Свёртка для последовательностей
Операция свёртки
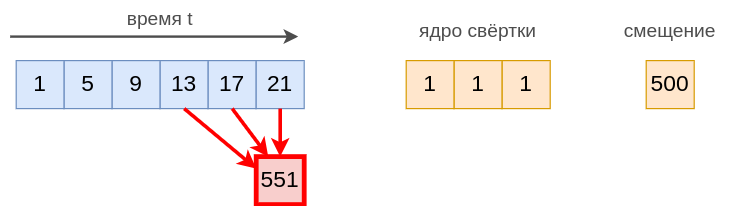
Пусть - обрабатываемая последовательность числовых значений.
Например, это может быть последовательность температур прибора, снимаемых каждые 10 секунд.
Свёртка (convolution) - это линейная операция, обладающая параметрами:
-
- ядро свёртки ( convolution kernel), обычно имеющая нечётный размеру (но может быть и чётным),
-
смещение .
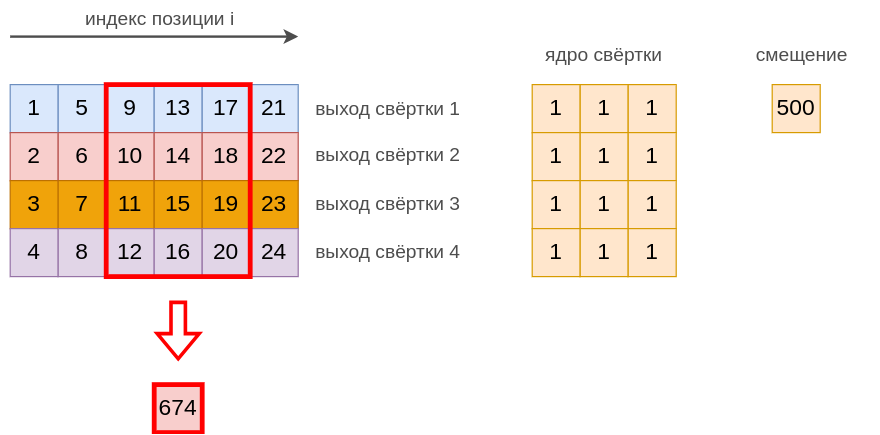
Выходом операции свёртки будет последовательность с элементами, считаемыми по формуле
Таким образом, свёртка генерирует последовательность, каждый элемент которой получается за счёт одного и того же линейного преобразования с параметрами.
Рассмотрим пример вычисления свёртки для следующих данных:

Тогда выходной ряд будет строиться следующим образом:
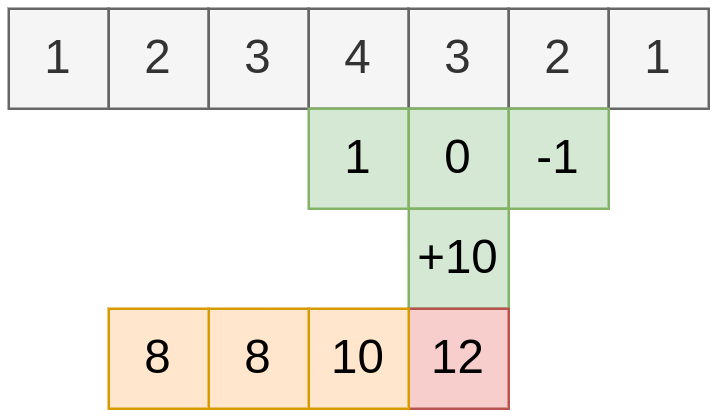
Примеры свёрток
Рассмотрим частные виды свёрток. Во всех примерах смещение равно нулю.
-
отвечает равномерному усреднению, сглаживает временной ряд.
-
- неравномерное усреднение, сглаживающее временной ряд, когда у центральных элементов вклад больше.
-
вычисляет разностную производную , то есть скорость изменения наблюдаемой величины.
-
вычисляет разностную вторую производную , то есть скорость изменения скорости наблюдаемой величины.
В ранних работах параметры свёрток подбирались вручную. Но если есть обучающая выборка, то эффективнее будет работать свёртка с автоматически настраиваемыми параметрами ядра и смещения - так операция будет лучше соответствовать данным и решаемой задаче.
Свойства свёртки
Свёртка извлекает один и тот же линейный признак, причём локально в каждой позиции. Это обеспечивает свойство эквивариантности к сдвигу (translation equivariance).
