Двухстадийные детекторы
Ранее рассмотренные в учебнике методы детекции объектов являются одностадийными (one-stage detectors), поскольку они на вход принимают изображение, а на выходе сразу выдают рамки с сопоставленными им классами обнаруженных объектов.
Двухстадийные детекторы (two-stage detectors) решают задачу детекции за два этапа:
-
на первом шаге извлекаются регионы-кандидаты (region proposals, regions of interest, ROI);
-
на втором шаге извлечённые регионы-кандидаты относятся к тому или иному классу и уточняется их расположение.
Из-за двух этапов генерации такие методы работают медленнее, чем одностадийные, но при тщательной настройке могут обеспечить более высокую точность.
Исторически первыми нейросетевыми детекторами были именно двухстадийные детекторы. Рассмотрим самую известную модель этого типа - детектор Faster R-CNN.
Faster R-CNN
Детекция объектов на изображении моделью Faster R-CNN [1] состоит из следующих шагов:
-
Генерация регионов-кандидатов (region proposals) с помощью специальной RPN сети (region proposal network).
-
Подавление немаксимумов для выделения минимально достаточного набора рамок-кандидатов, покрывающих все потенциальные объекты.
-
Отбор топ-K самых высокорейтинговых регионов-кандидатов.
-
Классификация и уточнение выделяющей рамки для каждого объекта.
-
Итоговое подавление немаксимумов.
Последние два шага повторяют модель Fast R-CNN, описанную далее.
Схема Faster R-CNN представлена ниже [2]:
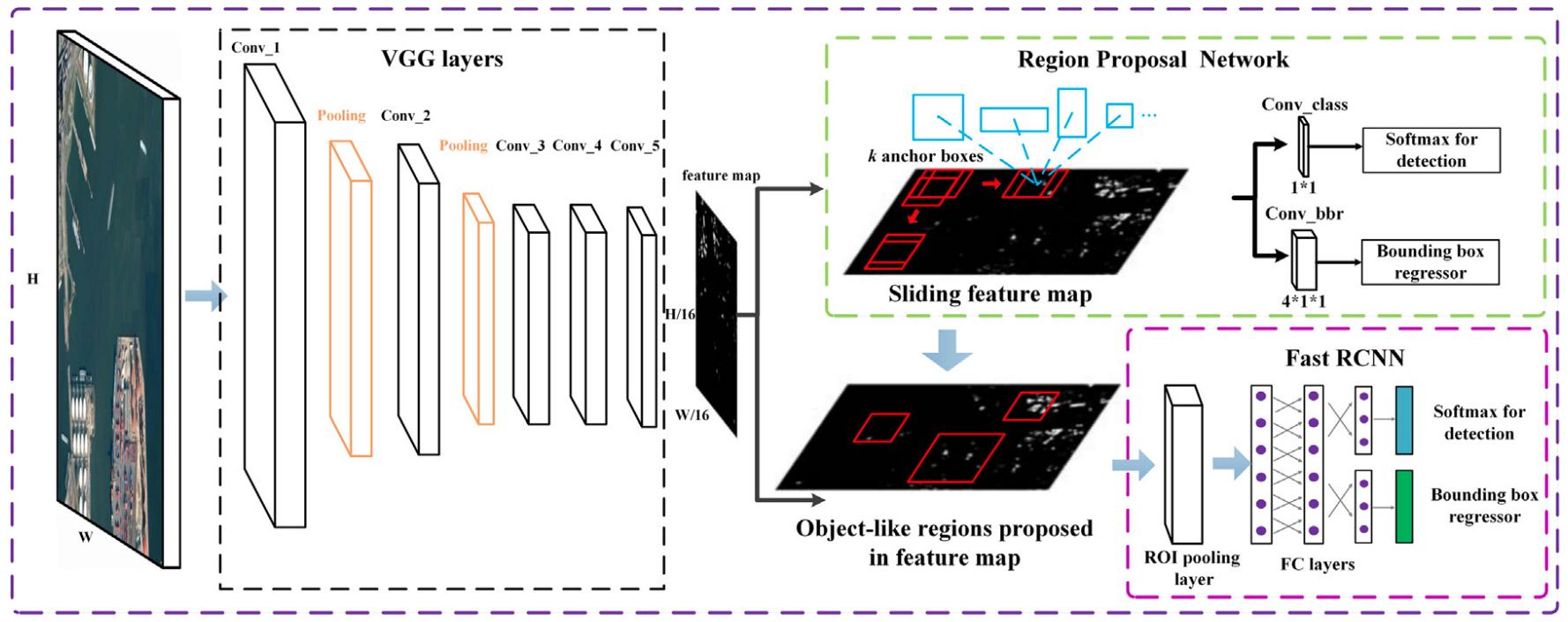
Вначале изображение обрабатывается первыми слоями свёрточной сети, предобученной решать задачу классификации, для извлечения признакового описания изображения. Далее к нему применяется RPN-сеть (region proposal network), предсказывающая регионы интереса (regions of interest, ROI), представляющие собой рамки, в которых могут находиться все потенциально присутствующие на изображении объекты.
