Сегментация объектов
При распозн�авании объектов на изображениях можно решать четыре основных типа задач:
-
классификация (classification, recognition);
-
семантическая сегментация (semantic segmentation);
-
детекция объектов (object detection);
-
сегментация объектов или инстанс-сегментация (instance segmentation).
Результат решения каждой задачи показан ниже [1]:
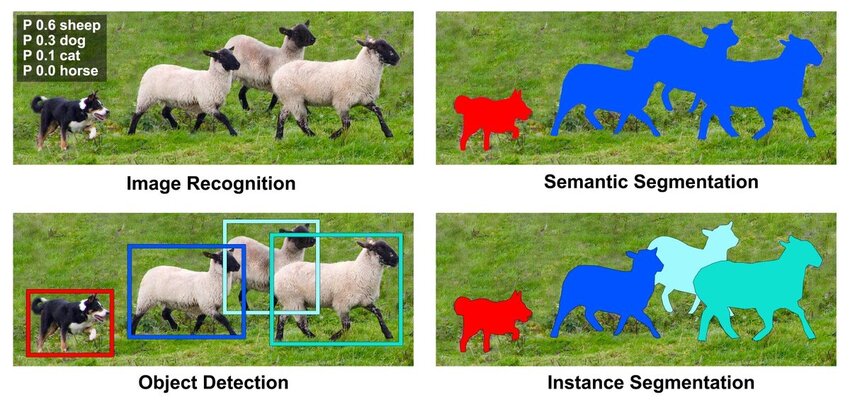
При классификации изображений выходом являются вероятности присутствия объектов разных классов на изображении в целом.
В детекции объектов каждый объект интересующих классов выделяется прямоугольной рамкой с меткой класса, которому объект принадлежит.
В семантической сегментации каждый пиксель помечается тем или иным классом, в зависимости от того, объект какого типа он покрывает. При этом, если присутствует несколько представителей одного класса, то метки пикселей их различать не будут.
Например, на иллюстрации выше присутствует несколько овец, но все содержащие их пиксели помечены одним цветом.
В сегментации объектов (instance segmentation), как и в семантической сегментации, каждый пиксель изображения помечается своим классом, при этом различаются выделения различных представителей одного класса, как показано на иллюстрации, на которой каждая овца была помечена своим цветом.
Поэтому сегментация объектов представляет собой усложнённый вариант детекции объектов, когда каждый объект выделяется не рамкой, а маской произвольной формы.
Технически сегментация объектов решается надстройкой над архитектурой детекции объектов, в которой, помимо выделения рамки, присутствует блок, прогнозирующий маску, попиксельно выделяющую каждый объект в рамке.
Как и в случае детекции объектов, модели сегментации объектов бывают
-
одностадийные (one-stage instance segmentation), которые сразу предсказывают результат;
-
двухстадийные (two-stage instance segmentation), в которых сначала предсказываются регионы интереса (region proposals, regions of interest, ROI), в которых могут потенциально находиться детектируемые объекты. Далее на втором шаге для каждого из региона производится классификация типа объекта, уточнение координат рамки и выделение маски объекта.
Далее будут разобраны популярная архитектура двухстадийной сегментации Mask R-CNN и архитектура одностадийной сегментации YOLACT.