Снижение размерности методом LDA
Ранее мы изучили линейный дискриминантный анализ (Linear Discriminant Analysis, LDA) ка�к вероятностную модель, основанную на предположении о нормальном распределении признаков внутри каждого класса с общей ковариационной матрицей :
Однако популярность этого метода обусловлена не только его свойствами классификатора, но и возможностью строить информативные проекции данных в пространство низкой размерности в режиме обучения с учителем (supervised), то есть учитывая метки классов.
Учёт меток позволяет находить направления, проекции на которые лучше дискриминируют классы, как показано на рисунке ниже, на котором показана главная компонента, извлечённая методом LDA и PCA:
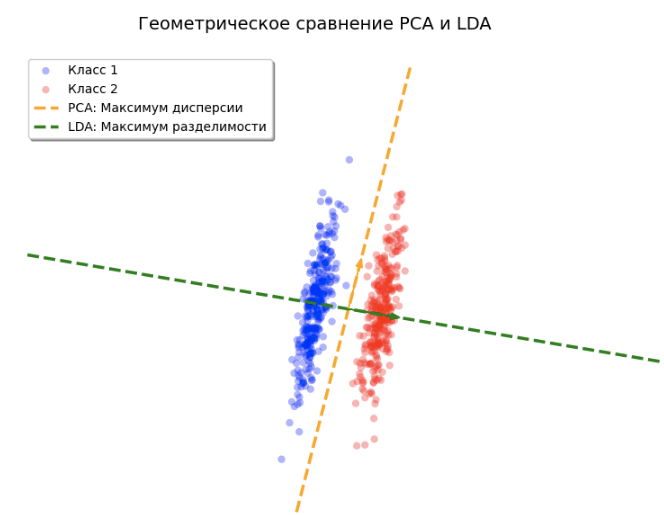
Главная компонента метода PCA учитывает только направления максимального разброса признаков, что не всегда сочетается с качеством разделения классов, как в приведённом случае.
Геометрия ближайших центроидов
Рассмотрим дискриминантную функцию LDA, полученную на промежуточном этапе вывода в прошлой главе:
Здесь выражение представляет собой квадрат расстояния Махаланобиса (Mahalanobis distance) между точкой и центроидом класса .
Таким образом, LDA можно интерпретировать как метод ближайшего центроида (nearest centroid method), где расстояние измеряется с учётом корреляционной структуры данных (), а выбор класса корректируется на априорную вероятность (prior probability) .
Декорреляция данных
Расстояние Махаланобиса кажется сложным, но его легко свести к обычному евклидову расстоянию через преобразование декорреляции (decorrelation):
Покажем, что в новом декоррелированном пространстве после указанного преобразования расстояние становится евклидовым:
Декоррелирующее преобразование преобразует пространство таким об�разом, что эллипсоидальное облако исходных объектов превращается в распределение точек внутри сферы. Далее в этом пространстве вычисляется обычное евклидово расстояние.
Если - вектор-строка (а не столбец, как обычно), то декоррелирующее преобразование будет получаться транспонированием:
Мы воспользовались свойством для симметричном матрицы .
Неявное снижение размерности
Важной особенностью LDA является скрытое снижение размерности. Если у нас есть центроидов в -мерном пространстве, то они всегда лежат в некотором аффинном подпространстве размерности не более .
При поиске ближайшего центроида (в сферическом пространстве) мы можем полностью игнорировать любые отклонения объекта, которые перпендикулярны этому подпространству, так как они вносят одинаковый вклад в расстояние до каждого класса. Следовательно, для работы LDA достаточно рассматривать данные только в подпространстве размерности .
Метод проекций (Reduced-Rank LDA)
Если нам нужно снизить размерность до уровня (например, до для визуализации), мы должны выбрать наиболее информативное подпространство. Будем считать таким то подпространство, в котором проекции центроидов максимально разнесены с учётом мощности каждого центроида (числа объектов в соответствующем классе).
Для этого применяется метод главных компонент (PCA), но для центроидов с учётом их веса (числа объектов в соответствующем кластере):
- Находится общая матрица ковариации исходных данных.
- Вычисляется матрица центроидов .
- Проводится декорреляция центроидов: .
- Вычисляется межклассовая матрица разброса для трансформированных средних с учётом частотности классов :
Здесь — общее среднее в новом пространстве.
Затем находится собственных векторов , матрицы , отвечающих максимальным собственным значениям (главные компоненты). Эти векторы определяют направления в декоррелированном пространстве, вдоль которых центроиды классов имеют максимальный разброс.
Ограничение на количество компонент
Метод LDA позволяет извлечь не более информативных направлений, поскольку справедливо следующее утверждение:
Утверждение:
Ранг матрицы не превосходит .
Доказательство:
Матрица является суммой внешних произведений векторов вида . Заметим, что по определению общего среднего выполняется условие:
Это означает, что векторы отклонений центроидов линейно зависимы. Следовательно, подпространство, натянуто�е на эти векторы, имеет размерность не более . Ранг матрицы (количество её ненулевых собственных чисел) также ограничен этой величиной.
Если в вашей задаче всего 2 класса (бинарная классификация), LDA всегда предложит только одну главную компоненту (проекцию на прямую), даже если исходных признаков тысячи. Для визуализации данных в 2D (на плоскости) методом LDA требуется наличие как минимум 3-х классов.
Направления в исходном пространстве
Чтобы спроецировать исходный объект на -ю дискриминантную ось, нам нужно найти соответствующий вектор весов в исходном признаковом пространстве.
Как было показано ранее, результат проекции в сферическом пространстве равен:
Следовательно, искомый вектор направления выражается формулой:
Свойства метода
Векторы , будучи главными компонентами в декоррелированном пространстве, имеют единичную норму и взаимно ортогональны:
Однако это свойство не сохраняется для соответствующих дискриминантных направлений в исходном пространстве.
Визуально в исходном пространстве оси LDA могут выглядеть как пересекающиеся под произвольным углом. Это происходит потому, что LDA «подстраивается» под эллиптическую форму облака данных.
Таким образом, при переходе к исходным признакам мы жертвуем привычной евклидовой ортонормированностью векторов ради сохранения сильных дискриминирующих свойств новых признаков.
Однако для этих векторов справедливо следующее свойство:
Отсюда следует следующее важное свойство проекций на дискриминантные направления:
Утверждение: нескоррелированность признаков
Новые признаки , полученные путём проекции центрированных данных на дискриминантные направления , нескоррелированы между собой и имеют единичную дисперсию.
Доказательство:
Рассмотрим ковариацию между двумя новыми признаками и . Поскольку исходные признаки центрированы (), математическое ожидание проекций также равно нулю: .
Тогда ковариация записывается как:
Воспользуемся линейностью математического ожидания и вынесем векторы весов за знак оператора:
Используя ранее доказанное свойство , получаем:
Таким образом, при ковариация (а значит, и корреляция) равна нулю. При дисперсия каждого нового признака равна единице.