RPN-сеть работает следующим образом:
-
К полученному признаковому описанию скользящим окном 3x3 применяются свёртки, выдающие 256 признаков.
-
К 256-мерному вектору в каждой позиции применяется полносвязный слой, предсказывающий для каждой из шаблонных рамок (anchor box), центрированных в текущей позиции, следующие выходы:
-
2 классификационных выхода (вероятность присутствия и отсутствия объекта);
-
4 регрессионных выхода (изменение координат соответствующей шаблонной рамки по координатам центра, ширине и высоте).
-
Указанные шаги графически показаны ниже [1]:
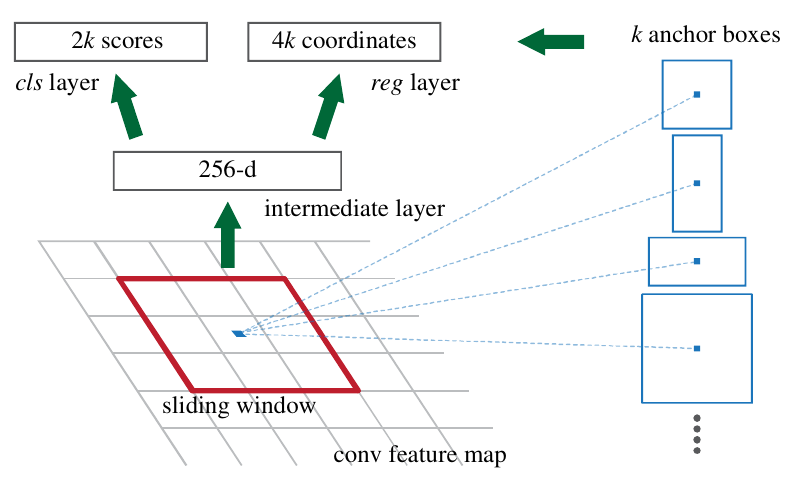
Технически шаг 1 - это один слой из 3x3 свёрток с 256 выходами, а шаг 2 - слой из свёрток 1x1. Таким образом, всю RPN-сеть можно описать двумя обычными свёрточными слоями.
К полученным регионам-кандидатам применяется подавление немаксимумов и отбор топ-K самых высокорейтинговых регионов (с максимальными вероятностями присутствия объекта), после чего на извлечённых регионах уже работает сеть Fast R-CNN, производящая окончательную детекцию.
Модель Faster R-CNN была предложена в 2015 году и впоследствии обгонялась и по скорости работы, и по точности более эффективными одностадийными детекторами. Однако точность Faster R-CNN можно повысить, используя более продвинутые сети
-
для извлечения промежуточного представления,
-
генерации регионов-кандидатов,
-
классификатора и локализатора.
Продвинутые версии этой модели продолжают составлять конкуренцию по точности одностадийным детекторам.
