Виды обучения
Рассмотрим специальные виды задач, решаемые в глубоком обучении.
Многозадачное обучение (multi-task learning, предложено в [1]): синхронная настройка одной или нескольких моделей решать одновременно несколько связанных по смыслу задач.
Мотивирована тем, что многие задачи схожи по смыслу, и умение решать одну помогает решать и другую.
Примеры:
-
детекция людей на фото и их одновременное распознавание;
-
в беспилотных автомобилях пешеходы, знаки остановки и другие препятствия могут обнаруживаться одновременно;
-
прогноз будущих цен сразу для нескольких акций.
Решается тремя способами.
-
Hard weight sharing. Настраивается одна модель, принимающей на вход данные для всех задач и выдающей прогнозы для всех задач одновременно. Преимущество обеспечивается тем, что обе задачи используют одинаковые признаки, которые лучше настраиваются используя информацию о всех задачах одновременно.

-
Common features. Модели решающие различные задачи различаются только последними слоями, опирающимися на общие извлечённые признаки.

-
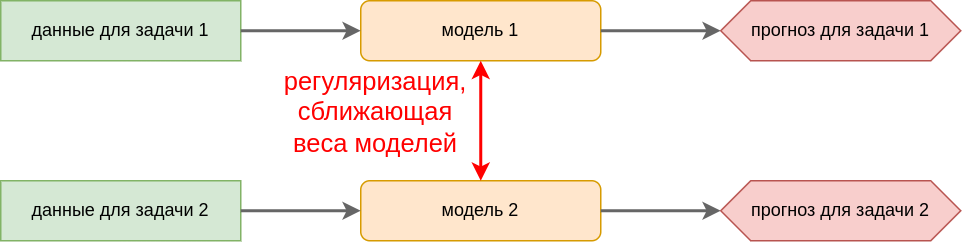
Soft weight sharing. Настраивается своя модель под каждую задачу. При этом при настройке весов моделей добавляется дополнительное требование, чтобы параметры (веса) разных моделей не сильно различались между собой. Математически это требование реализуется добавлением регуляризации на расхождение весов моделей в процессе их настройки.
Трансферное обучение (transfer learning) - процесс переноса знаний, полученных из решения одной задачи на решение другой родственной задачи. Возникает, когда для первой задачи есть много данных и настроенная хорошо зарекомендовавшая модель, но решить нужно несколько иную, хотя и похожую задачу.
Схема трансферного обучения приведена ниже:
![]()
Примеры:
-
Есть модель, хорошо классифицирующая машины. Хотим построить модель, классифицирующую грузовики.
-
Есть модель, хорошо переводящая с английского языка на французский. Хотим построить модель, переводящую с английского на монгольский.
-
Голосовой ассистент хорошо научился понимать голос Алисы. Хотим, чтобы он научился понимать голос Боба.
Последовательное обучение (continual learning) - обучение, когда обучающие примеры поступают постепенно, а не известны заранее. Это требует модификации процесса обучения нейросети таким образом, чтобы более новые данные, изменяя настраиваемую модель, не приводили к забыванию старых данных, на которые модель настраивалась ранее (эффект catastrophic forgetting). В задачах классификации бывают постановки, когда в процессе обучения появляются новые классы, которые тоже нужно учиться обрабатывать.
Например, в задаче автоматического вождения могут появляться новые модели машин на дороге, которые также нужно уметь объезжать.
Обучение по одному или нескольким прецедентам (one-shot learning, few shot learning) - технология быстрого дообучения модели по одну или нескольким примерам. Задача вдохновлена способностью человека распознавать объекты, увидев их всего один или пару раз, а не как традиционные машинные модели машинного и глубокого обучения, которым нужно приводить тысячи и десятки тысяч примеров объекта, чтобы они научились их распознавать. Эта задача решается специализированными нейросетевыми архитектурами.
Обучение без прецедентов (zero-shot learning) - умение модели построить прогноз для входов, которые она никогда не наблюдала во время обучения. Например, модель, классифицирующая животных, видела много лошадей, но никогда не видела в обучающих примерах зебру. Но если ей сообщить в текстовом виде, что зебра - это полосатая лошадь, то она сможет выделять и её. Решается специализированными архитектурами, способными обрабатывать дополнительные знания в текстовом виде.
Другим примером может служить задача стилизации изображений - перерисовка фотографии в стиле, задаваемым другим изображением (например, картиной Ван Гога). Обычные модели стилизации настраиваются, чтобы воспроизводить заданные стили из обучающей выборки и только их. Zero-shot модель стилизации способна обобщить знания о процессе перерисовки фотографий с известных стилей на новые, которыми заинтересуется пользователь.
Нейросетевой поиск архитектур (neural architecture search) - задача, в которой н�ужно подобрать оптимальную нейросетевую архитектуру для решения заданной задачи.
Автоматическое машинное обучение (AutoML) - задача, в которой нужно подобрать весь процесс подготовки данных, генерации признаков, выбора модели (не обязательно нейросетевой) и её гиперпараметров для решаемой задачи.
Мета-обучение (meta-learning, learning to learn [2]) - обобщение информации о различных задачах и оптимальных методах их решения, чтобы для новой задачи сразу выбрать один или несколько подходящих для неё методов.
Решается средствами машинного обучения, при этом
-
объектами выступают задачи, описанные в виде вектора признаков (тип задачи, число объектов, число признаков, доля числовых, бинарных и категориальных признаков, количество разреженных признаков и т.д.)
-
ответами выступают модели и их спецификации (архитектура, характер регуляризации), которые отработали лучше всего на этих данных.
Упрощение модели (model simplification) - требуется по точной, но сложной модели построить п�охожую по точности, но простую. Это полезно для использования модели на маломощном вычислителе, например, на мобильном телефоне или дроне. Также это полезно, чтобы повисить быстродействие сложной модели (например, при онлайн-работе с видеопотоками или большим числом запросов). Существуют разные подходы для решения этой задачи: дистилляция знаний, обрезка нейросетей, низкоранговые факторизации тензорных вычислений, квантизация нейросетей.
Распределённое обучение (distributed learning) - ускорение обучения моделей за счёт распределённых вычислений на разных устройствах.
Федеративное обучение (federated learning, ФО) - распределённое обучение, при котором вычислительные узлы не обмениваются информацией об обучающих объектах напрямую, а пересылают центральному серверу (централизованное ФО) или друг другу (децентрализованное ФО) более агрегированную и абстрактную информацию, такую как веса сети. Ниже приведена схема централизованного и децентрализованного ФО (источник):