Сравнение свёртки с полносвязным слоем многослойного персептрона приведено ниже справа и слева соответственно (без смещений):
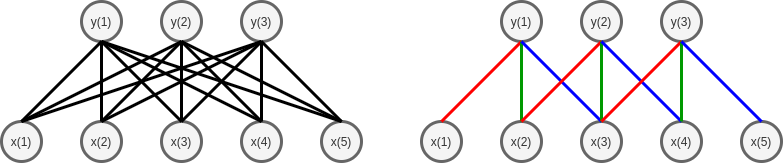
Как видим, свёртка предполагает существенно меньшее количество связей (sparse connections), что ускоряет вычисление и требует меньше параметров для обучения.
Дополнительное уменьшение параметров обеспечивается общностью весов (parameter sharing). На рисунке справа одинаковые веса обозначены одним цветом.
Свёртку можно применять к входным данным разной длины, причем число оцениваемых параметров будет одним и тем же - .
На многопроцессорных вычислительных устройствах, таких как видеокарта, вычисления производя�тся не последовательно один за другим, а параллельно, поэтому свёртка, вычисляемая независимо для разных позиций, считается очень быстро.
Также стоит обратить внимание, что выходная последовательность получается короче на , чем входная, поскольку ядро свёртки упирается в начало и конец входной временной последовательности.
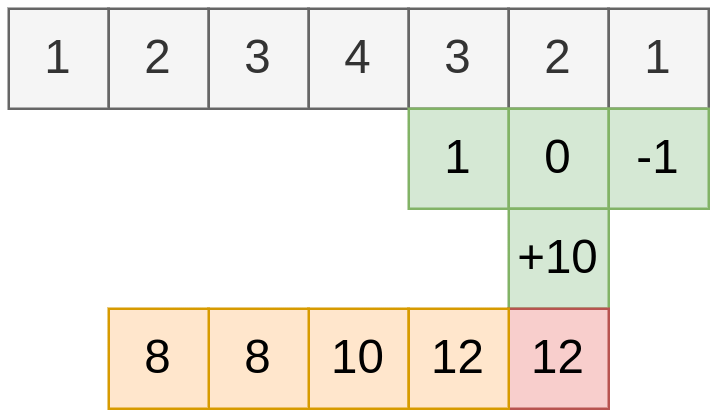
Обработка динамического временного ряда
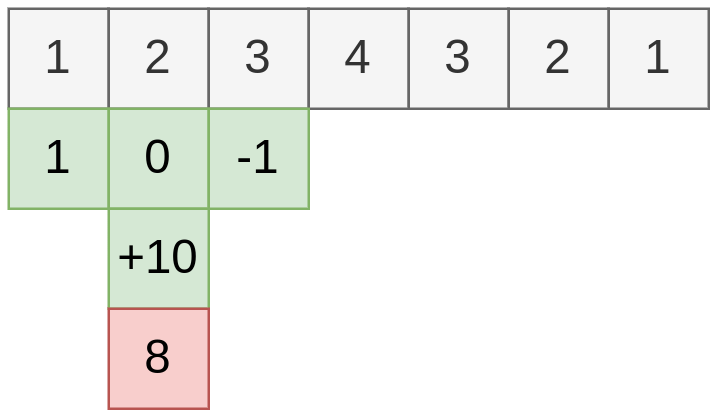
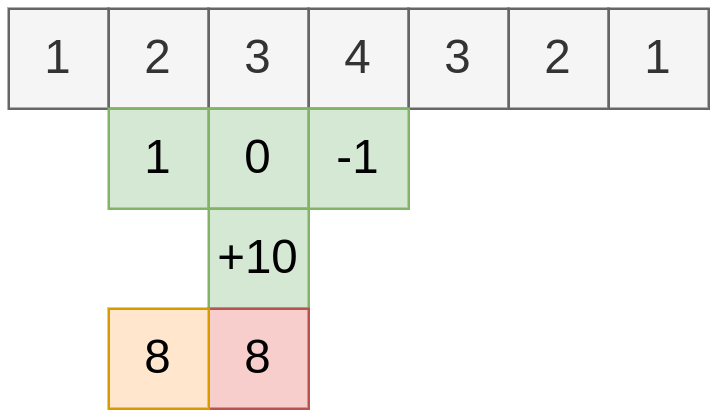
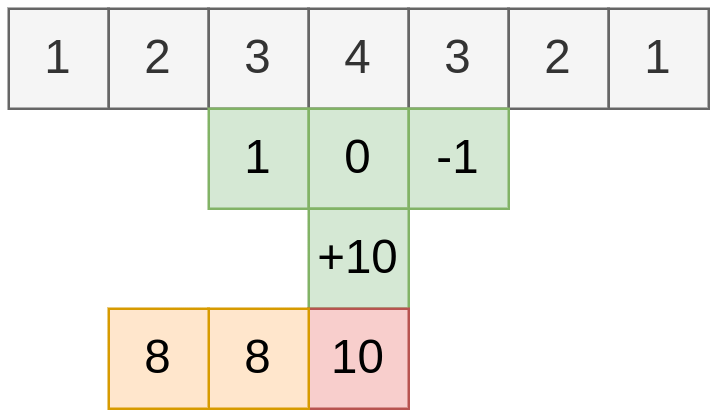
Обработка динамического временного ряда специфична тем, что наблюдения поступают последовательно, а будущие наблюдения ещё неизвестны, когда нужно формировать выход . Для такого рода данных свёртке разрешается использовать лишь последние располагаемые наблюдений:
а у самой свёртки остаются только параметров и . Пример действия такой свёртки показан ниже:
Такая свёртка может использоваться для прогнозирования будущих значений временного ряда.