Fast R-CNN
Модель Fast R-CNN [3] детектирует объекты по изображению, на котором уже выделены регионы-кандидаты. В оригинальной версии метода для этого используются регионы-кандидаты, выделяемые эвристическим методом selective search [4].
Алгоритм selective search
Алгоритм selective search использует не нейросети, а алгоритм классического компьютерного зрения. Вначале он разбивает изображение на области, в качестве которых выступают суперпиксели (superpixels), то есть небольшие области соседних пикселей, примерно похожих по цвету. На основе первоначальных областей алгоритм начинает их итеративное объединение жадным способом, объединяя в первую очередь соседние и самые похожие области. Объединение происходит по следующим критериям сходства:
-
Текстура: схожесть гистограмм градиентов цветов соседних областей.
-
Размер: относительная площадь двух областей (предпочтение отдается объединению небольших областей).
-
Общность: насколько области геометрически соответствуют друг другу.
Процесс объединения областей продолжается, пока не останется всего одна область. Регионами-кандидатами выступают прямоугольники, обведённые вокруг каждой области, полученной в процессе работы алгоритма.
Модель Faster R-CNN отличается от Fast R-CNN только методом извлечения регионов-кандидатов. В Fast R-CNN для этого используется selective search, а в Faster R-CNN - нейронная RPN-сеть генерации регионов-кандидатов. Первый метод итеративный и не поддаётся параллелизации, а RPN-сеть генерации регионов-кандидатов состоит из двух свёрточных слоёв, которые можно быстро вычислить на видеокарте. Поэтому Faster R-CNN работает значительно быстрее, чем Fast R-CNN!
Как только регионы-кандидаты извлечены, работа двух методов не различается.
Обработка регионов-кандидатов в Fast R-CNN
Схема работы Fast R-CNN показана на рисунке [3]:
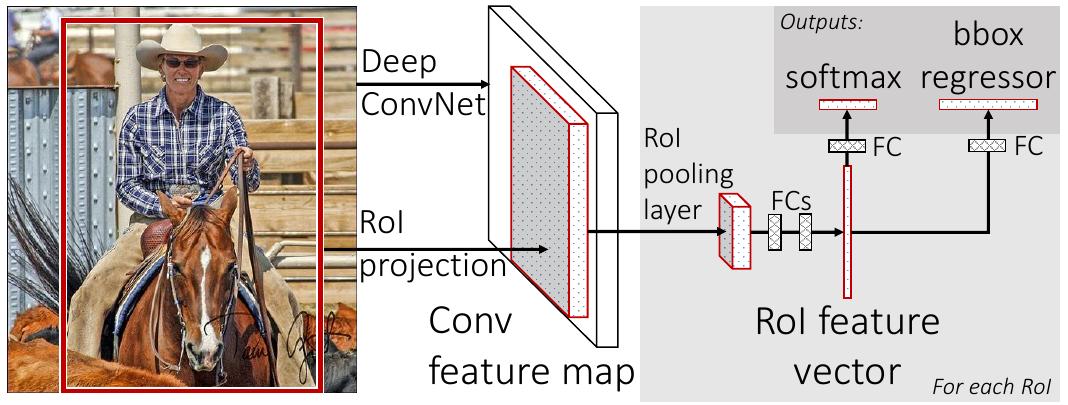
Изображение пропускается через свёрточный кодировщик (первые свёрточные слои сети, обученной решать задачу классификации), чтобы получить её промежуточное представление с каналами.
В Fast R-CNN извлечённые регионы-кандидаты перемасштабируются с размера исходного изображения под размер промежуточного представления (которое меньше). Модель же Faster R-CNN извлекает регионы-кандидаты с того же самого внутреннего представления, по которому производится итоговая детекция, поэтому ей перемасштабирование не требуется.
Далее каждый регион-кандидат обрабатывается независимо. Осуществляется перевод внутреннего представления, выделенного регионом-кандидатом, в эмбеддинг (вектор фиксированного размера ) за счёт пулинга региона интереса (region-of-interest pooling, ROI pooling). Этот пулинг накладывает на регион интереса сетку , а далее возвращает максимальные элементы из всех активаций, покрытых каждой ячейкой сетки. Делается это независимо для каждого канала, потом результаты для всех каналов объединяются.
