Автоматическое дифференцирование
Градиентные методы настройки нейросетей основаны на вычислении градиента от функции потерь. Для эффективного обучения нейросетей, вычисление градиента должно производиться
-
точно
-
и вычислительно эффективно.
Для этого используются методы автоматического дифференцирования - forward mode и backward mode. Второй метод также называется методом обратного распространения ошибки (backpropagation) и является основным методом настройки нейросетей.
Вначале же для полноты картины рассмотрим какие другие подходы мы могли бы применить для вычисления градиента функции.
Дифференцирование напрямую
Градиент можно вычислять вручную и программно реализовывать расчёт найденных производных. Этот подход можно автоматизировать, воспользовавшись библиотеками символьного дифференцирования, такими как SymPy [1] и SymEngine [2]. Это быстрее и избавит нас от потенциальных ошибок при вычислении производных.
В результате мы получим точное значение градиента. Недостатком подхода является сильное разрастание формул, по которым будет вычисляться градиент.
Рассмотрим нахождение производной по скаляру от функции .
Производная будет:
в которой потребуется многократное повторное вычисление функций , что неэффективно.
Если подобные операции возникают на каждом слое нейросети, то это приведёт к ещё большему разрастанию об�ъёма повторяемых неэффективных вычислений!
Численная аппроксимация
Градиент можно находить, используя численное приближение производных:
В формуле вектор содержит малую константу на -й позиции. Этот подход избавлен от ошибок дифференцирования, но даст лишь приближённое значение производных. Также он вычислительно неэффективен, поскольку требует прохода по нейросети:
-
один проход для вычисления
-
проходов для вычислений
Поскольку стоимость одного прохода вперёд по сети имеет порядок , то общая сложность вычисления всего градиента - , что весьма много для современных нейросетей, имеющих миллионы настраиваемых параметров.
Автоматическое дифференцирование
Идея
Вычислить производные можно точно и эффективно как по объёму вычислений, так и по памяти, используя методы автоматического дифференцирования (automatic differentiation [3]). Существуют библиотеки, эффективно реализующие эти методы, используя процессор и видеокарты - это PyTorch [4], Tensorflow [5] и JAX [6].
Цель автоматического дифференцирования - не вывести общую функциональную формулу производной, а уметь быстро вычислять её значение в заданной точке, обладая программным кодом для вычисления дифференцируемой функции.
Расчёт функции потерь сопряжён с вычислением суперпозиции большого числа математических преобразований, вызванных как расчётом нейросетевого прогноза, так и вычислением самой функции потерь от него.
Производная сложной функции
Автоматическое дифференцирование основано на формуле расчёта производной сложной функции [7], которое для скаляра будет
Для функции
производная по будет
Поскольку нейросети включают в себя суперпозицию большого числа преобразований, необходимо вычислять производную от большого числа вложенных функций.
Например, для суперпозиции нескольких функций от скаляра :
Последовательное применение формулы дифференцирования сложной функции даст
Функция потерь представляет собой суперпозицию большого числа нелинейных преобразований, отвечающих промежуточным вычислениям внутри нейросети, а также вычислению самой функции потерь. Поэтому вычисление функции потерь представляется в виде графа вычислений (computational graph), в котором узлами являются промежуточные переменные, необходимые для расчёта, а связи указывают, какие промежуточные переменные от каких зависят. Каждая переменная в графе вычислений - это некоторая простая операция от ранее посчитанных переменных, такая как сумма, разность, тригонометрическая или другая стандартная функция.
Главное требование - чтобы для этой функции была аналитически известна функция расчёта градиента.
Пример
Рассмотрим простейшую нейросеть - линейную регрессию, настраиваемую с регуляризацией:
Тогда вычисление можно представить в виде следующего вычислительного графа:
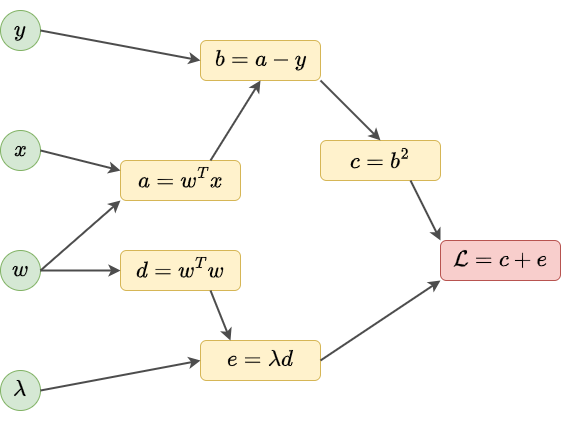
Все переменные делятся на три типа:
-
входные переменные: ;
-
финальная выходная переменная: ;
-
промежуточные переменные: .
Нас интересует расчёт градиента .
Вычислять его можно двумя способами:
-
в режиме прохода вперёд (forward-mode).
-
в режиме прохода назад (backward-mode).
Forward-mode
Рассмотрим эффективный расчёт градиента функции потерь методом forward-mode.