Извлечение сложных нелинейных признаков
Наслаивая свёртки друг на друга, можно извлекать более сложные признаки с расширенной областью видимости (receptive field).
Ниже красным цветом показано, как результаты от более поздних свёрток зависят от более широкой окрестности значений входных данных:

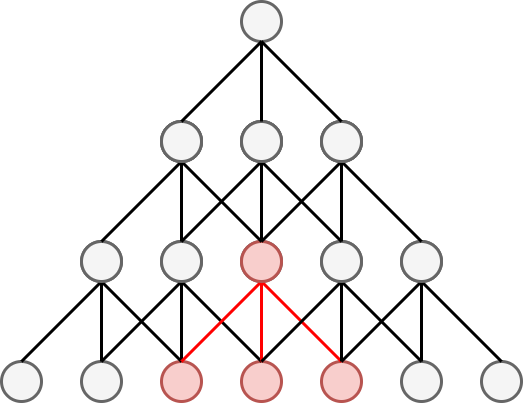
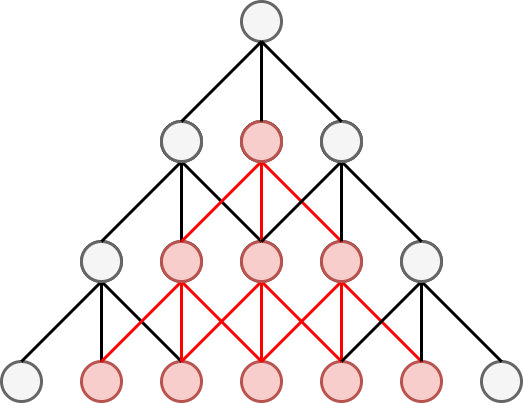
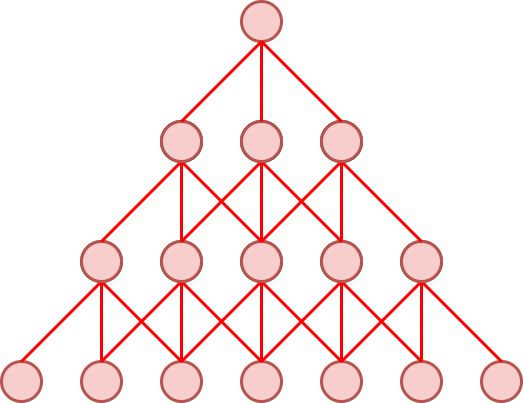
На каждом слое действует свёртка со своими индивидуальными параметрами.
Чтобы извлекаемые признаки получались нелинейными, после каждой свёртки применяют нелинейную функцию активации (иначе суперпозиция линейных функций снова даст линейную функцию!).
Суперпозиция свёрток с операциями нелинейности приводит к иерархичности признаковых представлений входной последовательности - более высокие слои �будут извлекать более сложные признаки, зависящие от более широкой окрестности данных.
Чтобы извлечь более разнообразные признаки, на каждом слое применяют не одну, а сразу несколько свёрток (каждая - со своими параметрами):
Тогда каждая свёртка следующего слоя будет определяться как локальная линейная комбинация результатов всех свёрток предыдущего слоя, и будет выполнять уже двумерную операцию:
Графически это проиллюстрировано ниже: