Обрезка градиента
Неустойчивость оптимизации
Нейросети моделируют сложные нелинейные зависимости, вследствие чего рельеф функции потерь может быть сложным и подверженным резким изменениям, что может приводить к неустойчивой оптимизации весов как показано на рисунке [1]:
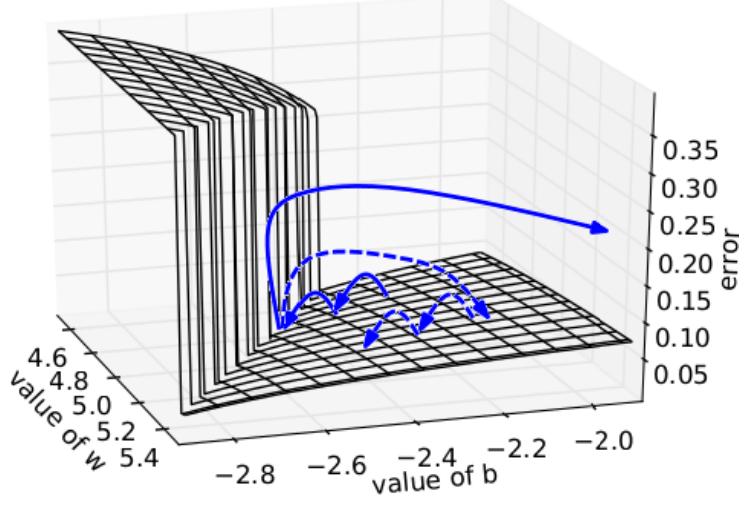
Для стабилизации обучения приходится снижать шаг обучения, замедляя его. Хотелось бы уменьшать сдвиг не постоянно, а только в областях резкого изменения функции, что достигается методом обрезки градиента.
Обрезка градиента
Обрезка градиента (gradient clipping, [1]) - популярная процедура, повышающая стабильность и скорость обучения нейросетей. Поскольку при изменчивом ландшафте функции потерь могут возникать большие по норме градиенты, то перед каждым обновлением весов в методе стохастического градиентного спуска норма градиента сравнивается с некоторым порогом . Если норма меньше порога, то веса обновляются �как обычно, а если больше - то норма градиента обрезается порогом перед обновлением весов:
Этот приём позволил существенно повысить стабильность и скорость настройки рекуррентных нейронных сетей, в которых из-за многократно повторяемых слоёв с одинаковыми весами проблема нестабильных градиентов стоит особенно остро.
Адаптивная обрезка градиента
Также можно использовать адаптивную обрезку градиента (adaptive gradient clipping, [2]):
В этом случае гораздо проще и интуитивнее задать порог , который теперь соответствует не максимальному абсолютному изменению весов, а их максимальному относительному изменению.
Например, мы можем задать ограничение, что на каждой итерации оптимизации веса не должны меняться больше, чем на 10% от их нормы.
Проблемой остаётся необходимость выбора единого порога , который не будет оптимальным для всех весов, поскольку часть из них изменяются в широком диапазоне значений, а другая часть - в узком. Поэтому лучше работает адаптивное ограничение градиента для каждого веса (и его градиента) в отдельности:
В формуле , а - гиперпараметр для исключения деления на ноль.
В работе [2] замена батч-нормализации адаптивным ограничением градиента позволила обучить сеть ResNet быстрее и повысить качество её прогнозов.
Литература
- Pascanu R., Mikolov T., Bengio Y. On the difficulty of training recurrent neural networks //International conference on machine learning. – Pmlr, 2013. – С. 1310-1318.
- Brock A. et al. High-performance large-scale image recognition without normalization //International conference on machine learning. – PMLR, 2021. – С. 1059-1071.