Оптимизаторы с переменным шагом
Проблемой стандартных градиентных методов оптимизации, таких как стохастический градиентный спуск (SGD) или стохастический градиентный спуск с инерцией (SGD+momentum), является то, что они устанавливают одинаковый шаг обучения (learning rate) вдоль всех направлений в пространстве настра�иваемых весов нейросети. Это не оптимально, поскольку
-
вдоль одних направлений функция потерь изменяется резко и быстро, поэтому, во избежание расходимости, нужно выбирать малый шаг обучения;
-
вдоль других направлений функция потерь меняется более плавно и постепенно, и шаг обучения нужно выбрать побольше, чтобы ускорить сходимость.
Пример функции потерь с разной скоростью изменений вдоль направлений и показан на рисунке ниже вместе с разрезами вдоль каждой из осей:
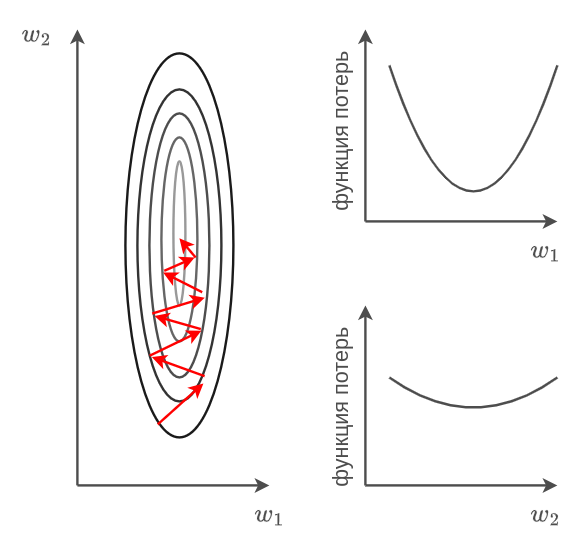
Методы с единым шагом обучения приходится запускать с малым шагом обучения, чтобы гарантировать сходимость вдоль направлений быстрого изменения функции, что, в свою очередь, делает сходимость очень медленной вдоль плавно меняющихся направлений.
Идея улучшения методов оптимизации для настройки нейросетей заключается в независимом подборе своей скорости изменений весов вдоль каждой оси в пространстве весов.
Например, на рисунке выше имеет смысл шаг обучения вдоль оси выбрать поменьше, а вдоль оси - побольше.
В общем случае направления, вдоль которых функция потерь меняется быстро и медленно, определяются не осями координат, а направлениями собственных векторов матрицы Гессе функции потерь (матрицы, состоящей из всевозможных производных второго порядка потерь по весам). Тем не менее, даже адаптация скорости сходимости вдоль осей существенно повышает скорость сходимости!
Предлагается динамически подстраивать шаг обучения вдоль каждой оси под скорость изменения функции, оценивая эту скорость квадратом частной производной функции потерь вдоль соответствующей оси.
Далее будут описаны основные методы, реализующие эту идею.
Метод AdaGrad
Метод AdaGrad [1] производит изменение каждого веса вектора весов по следующим формулам:
где
-
- номер итерации;
-
- номер параметра (оси), вдоль которого производится оптимизация;
-
- число настраиваемых весов сети;
-
- фиксированное смещение, чтобы избежать деления на ноль;
-
- средние потери по мини-батчу объектов .
Метод RMSprop
В методе AdaGrad квадрат градиента кумулятивно накапливается в нормировке . Это решение обладает следующим недостатком: если в начале оптимизации функция потерь менялась резко, а потом стала меняться плавно, то всё равно будет оставаться большим, замедляя сходимость.
Метод RMSprop (root mean square propagation, [2]) лишён этого недостатка за счёт усреднения квадрата градиента экспоненциальным сглаживанием, за счёт которого большие по величине градиенты в начале оптимизации будут забываться экспоненциально быстро.
Обновление каждого вектора весов для будет производиться по формулам:
Гиперпараметр отвечает за длину истории, по которой копится квадрат градиента, и обычно выбирается равным .
Метод Adam
Метод Adam (adaptive moments, [3]) совмещает метод RMRprop с внесением инерции (momentum) и является самым популярным методом настройки нейр�осетей.
Обновление каждого веса для производится по следующим формулам:
Перенормировка и осуществляется, чтобы избежать смещения оценок, вызванных начальной инициализацией .
Обычно гиперпараметры берут равными
Псевдокод метода представлен ниже для векторов :
перемешать объекты выборки
инициализировать случайно
# вектор из нулей
# вектор из нулей
ПОВТОРЯТЬ
ЕСЛИ :
перемешать объекты выборки
ДО СХОДИМОСТИ
В псевдокоде обозначает поэлементное перемножение векторов, а извлечение корня из вектора и деление на него также происходит поэлементно.