По сути, пулинг региона интереса производит пирамидальный пулинг, но только на одном слое пирамиды.
После представления региона интереса эмбеддингом, к нему применяются два полносвязных слоя. Первый переводит вход в вектор ещё более маленького размера, а второй, наоборот, расширяет - это позволяет сэкономить на числе связей. К результату применяется два независимых полносвязных слоя:
-
первый выдаёт вероятностей, соответствующих каждому из классов и фоновому классу (отсутствию объекта);
-
второй выдаёт выхода, трактуемые как уточнённые координаты первоначальной рамки региона-кандидата.
Настройка Fast R-CNN
Fast R-CNN, как и все нейросети, настраивается минибатчами. Каждый минибатч состоит из набора регионов интереса. Для ускоренной настройки используется иерархическое сэмплирование регионов:
-
Сэмплируется набор изображений.
-
Для каждого изображения сэмплируется набор регионов интереса.
Такая иерархическая генерация минибатча работает быстрее, чем случайный выбор изображения и региона, поскольку многие регионы будут оказываться на одном изображении, а следовательно для них промежуточное представление можно вычислить только один раз.
Регионы интереса сэмплировались сбалансированно по фоновому и целевым классам, для этого вычислялась мера IoU между истинными и предсказанными выделениями:
-
половина регионов бралась с , и от классификатора требовалось распознать верный класс;
-
другая половина бралась с , и от классификатора требовалось распознать, что класс является фоном.
Настройка сети производилась минимизацией суммы потерь классификации и локализации:
-
потери классификации измеряют, насколько корректно предсказан класс объекта, а математически представляют собой кросс-энтропийные потери;
-
потери локализации измеряют, насколько пространственно сочетается предсказанная рамка и рамка истинного выделения, и вычисляются лишь для тех рамок, на которых классификатор обнаружил не фоновый класс, а рамка существенно пересекается с истинной рамкой объекта.
В качестве потерь локализации бралась функция потерь Хубера (smooth L1 loss), как более устойчивая к выбросам. Если - истинная рамка, а - предсказанная, то локализующая регрессия училась предсказывать величины
Такие целевые переменные позволяют устойчивее предсказывать координаты угла рамки для рамок разных размеров и сильнее штрафуют недостаточное выделение объекта, чем избыточное.
В RPN-сети, предсказывающей регионы-кандидаты для модели Faster R-CNN, использовались точно такие же потери локализации.
Обучение Fast R-CNN велось для исходных изображений и их горизонтально отражённых версий, используя разный масштаб этих изображений, чтобы детектор учился выделять как большие, так и малые по размеру объекты.
Для повышения полноты (recall) обнаруживаемых объектов в Mask R-CNN во время применения предлагалось запускать метод несколько раз на изображении разных масштабов (более крупных и более мелких).
Это замедляет построение прогнозов, зато улучшает качество детекций для слишком больших и малых объектов.
Заметим, что этот приём применим не только к Fast R-CNN, но вообще к любым моделям детекции.
Историческая справка
Одним из первых нейросетевых детекторов была модель R-CNN [5]. Она работала очень медленно, поскольку каждый регион-кандидат обрабатывался отдельно и независимо свёрточным кодировщиком, а для того, чтобы зафиксировать выходной эмбеддинг, каждый регион-кандидат перемасштабирова�лся к единому размеру, что приводило к геометрическим искажениям и потере информации за счёт обрезки краёв.
Идея не пропускать каждый регион-кандидат через кодировщик, а пропустить через него сразу всё изображение, чтобы потом выделять нужные регионы-кандидаты на предпосчитанных картах признаков, была предложена в модели SPP-net [6]. Это существенно ускорило скорость обработки, поскольку не приводило к повторным перевычислениям одних и тех же признаков на пересекающихся рамках.
Также в SPP-net была впервые предложена идея кодировать признаковое описание региона-кандидата, используя пирамидальный пулинг.