Он основан только на проходе вперёд (forward pass) по графу, при котором вычисляются не только значения промежуточных переменных графа, но и производные каждой промежуточной переменной по вектору весов сети . В каждую найденную производную подставляются значения промежуточных переменных графа, от которых она зависит, в результате чего сразу получаем промежуточное значение производной. Значение производной по финальной переменной и есть целевой градиент.
Пример использования forward-mode
Рассмотрим вычисление потерь
Построим по ней вычислительный граф:
Пусть нам нужно вычислить при
При проходе вперёд по графу вычислений получаем следующие значения промежуточных переменных:
Но одновременно при проходе вперёд вычисляются и производные по целевой переменной (вектору весов ):
Градиент равен 2-мерному вектору, поскольку представляет вектор из частных производных
Backward-mode (обратное распространение ошибки)
Теперь рассмотрим другой способ эффективного расчёта градиента потерь по весам нейросети - backward-mode.
Этот метод также называется методом обратного распространения ошибки (backpropagation, backprop) и является основным методом для настройки весов нейросети.
Этот метод состоит из двух шагов:
-
Проход вперёд (forward pass), на котором итеративно слева-направо вычисляются (и запоминаются!) значения всех промежуточных переменных графа вычислений. Производные по весам при этом не вычисляются.
-
Проход назад (backward pass), на котором итеративно справа-н�алево вычисляются производные текущих переменных графа от более ранних переменных (от которых зависят текущие), как функции от переменных графа вычислений. Далее подставляются значения этих переменных, в результате чего производные вычисляются (и используются) как числа.
Пример использования backward-mode
Рассмотрим снова вычисление потерь
Построим по ней вычислительный граф:
Пусть, как и раньше, нам нужно вычислить при
При проходе вперёд (forward pass) по графу вычислений получаем следующие значения промежуточных переменных:
Эти переменные запоминаются для использования при проходе назад (backward pass), в которых рекуррентно вычисляются производные итоговых потерь по промежуточным переменным графа от более поздних к более ранним (справа-налево).
Продемонстрируем работу прохода назад:
Как видим, получили тот же результат, что и при режиме forward-mode.
Обратим внимание, что веса ничем принципиально не отличаются от других входных переменных, поэтому мы можем применять тот же алгоритм для вычисления градиента по ним. Например, в первом методе neural style transfer [8] использовался градиент по входному изображению, а не весам нейросети!
Сравнение forward-mode и backward-mode
Преимуществом forward-mode является то, что и расчёт промежуточных переменных, и расчёт производных производится одновременно всего за один проход (forward pass). Это снижает расходуемый объём памяти, поскольку значения промежуточных переменных дост�аточно помнить только до их последнего использования, а дальше можно высвобождать память для других вычислений.
Расчёт же градиента методом backward-mode состоит из двух проходов:
-
прохода вперёд, во время которого нужно запомнить значения всех промежуточных переменных;
-
прохода назад, на котором вычисляются производные потерь по промежуточным переменным.
Таким образом, перед проходом назад нужно держать в памяти значения всех промежуточных переменных вычислительного графа, вследствие чего расходы на память у backward-mode увеличиваются.
Если рассматривать расходы на вычисления, то для сужающегося вычислительного графа, как на рисунке ниже, эффективнее backward-mode:

Мы это видели в примере, где для forward-mode все операции были векторными, поскольку forward-mode требовал отдельных вычислений для каждого веса. В backward-mode большая часть операций была над числами, и лишь в конце появились векторные операции.
Для расширяющегося же графа вычислений, как на рисунке ниже, вычислительно эффективнее forward-mode:

На практике обычно работают с архитектурами с сужающимся графом вычислений, которые в конце упираются в единственную скалярную функцию потерь. Поэтому при их настройке используют backward-mode, называемый также методом обратного распространения ошибки.
Пример совмещения forward-mode и backward-mode
Бывают случаи, когда вычислительно �эффективно совместить методы forward-mode и backward-mode. Рассмотрим следующую архитектуру:
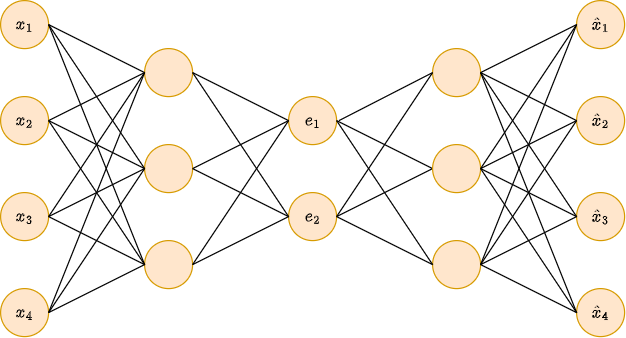
Пусть нам нужно вычислить изменчивость выходов по отношению ко входам, то есть матрицу .
Как видим,
-
вначале граф в�ычислений сужается, когда переводится в промежуточное пространство эмбеддингов ;
-
затем граф расширяется, когда из эмбеддингов мы вычисляем выходы .
По формуле производной сложной функции имеем:
Тогда производные эффективнее посчитать через backward-mode, а - через forward mode!
В [9] приведён псевдокод для метода обратного распространения ошибки в общем виде. Для более детального ознакомления с представленными методами рекомендуется учебник [10].