Батч-нормализация
Идея метода
Классическим подходом к повышению качества прогнозов моделей является нормализация признаков, то есть приведение признаков к одинаковой шкале поскольку это выравнивает способность разных признаков влиять на прогноз.
Самым популярным методом нормализации является стандартизация (standardization), приводящая каждый признак со средним и стандартным отклонением к его стандартизованной версии со средним ноль и единичной дисперсией:
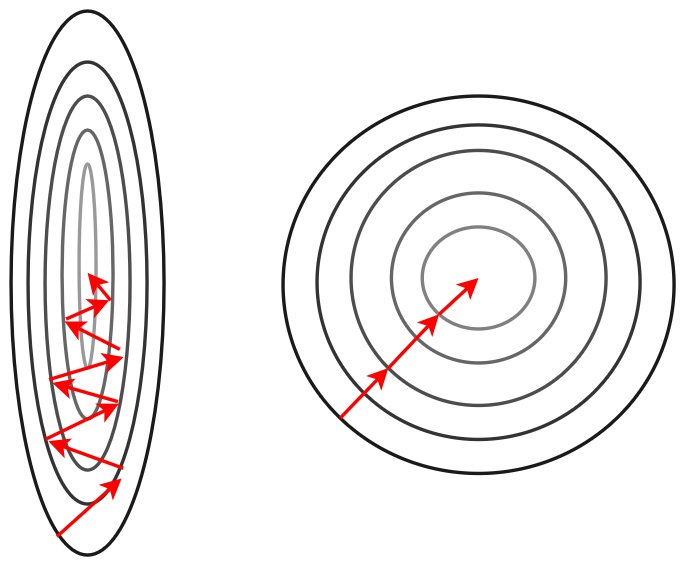
Нормализация также ускоряет настройку градиентными методами [1], поскольку делает линии уровня функции потерь менее вытянутыми и более скруглёнными, как показано на рисунке:
Батч-нормализация (batch-normalization, [1]) позволяет ускорить настройку сети за счёт нормализации не только входных признаков, но и активаций промежуточного слоя.
Слой батч-нормализации принимает на вход активации предыдущего слоя и их линейно перемасштабирует таким образом, чтобы они имели средние и стандартные отклонения :
где
-
- средние значения активаций ;
-
- стандартные отклонения активаций ;
-
- малая константа, призванная исключить деление на ноль.
Слой батч-нормализации (batch-normalization layer), нормирующий активации предыдущего слоя, может включаться в любом месте сети.
Его используют многократно для более ранних и более поздних слоёв.
Параметры и настраиваются вместе с остальными весами нейросети. Если для минимизации потерь действительно необходима стандартизация, то они настроятся на значения 0 и 1 соответственно. Если же стандартизация не нужна, то они настроятся на значения средних и стандартных отклонений соответственно, и слой батч-нормализации будет действовать как тождественное преобразование. В общем же случае эти параметры будут принимать некоторые промежуточные значения.
В линейном слое, применяемом к батч-нормализованным входам, необязательно использовать смещения (bias), поскольку нейроны уже смещаются на выучиваемые смещения из батч-нормализации.
Батч-нормализация будет по-разному действовать при обучении и применении нейросети. Рассмотрим эти различия.
Обучение нейросети
Если при стандартизации признаков мы могли предварительно вычислить их средние и стандартные отклонения, то для активаций промежуточных нейронов - уже нет, поскольку при настройке сети веса меняются, что изменяет распределение всех последующих нейронов!
