Функции активации
Рассмотрим популярные функции активации , использующиеся в нейросетях.
Тождественная функция активации (identity)
Эта активация используется в выходном слое, чтобы моделировать регрессионный выход. В скрытых слоях почти не используется (кроме случаев регуляризации), так как суперпозиция линейных функций всегда приводит к линейной функции.
Сигмоидная функция активации (sigmoid)
Принимает значения и используется только в выходном слое нейронной сети
-
для решения задачи бинарной классификации, предсказывая вероятность положительного класса ;
-
при прогнозировании неотрицательных значений из заданного отрезка; например, интенсивность пикселя принадлежит отрезку и её можно моделировать выходом .
В скрытых слоях сигмоида не используется, поскольку за пределами интервала она выходит на горизонтальные асимптоты 0 и +1, почти не меняясь, в результате чего её градиент близок к нулю. Поскольку нейросети оптимизируются численными методами, использующими градиент, малые значения производной нежелательны, поскольку приводят к слишком медленной настройке сети.
Гиперболический тангенс (tangh)
С точностью до линейного сжатия и сдвига активация гиперболического тангенса совпадает с сигмоидной функцией активации, но, в отличие от неё, является нечётной функцией:
что даёт преимущество при инициализации и настройке нейросети за счёт того, что если признаки - случайные величины, центрированные вокруг нуля, то образованные от них активации также будут центрированными вокруг нуля, а также активации от активаций и так далее по всем слоям нейросети, то есть по ходу вычислений не будет происходить систематического смещения в положительную или отрицательную сторону, в отличие от сигмоиды.
Тем не менее, гиперболический тангенс используется в основном только в выходных регрессионных слоях, где есть ограничение на выход и снизу, и сверху, например, где нужно генерировать степень поворота руля , чтобы оптимально объехать препятствие.
В скрытых слоях эта активация практически не используется, поскольку обладает тем же недостатком, что и сигмоида: за пределами интервала выходит на горизонтальные асимптоты -1 и +1 и почти не изменяется, из-за чего градиент по активации становится близким к нулю, и сеть начинает слишком медленно настраиваться градиентными методами оптимизации.
Плавная функция знака (SoftSign)
SoftSign-активация идейно повторяет tangh-активацию, но имеет характер приближения к асимптотам +1 и -1 полиномиальный, а не экспоненциальный, вследствие чего на константные значения она выходит медленнее, что ускоряет сходимость при настройке сети. Также SoftSign-активация вычисляется быстрее, чем tangh. Тем не менее, за исключением выходных слоёв такая функция используется редко из-за того, что в скрытых слоях возникают горизонтальные асимптоты и малые градиенты.
Жёсткий гиперболический тангенс (hard tangh)
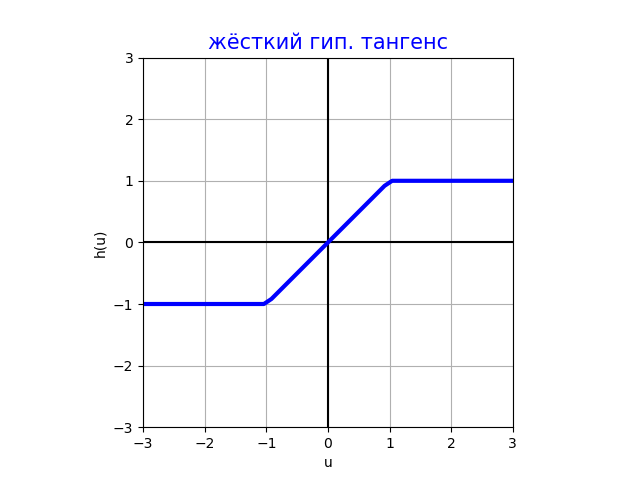
Используется так же, как и обычный гиперболический �тангенс, но гораздо быстрее вычисляется за счёт ещё более простых операций. Вычисление получается более точным и устойчивым, что актуально при использовании низкобитных представлений чисел (float16, int8) при построении компактных нейросетей для мобильных устройств.
