Метод главных компонент
Новые признаки как проекции
В машинном обучении мы привыкли работать с исходными признаками объекта . Однако часто гораздо полезнее рассматривать не сами значения признаков, а их линейные комбинации. Любую такую комбинацию можно представить как скалярное произведение вектора объекта на некоторый вектор весов :
Рассмотрим примеры того, как линейные комбинации позволяют извлекать смысл из данных:
Средняя оценка: Если — оценки студента по 5 предметам, а , то равен среднему баллу.
Разница стоимостей: Если — цены акции, а , то характеризует суточное изменение цены.
Суммарная активность: Если — количество действий пользователя в разные часы суток, скалярное произведение его на покажет общее количество действий за сутки.
Цветовой баланс: В обработке изображений проекция RGB-вектора на позволяет перевести цветной пиксель в яркость (оттенки серого).
Если мы ограничим вектор условием единичной нормы (), то значение проекцию объекта на него можно находить как скалярное произведение:
Почему так?
Это утверждение опирается на определение скалярного произведения и тригонометрию в прямоугольном треугольнике. Разберём это подробнее.
Скалярное произведение двух векторов и можно выразить через их длины и косинус угла между ними:
Если мы наложим условие единичной нормы на вектор , то есть , формула упрощается:
Последнее выражение как р�аз и равно длине проекции (со знаком, в зависимости от направления векторов).
Возникает вопрос: какие именно вектора обеспечивают максимальное сохранение информации об исходных данных?
Метод главных компонент (principal component analysis, PCA) решает эту задачу, предлагая последовательно находить направления, вдоль которых данные сохраняют наибольшую изменчивость.
Определение и свойства
Индивидуально каждая -я главная компонента (principal component) определяется как направление , которое обеспечивает максимум дисперсии проекций данных на него при условии, что этот вектор ортогонален всем ранее найденным компонентам .
Линейная оболочка первых главных компонент образует -мерное подпространство наилучшей аппроксимации. Оно является оптимальным в глобальном смысле: среди всех возможных подпространств размерности именно это подпространство лучше всего описывает структуру исходных данных, максимизируя средний квадрат длин проекций на него и минимизируя средний квадрат длин ошибок аппроксимации исходных объектов их проекциями.
Метод порождает новое признаковое описание объектов в виде длин проекций объекта на первые главных компонент, компактно и информативно описывающих исходные данные.
Новые признаки обладают удобными свойствами:
- они являются нескоррелированными;
- вектора значений каждого признака линейно независимы, если ранг матрицы признаков не ниже : .
Это упрощает настройку последующих моделей на этих признаках, делая её более стабильной.
Аналитический вид главных компонент
Главные компоненты представляют собой собственные векторы матрицы , которая является ковариационной матрицей признаков, предварительно центрированных относительно их среднего значения. При этом каждое соответствующее собственное значение (eigenvalue) характеризует величину дисперсии (информативности), сосредоточенной вдоль выбранной компоненты.
Алгоритм применения
Процедура применения PCA на практике выглядит следующим образом:
- Центрирование данных:
- Вычисление ковариационной матрицы и её спектральное разложение:
- Переход к новым признакам:
где — матрица, составленная из первых столбцов матрицы собственных векторов , которые и являются первыми главными компонентами.
При этом собственные значения описывают количество информации, которое соответствующие компоненты по отдельности описывают в исходных данных.
Если требуется получить вектор аппроксимации , извлекаемый по первым главным компонентам исходного вектора , это можно сделать, вернувшись из базиса главных компонент в исходное признаковое пространство по следующей формуле:
Это может быть полезным, например, для в задачах фильтрации данных от шума.
Применение метода на практике
Метод главных компонент (principal component analysis, PCA) находит широкое применение в анализе данных, когда необходимо упростить структуру признакового пространства, сохранив при этом максимум полезной информации.
Рассмотрим основные способы его использования:
-
Визуализация данных: При или многомерные объекты можно отобразить на плоскости или в пространстве. Это позволяет визуализировать многомерные данные, увидеть на них кластеры, аномалии и общие закономерности.
-
Сжатие данных: Метод позволяет хранить основную информацию о многомерных объектах, используя небольшое число признаков. Например, в алгоритме Eigenfaces изображения человеческих лиц компактно представляются в виде линейной комбинации небольшого числа «эталонных» лиц.
-
Фильтрация шума (noise filtering): Если предположить, что компоненты с очень малыми собственными числами описывают случайные флуктуации в данных, то представляя объекты как комбинацию только первых самых значимых главных компонент мы получим версии объектов, очищенные от шума.
-
Предварительная обработка: Метод главных компонент часто используется перед применением регрессионных моделей или нейросетей. Он решает проблему мультиколлинеарности признаков (ситуации, когда признаки сильно коррелируют друг с другом), приводящей к неустойчивости настройки весов модели.
-
Компактное информативное описание: Вместо исходного многомерного описания данных, которое часто бывает избыточным, метод генерирует компактное информативное описание данных, которое легче обрабатывать последующими алгоритмами. При этом, настраивая число используемых компонент , можно эффективно управлять степенью переобучения модели: уменьшение снижает эффективную сложность модели, ограничивая её способность «подстраиваться» под шум в данных.
Предварительная подготовка признаков
Перед применением метода главных компонент крайне важно выполнить стандартизацию (standardization) признаков, включающую центрирование и приведение признаков признаков к одному масштабу.