В случае централизованного ФО схема работы следующая (источник):
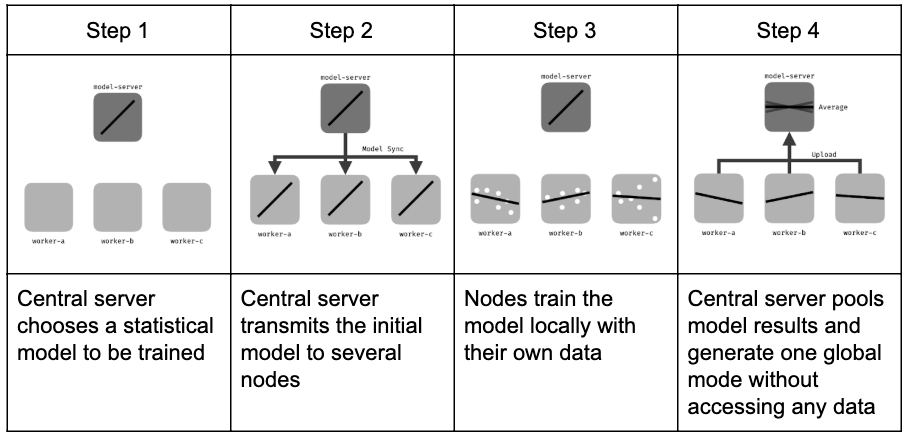
Федеративное обучение становится актуальным за счёт того, что решаемые задачи становятся все более сложными, чтобы решать их на одном вычислительном узле, при этом данные собираются с разных узлов, а по соображениям приватности обмениваться этими данными напрямую нельзя. Но узлы, собирающие данные, обладают достаточными вычислительными ресурсами, чтобы обработать эти данные локально. Например, в задаче голосового помощника по соображениям приватности может быть запрещено отсылать голосовые реплики пользователя стороннему серверу, поэтому распознавание голоса может настраиваться локально, ускоряя процесс обучения за счёт использования опыта голосовых ассистентов других пользователей.