Сокращение числа признаков
Исходных признаков может быть слишком много в силу избыточного сбора даже слабоинформативных данных. Либо могло появиться много новых признаков после их генерации из существующих.
Число оцениваемых параметров модели растет с увеличением числа признаков. Например, линейные модели прогнозируют отклик, отталкиваясь от линейной комбинации признаков с оцениваемыми весами. Чем больше признаков, тем больше весов нужно оценить. При ограниченной обучающей выборке это будет приводить к неточной оценке коэффициентов и переобучению модели. Увеличение числа признаков также увеличивает накладные расходы на хранение и обработку данных.
Поэтому, если число входных признаков велико, то их количество сокращают, что может осуществляться
-
методами отбора признаков (feature selection);
-
методами снижения размерности (dimensionality reduction).
Различие подходов графически показано ниже:
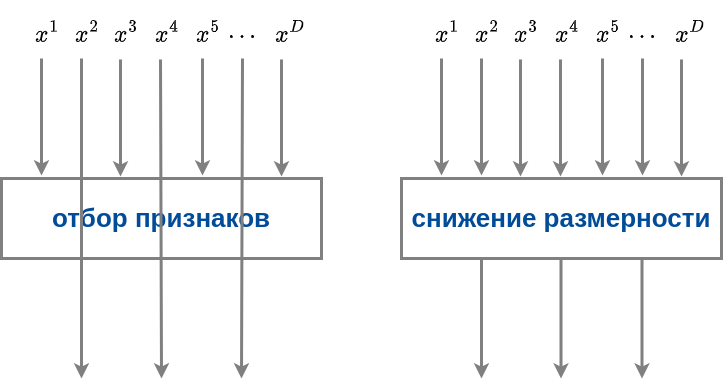
При отборе признаков используется подмножество из исходных признаков, а остальные просто отбрасываются. При снижении размерности каждый выходной признак получается некоторым преобразованием над всеми исходными признаками.
Существует много методов отбора признаков. Многие из них описаны в [1]. Например, можно выбрать подмножество признаков, которые сильнее всего скоррелированы с откликом. А в качестве снижения размерности часто используется метод главных компонент (principal component analysis, PCA), который линейной трансформацией переводит объекты из многомерного признакового пространства в маломерное таким образом, чтобы сумма квадратов расстояний от исходных объектов до их проекций оказывалась наименьшей, как показано ниже (при переводе объектов из трёхмерного признакового пространства в двумерное):
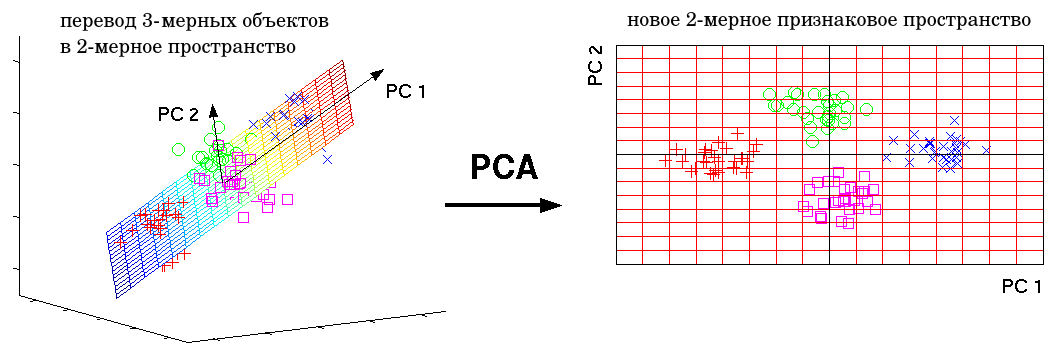
Теоретические основы метода и способ реализации можно прочитать в [2].