SoftPlus
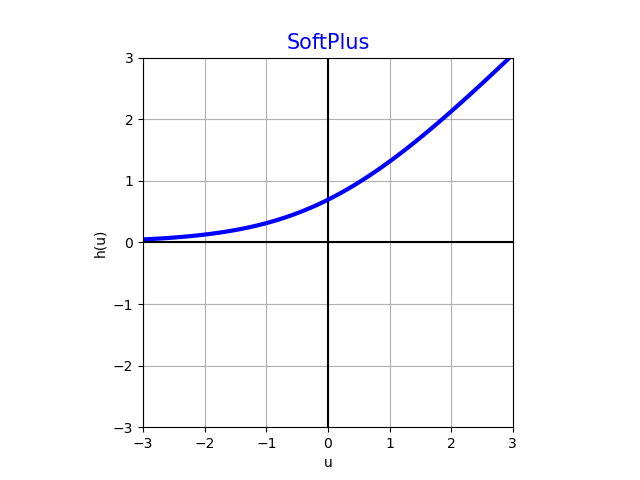
Имеет нетривиальный градиент уже на полуоси , за счёт чего используется в скрытых слоях. Также используется и в выходных слоях, когда предсказываем неотрицательный регрессионный отклик, который сверху не ограничен. Примеры подобных задач:
-
прогнозирование времени безотказной работы оборудования;
-
предсказание стоимости товара;
-
прог�ноз физических величин, которые всегда неотрицательны (интенсивность света, мощность, энергия и т.д.)
Rectified linear unit (ReLU)

Имеет нетривиальный градиент +1 на полуоси , за счёт чего используется как в скрытых слоях, так и в выходных слоях, где нужно предсказывать неотрицательный регрессионный отклик.
Идейно повторяя SoftPlus-активацию, вычисляется гораздо быстрее и устойчивее при низкобитных представлениях чисел в облегчённых нейросетевых моделях. За счёт этих свойств ReLU - одна из самых популярных функций активации!
ReLU обладает тем недостатком, что зануляет отрицательные значения, что приводит к холостым вычислениям для отрицательных аргументов (dead neuron).
Формально, в нуле градиент этой функции активации не определён. Однако это не приводит к проблемам на практике, так как при случайной инициализации весов и случайных признаках значение, в точности равное нулю, в общем случае не реализуется.
Leaky rectified linear unit (Leaky ReLU)
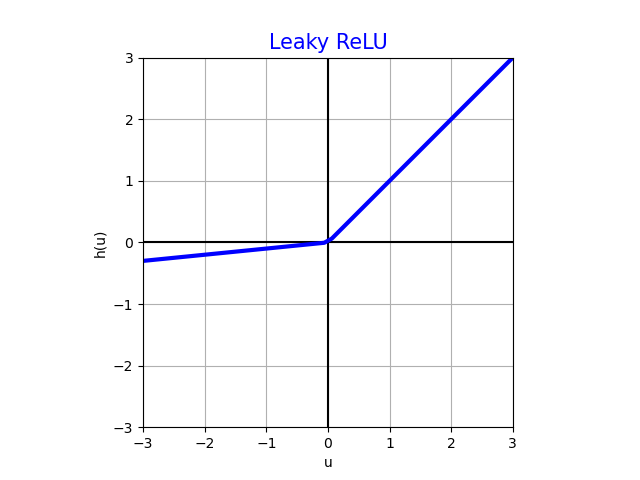
Активация Leaky ReLU обладает всеми достоинствами ReLU-активации, но кроме того выдаёт ненулевые значения и для отрицательных аргументов, за счёт чего не вырождается в ноль и не приводит к лишним вычислениям вхолостую. Поэтому эта функция рекомендуется к использованию как наилучший базовый вариант для скрытых слоёв!
В классическом LeakyReLU , хотя можно использовать и другие значения и даже настраивать его как параметр вместе с остальными параметрами нейросети.
Мы рассмотрели основные функции активации, использующиеся в нейросетях. С расширенным списком функций активации вы можете ознакомиться в [1].