Нормализация слоя
Помимо батч-нормализации, другим способом нормализации активаций сети для упрощения её настройки является нормализация слоя (layer normalization, [1]), сокращенно называемая LayerNorm.
Слой LayerNorm принимает на вход активации предыдущего слоя сети и их линейно перемасштабирует:
где - малая константа, призванная исключить деление на ноль, а параметры и вычисляются как выборочное среднее и стандартное отклонение по активациям всех нейронов слоя в рамках одного объекта:
Параметры и настраиваются вместе с остальными весами нейросети во время обучения сети (training) и остаются фиксированными во время её применения (inference).
Схематично работа LayerNorm представлена ниже:
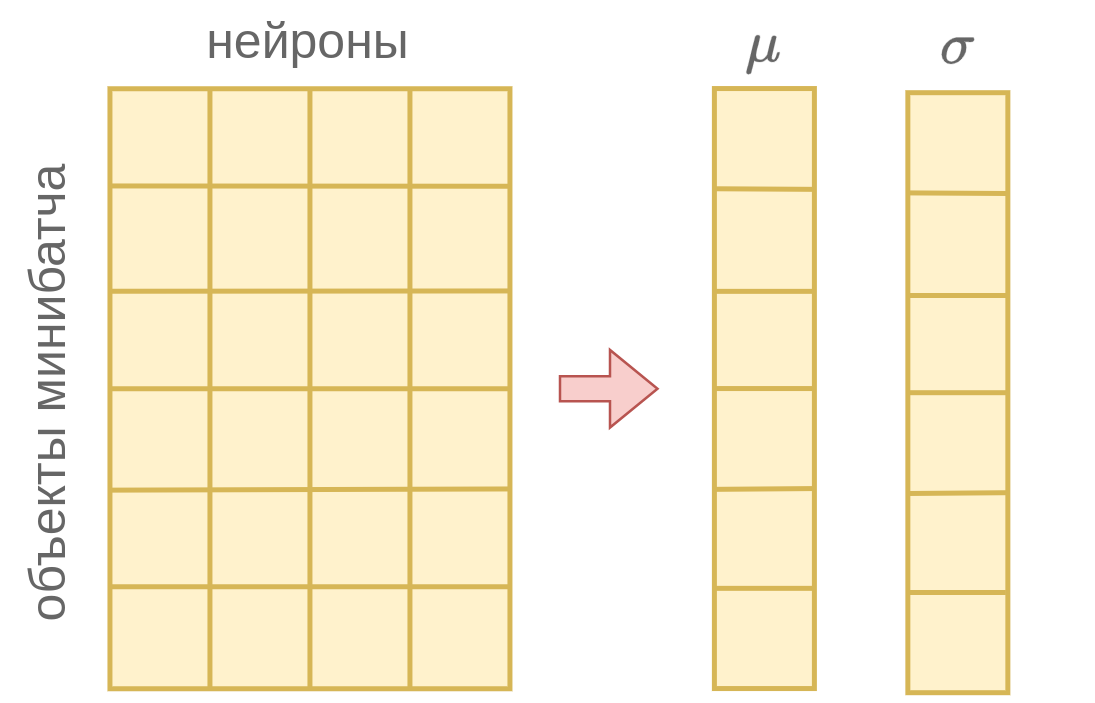
Поскольку расчёт и производится по активациям нейронов слоя в рамках одного объекта, то метод работает одинаково как в режиме обучения, так и в режиме применения в отличие от батч-нормализации, в которой использовались разные методы расчёта и в разных режимах.
Это повышает стабильность работы и обобщаемость настроенной модели на новые данные. Также нейросеть можно настраивать с любым размером мини-батча, даже по отдельным объектам.
Нормализация слоя была предложена для ускорения и повышения стабильности настройки рекуррентных нейросетей, а сейчас активно используется в архитектуре нейросетей-трансформеров.