YOLACT
Модель YOLACT - популярный одностадийны�й метод сегментации объектов (instance segmentation). Он работает менее точно, чем Mask R-CNN, но зато существенно быстрее, поскольку в нём не производится предварительный этап генерации регионов интереса (regions of interest, RoI).
Архитектура сети показана ниже [1]:
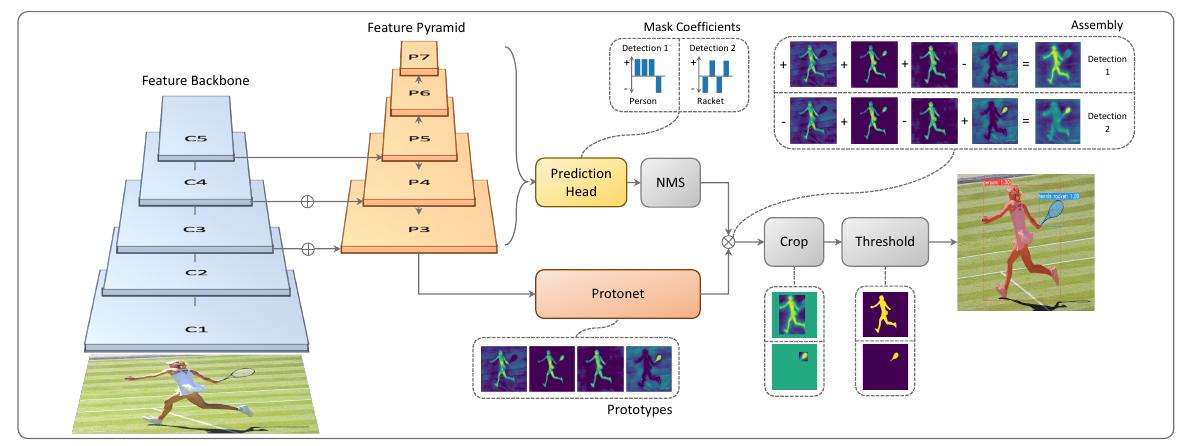
Вначале из изображения извлекается промежуточное признаковое представление с использованием архитектуры Feature Pyramid Network (FPN), позволяющей получить семантически сложные признаки в высоком разрешении.
Аналогично модели RetinaNet, на каждом уровне декодировщика FPN (и для каждой пространственной позиции) работает одинаковый детектор. Поскольку каждый уровень имеет своё разрешение, это позволяет детектировать как большие, так и малые объекты. Детектор, в свою очередь, выдаёт для каждой из шаблонных выделяющих рамок ( штук):
-
4 регрессионных ответа (коррекции координат выделяющей рамки);
-
вероятностей классов.
Дополнительно детектор в YOLACT предсказывает смешивающих коэффициентов (mask coefficients), как показано на нужней схеме справа (слева для сравнения показан детектор в RetinaNet) [1]:
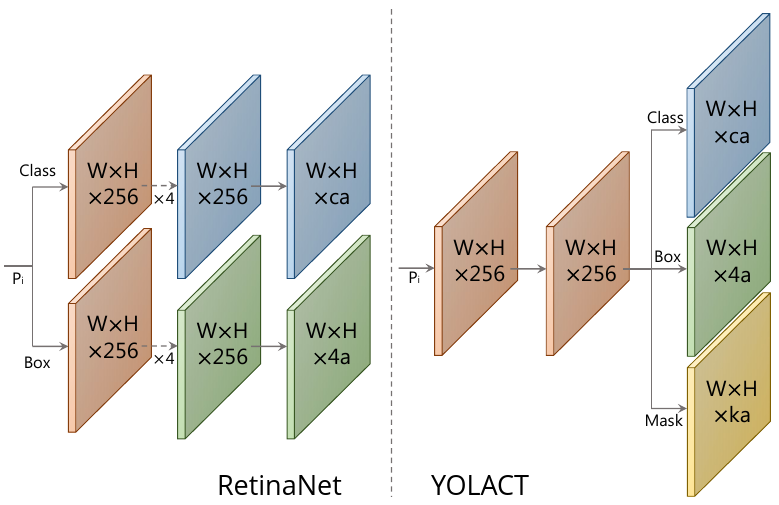
Таким образом, для каждого уровня FPN-декодировщика и для каждой пространственной позиции предсказывается значений.
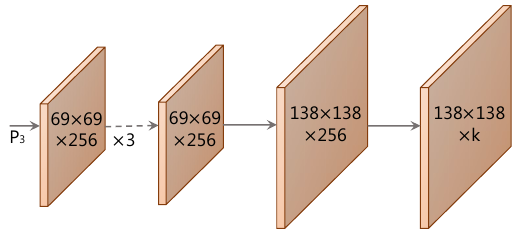
Также к самому нижнему ярусу FPN-декодировщика (обладающего максимальным пространственным разрешением) применяется сеть, определяющая масок-прототипов (prototypes), из линейной комбинации которых будут составляться итоговые маски объектов. Примеры масок для шести прототипов приведены ниже [1]:

Вычислительная ветка для их выделения состояла из операций повышения разрешения и свёрток [1]:
Каждому прогнозу детектора на каждой пространственной позиции ставилась в соответствие маска, получаемая как линейная комбинация масок-прототипов, взвешенных с полученными ранее смешивающими коэффициентами в соответствующей позиции (шаг assembly на первом рисунке), пос�ле чего полученная маска обрезалась выделяющей рамкой, полученной из задачи регрессии детектора (шаг crop на первом рисунке).
YOLACT расшифровывается как You Only Look At CoefficienTs, поскольку маска выделений строится как линейная комбинация масок-прототипов с предсказанными коэффициентами.
Примеры итоговых результатов работы YOLACT приведены ниже [1]:
