Отступ классификации
Введение
В регрессии (когда прогнозируем вещественное число) есть понятие величины ошибки, характеризующей степень того, насколько мы ошиблись в прогнозе:
Соответственно, мы определяем функцию потерь от этой ошибки, характеризующую штраф за то или иное отклонение:
| задача | название | формула |
|---|---|---|
| регрессия | квадрат ошибки (squared error) | |
| регрессия | модуль ошибки (absolute error) | |
| регрессия | -нечувствительная, |
Проинтерпретируйте -нечувствительные потери.
-нечувствительные потери штрафуют отклонение пропорционально ве�личине отклонения за вычетом и вообще не штрафуют, если отклонение оказалось по абсолютной величине меньше . Это полезно в приложениях, где существует некоторый допустимый уровень ошибки, таких как прогноз погоды для бытовых нужд, когда разница в градус несущественна.
Но как измерять степень рассогласованности классификационного прогноза с истинным значением? Можно смотреть на индикатор ошиб�ки , однако эта величина принимает всего два дискретных значения: 0 для верного и 1 - для неверного прогноза! Индикатор не позволяет понять, насколько уверенно модель пыталась предсказать правильный отклик! Для этого используется понятие отступа (margin).
Отступ для многоклассовой классификации
Отступ (margin) - непрерывная величина, измеряющая качество классификации �по формуле:
где - рейтинг верного класса, а - максимальный рейтинг среди всех неверных.
Отступ по смыс�лу измеряет, насколько модель уверенно назначала верный класс по сравнению со всеми неверными. Чем отступ выше, тем модель была более уверена в правильном прогнозе. Если , то модель делает верный прогноз, а если , то неверный.
Если применить модель ко всем объектам обучающей выборки, посчитать на них отступ и отсортировать по нему, то получим примерно такой график:
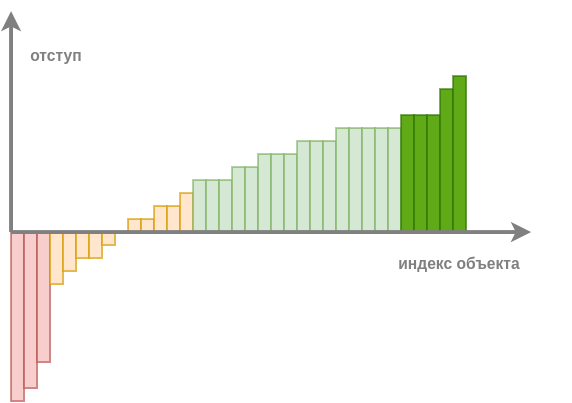
По величине отступа объекты делятся на следующие категории:
-
Надежно классифицированные объекты (обозначены светло-зелёным): отступ положительный и заметно больше нуля. При хорошей настройке модели большинство объектов будут принадлежать этой категории.
-
Объекты-эталоны (обозначены насыщенным зелёным): отступ положительный и большой. Объекты, лежащие в глубине своего класса и описывающие характерных представителей своего класса.
-
Пограничные объекты (обозначены оранжевым): отступ несильно отличает�ся от нуля, объекты лежат на границе классов, и на таких объектах обычно достигается максимальное число ошибок.
-
Объекты-выбросы (обозначены красным): отступ отрицательный и большой по абсолютной величине. Объекты лежат в глубине чужого класса. На них модель уверена, что класс один, хотя на самом деле он совсем другой.
Для повышения точности настройки модели полезно отфильтровать объекты-выбросы, чтобы они не мешали её настройке.
При этом, если нужно сократить размер обучающей выборки для повышения эффективности обучения, то делать это можно взяв эталонные объекты (определяющие расположения классов) и пограничные (несущие более детальную информацию о границах между ними), добавляя в первую очередь те пограничные объекты, на которых отступ меньше, но которые всё ещё не являются выбросами. Уменьшение размера выборки известно в литературе как отбор прототипов (prototype selection). О более продвинутых подходах можно прочитать в [1].
Информацию об отступах объектов можно использовать и для более эффективного порядка обхода объектов в численных методах оптимизации модели методом стохастического градиентного спуска вместо выбора случайных групп объектов.
Отступ для бинарной классификации
В случае бинарной классификации формула для отступа упрощается:
где, как и раньше, определяет относительную дискриминантную функцию.