Поэтому во время обучения сети (training) на каждом шаге обновления весов и перевычисляются как выборочные средние и стандартные отклонения нейронов по текущему мини-батчу, как показано ниже:
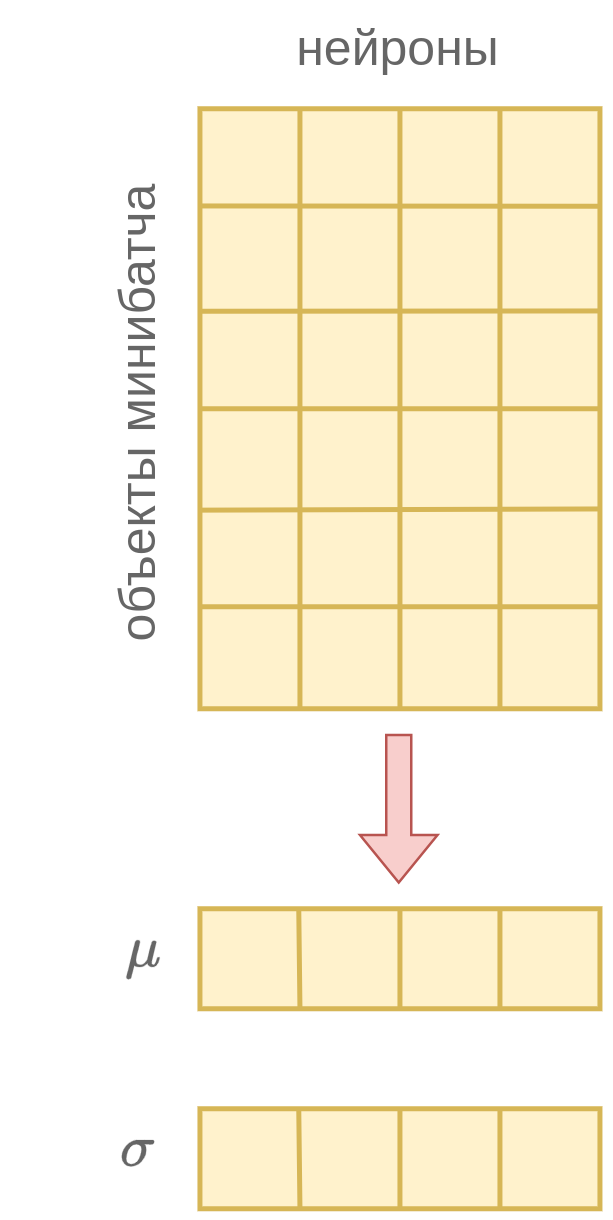
Для повышения точности оценки средних и стандартных отклонений (и, как следствие, повышения устойчивости батч-нормализации) рекомендуется настраивать нейросеть с повышенным размером мини-батчей.
Применение нейросети
Во время применения (inference) уже обученной сети мы уже могли бы вычислить средние и стандартные отклонения нейронов, поскольку веса сети уже настроены и зафиксированы, следовательно распределения промежуточных активаций зафиксированы и не меняются. Однако это предполагает дополнительный проход по обучающей выборке. На практике, чтобы его не делать, во время обучения вычисляются не только средние и стандартные отклонения по текущему мини-батчу, но и их сглаженные версии, используя экспоненциальное сглаживание. В результате к концу обучения мы просто подставляем вместо и их сглаженные значения.
Обоснование метода
Если поместить батч-нормализацию перед функцией нелинейности, то при соответствующей инициализации параметров и она будет приводить аргумент нелинейности в регион её существенных изменений (изгиб в функциях ReLU, LeakyReLU, tangh и т.д.).
Также батч-нормализация ускоряет настройку сети в целом за счёт ускорения настройки её более поздних слоёв. Как мы знаем, на каждой итерации оптимизации все веса сети обновляются одновременно. Но в контексте обновлённых весов более ранних слоёв распределение активаций более поздних слоёв поменялось, и обновления весов для поздних слоёв перестаёт быть актуальным! В итоге настройка сети замедляется, поскольку оптимизатору необходимо вначале настроить более ранние слои, и, когда они уже почти перестанут меняться, осуществлять предметную настройку зависящих от них более поздних слоёв.
Батч-нормализация упрощает и ускоряет одновременную настройку более ранних и более поздних слоёв за счёт того, что выходы слоя батч-нормализации, являющиеся входами последующего слоя, будут иметь предсказуемые средние и стандартные отклонени�я. Соответственно, слою, который эти выходы использует, будет проще под них настроить веса.
Батч-нормализация и прореживание сети
Если на параметры наложить регуляризацию, то часть мультипликаторов начнёт зануляться, что будет приводить к автоматическому исключению лишних нейронов и упрощению модели. Это является эффективным регуляризатором, снижая сложность модели как в терминах вычислений, так и в терминах занимаемой памяти.