме ниже:
| неустойчивая статистика | робастный аналог | значение |
|---|---|---|
| центр распределения | ||
| разброс распределения | ||
| 1% перцентиль | минимум | |
| 99% перцентиль | максимум |
где .
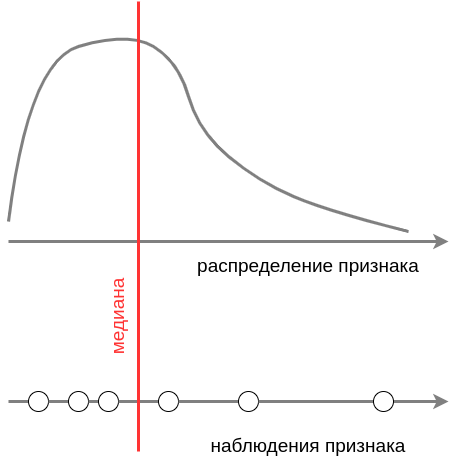
Медиана
Медиана (median) - величина, альтернативная выборочному среднему (mean) для оценки центра распределения. Для выборки значений признака медиана - это такое значение, что половина наблюдений оказываются меньше, а другая половина - больше этого значения. Для вероятностного распределения медиана - это такое значение, что половина вероятностной массы лежит слева, а другая половина - справа от значения медианы.
p-процентная перцентиль
-процентная перцентиль (percentile) - это такое значение, что
-
для выборки наблюдений процентов наблюдений лежит слева, а процентов - справа от значения.
-
для вероятностного распределения признак с вероятностью принимает значение меньше, а с вероятностью - больше значения перцентили.
Как видно, -квантиль соответствует -процентной перцентили.