Это важно по следующим причинам:
-
Если не провести центрирование (вычитание глобального среднего значения из каждого объекта), первая главная компонента может указать не на направление максимального разброса, а на вектор, направленный из начала координат к центру облака точек. Тогда алгоритм не будет описывать внутреннюю структуру данных.
-
Если один признак измеряется в миллионах, а другой — в долях единицы, метод ошибочно решит, что направление первого признака содержит всю информацию просто из-за разницы в масштабе.
Вычислительная сложность
Алгоритм состоит из трёх основных этапов: стандартизация признаков, расчёт ковариационной матрицы и поиск её собственных векторов.
Сложность нахождения всех собственных векторов и собственных чисел матрицы размера равна .
На практике нас чаще всего интересует не полное разложение, а нахождение только первых главных компонент. В этом случае их можно вычислить с использованием степенного метода (power method) за .
Также часто главные компоненты находят из сингулярного разложения (singular value decomposition, SVD) матрицы данных .
Оценка числа главных компонент
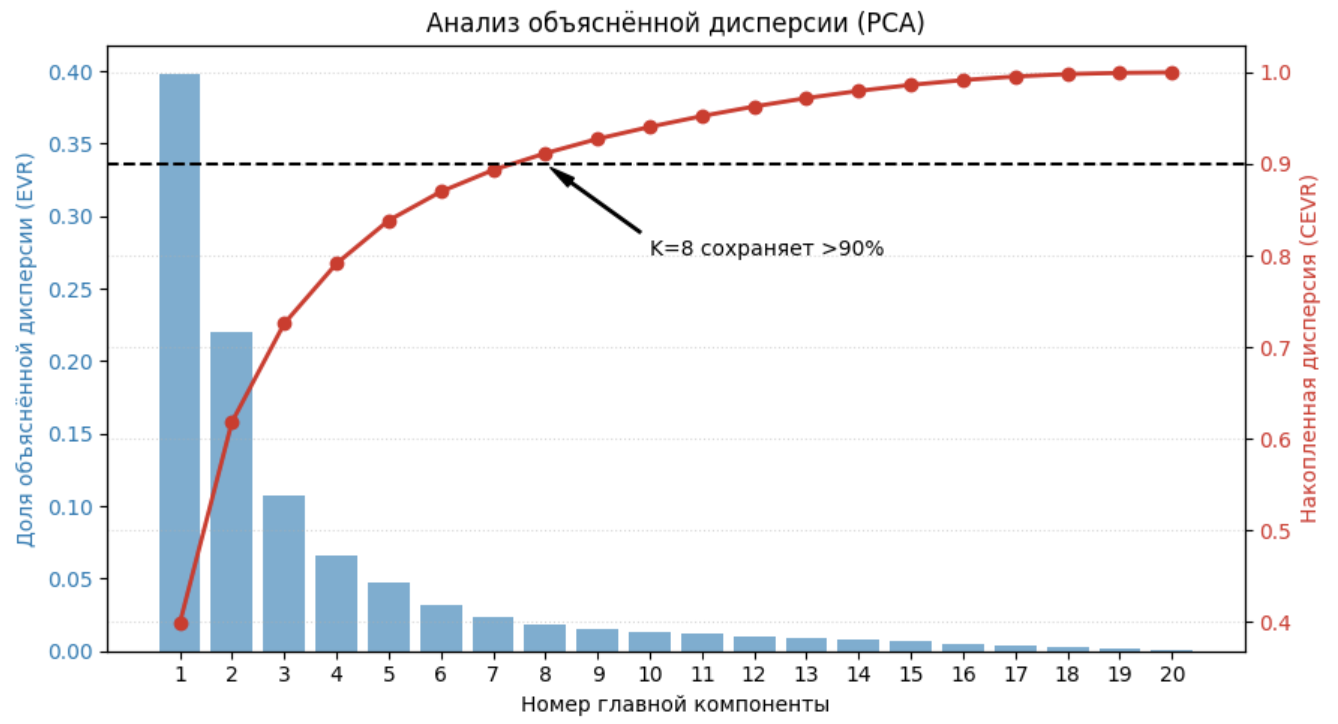
Для оценки информативности выбранных направлений и определения оптимального количества новых признаков используют два ключевых показателя: индивидуальную и накопленную доли объяснённой дисперсии.
Доля объяснённой дисперсии
Доля объяснённой дисперсии (Explained Variance Ratio, EVR) для конкретной -й компоненты показывает, какую часть суммарного разброса данных описывает именно это направление:
На практике строят график зависимости доли объяснённой дисперсии от номера компоненты, по которому подбирают, какое число главных компонент использовать. Для этого отбрасываются все главные компоненты, у которых доля объяснённой дисперсии оказалась ниже порога.
Накопленная доля объяснённой дисперсии
Накопленная доля объяснённой дисперсии (Cumulative Explained Variance Ratio, CEVR) характеризует суммарную информативность первых выбранных главных компонент:
Данная величина монотонно возрастает с увеличением и достигает 1 (или 100%), когда число компонент становится равным исходной размерности признакового пространства .
Эта величина также используется для подбора числа главных компонент: задают порог (90%, 95% или 99%), а далее выбирают минимальное число первых главных компонент, которые сохраняют заданную долю объяснённой дисперсии.
В последующих главах будут
-
аналитически выведены главные компоненты;
-
доказаны свойства проекций на главные компоненты;
-
пока�зана глобальная оптимальность первых главных компонент.
Поскольку данные описываются конечной выборкой объектов , то операции математического ожидания и дисперсии в этих главах следует понимать в конечном пространстве исходов этой выборки, что соответствует операциям выборочного среднего и выборочной дисперсии.