Метод стохастического градиентного спуска
Идея метода
Вспомним, что функция потерь в машинном обучении представляет собой эмпирический риск, то есть средние потери по объектам обучающей выборки:
Рассмотрим детал�ьнее метод градиентного спуска с учётом вида функции потерь:
инициализируем случайно
пока не выполнено условие остановки:
Получается, что на каждом шаге алгоритма необходимо вычислять производные функции потерь на всех объектах обучающей выборки, которых может быть очень много!
Это приводит к медленной работе метода. При этом, поскольку алгоритм состоит из многих итераций с малым шагом , нам совсем не обязательно вычислять точное значение градиента , а достаточно сдвигаться лишь примерно в сторону уменьшения функции.
Идея метода стохастического градиентного спуска (stochastic gradient descent, SGD) заключается в использовании быстро вычислимой аппроксимации эмпирического риска для расчета градиента. Для этого используется приближение средними потерями на случайных объектах:
где - индексы случайных объектов обучающей выборки, называемых минибатчом (minibatch). Используя эту аппроксимацию, получим метод стохастического градиентного спуска:
ин�ициализируем настраиваемые веса случайно
пока не выполнено условие остановки:
случайно выбрать объектов из
Как видим, одна итерация стохастического градиентного спуска выполняется за операций, а не за , как в обычном методе градиентного спуска, причём мы выбираем сами, и он берётся намного меньше !
Поскольку по каждой итерации метода минибатч сэмплируется случайно, то, при достаточном числе итераций, алгоритм всё равно обойдет все объекты выборки.
На практике объекты обучающей выборки переставляются в случайном порядке, а затем извлекаются последовательно по штук за раз. Однократный проход по всем объектам обучающей выборки называют эпохой (epoch).
В режиме онлайн-обучения (online learning [1]) обучающие объекты поступают последовательно, а целевая зависимость часто динамически меняется со временем. Так происходит, например, при прогнозе цен на акции на бирже. В подобных сценариях вместо случайного сэмплирования объектов по всей истории наблюдений чаще сэмплируют недавние, более свежие наблюдения, лучше отражающие текущую зависимость в данных.
Выбор K
Если велико, а объекты содержат повторяющуюся информацию, то точность аппроксимации будет высокой при более быстрой сходимости по сравнению с методом градиентного спуска.
Интересно, что метод будет сходиться даже при . Конечно, оценка эмпирического риска всего по одному объекту будет очень грубой. Однако, поскольку эта оценка является несмещённой (за счёт случайного выбора объекта), метод всё равно будет сходиться, надо лишь использовать более малый шаг обучения . Тогда за увеличенное количество итераций мы сможем обойти существенную часть объектов выборки и в итоге сместить веса в правильную сторону.
На практике выбирают таким, чтобы минибатч помещался в память и векторные операции, связанные с его обработкой, производились за один такт параллельных вычислений устройства.
Сходимость
Для сходимости функция потерь должна быть непрерывно-дифференцируемой, выпуклой в окрестности оптимума и удовлетворять условию Липшица (иметь ограниченную производную [2]). Детальнее об условиях сходимости можно прочитать в учебнике ШАД [3]. Важным отличием условий сходимости стохастического градиентного спуска является то, что шаг сходимости должен быть не константой , а последовательностью , стремящейся к нулю в окрестности оптимума.
Действительно, при постоянном шаге, из-за того, что мы сдвигаемся не на точный градиент, а на его грубую аппроксимацию, даже дойдя до оптимума, метод будет совершать случайное блуждание в его окрестности. Для сходимости нужно постепенно уменьшать шаг, как показано ниже справа:
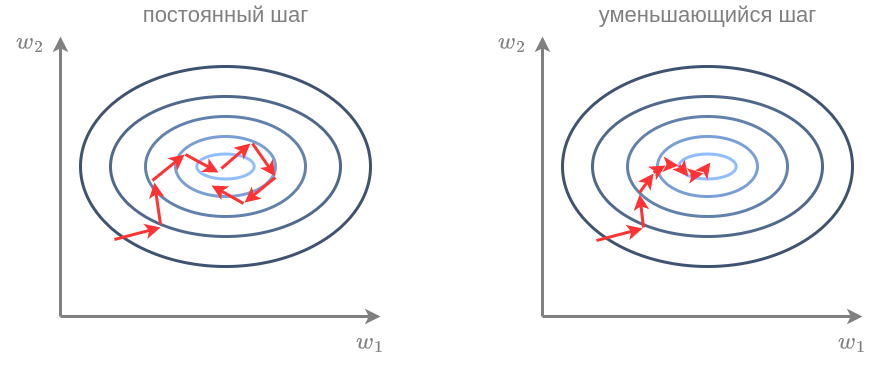
Формально метод сходится, если шаг удовлетворяет следующим двум условиям:
Например, этому условию удовлетворяет последовательность
На практике шаг часто берут небольшой константой, а потом её уменьшают, когда функция потерь перестаёт устойчиво уменьшаться, после чего продолжают обучение с уменьшенным шагом. Так делают несколько раз, и в библиотеках оптимизации, такой как PyTorch, такая стратегия уже реализована [4].
Далее в учебнике будет рассмотрено повышение скорости и устойчивости метода стохастического спуска за счёт внесения инерции, а также метод Ньютона оптимизации второго порядка. Также во второй части учебника по глубокому обучению будут описаны специализированные методы оптимизации для настройки нейросетей.
Вы также можете прочитать про метод градиентного и стохастического градиентного спуска у викиконспектах ИТМО [5] и учебнике ШАД [6]. В статье [7] детально разбираются различные алгоритмы оптимизации и анализируются их преимущества и недостатки.