Инициализация
Перед началом обучения нейросети необходимо случайно инициализировать её веса.
Инициализировать начальные значения весов нужно именно случайно, а не одинаковыми константами, иначе для симметрично расположенных нейронов с одинаковыми весами на каждом шаге оптимизации вследствие симметрии архитектуры они будут изменяться синхронно на одинаковую величину, и нейроны будут извлекать одинаковые признаки!
Обычно веса инициализируют
-
из равномерного распределения ,
-
либо (чаще) из нормального распределения , ,
где и малы, а математическое ожидание полагают равными нулю.
Разумная инициализация должна обеспечивать примерную одинаковость дисперсий по слоям нейросети для активаций, а также для градиентов потерь по промежуточным переменным вычислительного графа в методе обратного распространения ошибки.
Будем предполагать независимость и одинаковую распределённость активаций.
В случае нелинейностей с узкой областью изменений (в районе нуля для активаций Sigmoid, Tangh, HardTanh, SoftSign) нужно дополнительно обеспечивать малость дисперсий активаций за счёт уменьшения дисперсии входных признаков и начальных значений весов. В этом случае функции нелинейности не будут выходить на насыщение, и нейроны (по крайней мере, в начале обучения) будут настраиваться на невырожденные признаки.
Нечётные функции нелинейности
Рассмотрим случай нечётных функций нелинейности, то есть удовлетворяющих свойству:
Среди рассмотренных функций этому свойству будут удовлетворять нелинейности Tanh, HardTanh и SoftSign.
Рассмотрим нейрон скрытого слоя с выходом , где
а - число нейронов предыдущего слоя, - их активации, а смещение не пишем, поскольку инициализируем его нулём.
Обратим внимание, что если и , то
где в последнем переходе мы воспользовались независимостью случайных величин и .
В силу нечётности функции нелинейности,
Таким образом, если входные признаки отцентрированы (имеют нулевое мат. ожидание), то нулевым мат. ожиданием будут обладать и полученные от них активации, а следовательно, по индукции, и активации всех последующих слоёв, если мы используем нечётные функции нелинейности.
Калиброванная случайная инициализация
Если рассматриваем нейрон первого скрытого слоя, то - входные признаки. Отнормируем эти признаки, чтобы они имели нулевое среднее и единичную дисперсию. По формуле дисперсии произведения имеем:
где
-
, поскольку мы так инициализируем веса, что .
-
, поскольку , вследствие того, что начальные признаки отцентрированы (имеют нулевое среднее), а линейный слой с симметричными функциями нелинейности сохраняет свойство нулевых мат. ожиданий для последующих активаций.
При нормализации входных признаков они все будут иметь нулевое мат. ожидание и дисперсию 1.
Все веса на заданном слое инициализируются случайно с одинаковой дисперсией . Веса генерируются независимо от входов . Предположим также, что входы - независимые случайные величины и имеют одинаковую дисперсию . Тогда:
, поскольку веса инициализируются малыми числами, поэтому суммарный вход также мал, а для малых значений нелинейности Tanh, HardTanh и SoftSign примерно равны тождественной функции нелинейности:
Входы в общем случае будут иметь различающиеся дисперсии, но если мы стандартизуем входные признаки (входы нулевого слоя нейросети), чтобы они имели одинаковую дисперсию, а дисперсию весов будем выбирать равной
то дисперсии выходов слоя также будут равны единице и далее, по индукции, будут примерно равны единице и выходы всех последующих слоёв сети.
Если , то дисперсии активаций будут возрастать с номером слоя, а если
- то убывать.
Инициализация весов, используя (1), называется калиброванной случайной инициализацией (calibrated random initialization).
-
Если , то , следовательно, .
-
Если , то .
Инициализация Ксавьера
Если рассматривать не дисперсии активаций при проходе вперёд, а дисперсии градиентов при проходе назад в методе обратного распространения ошибки, то те же самые рассуждения для сохранения дисперсии градиентов по промежуточным переменным вычислительного графа приведут к требованию
где - число выходов линейного слоя.
В работе [1] предложено находить компромисс между сохранением дисперсий активаций (1) и сохранением дисперсий градиентов (2), беря среднее гармоническое между ними:
-
Если , то , следовательно .
-
Если , то .
Эта инициализация называется инициализацией Ксавьера (Xavier initialization, известная также как Glorot initialization, поскольку автор Glorot Xavier).
Ниже показано сравни�тельное распределение активаций (при прямом проходе, activation value) и градиентов (при обратном проходе, backpropagated gradients) для инициализации весов для и вверху и внизу каждого из изображений.
Распределение активаций на разных слоях будет иметь вид [1]:

А распределение градиентов на разных слоях будет следующим [1]:
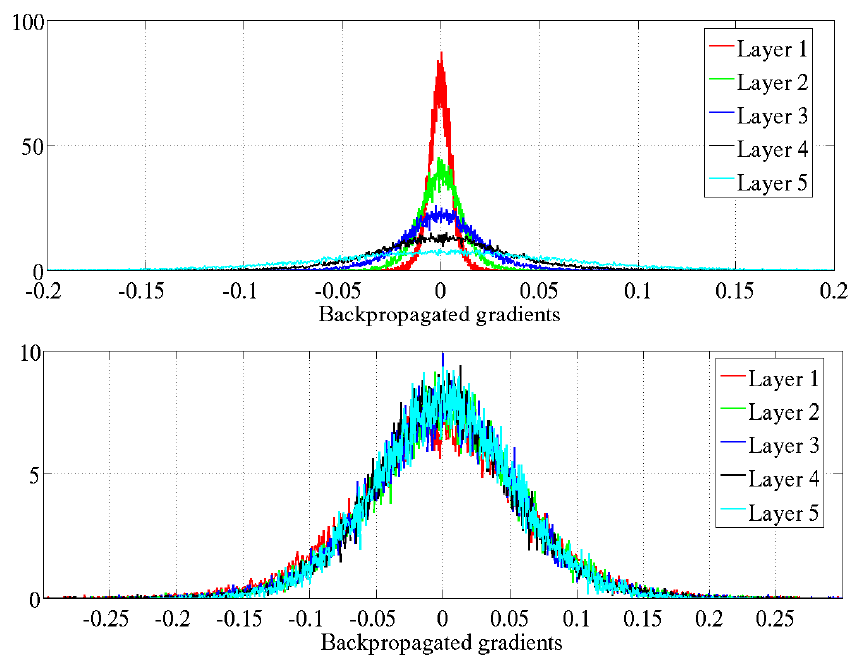
Из-за отсутствия множителя в калиброванной случайной инициализации распределение активаций сужается при переходе к более поздним слоям (изображение 1), а распределение градиентов, наоборот, расширяется (изображение 3). При инициализации Ксавьера оба распределения сохраняют стабильность по слоям (изображения 2 и 4).
Рекомендуется строить графики распределения активаций и градиентов при настройке новых сложных архитектур для контроля стабильности обучения.
Инициализация Хе
Инициализация весов Хе (He initialization, также известная как Kaiming initialization, поскольку автор Kaiming He) была предложена в работе [2] и рассматривает случай ReLU и Leaky ReLU функций нелинейности. Они сложнее, чем симметричные нелинейности, поскольку . Например, для ReLU всегда .
Рассмотрим нейрон в промежуточном слое с выходом
где - число нейронов предыдущего слоя, а - сумма активаций ещё более раннего слоя, формирующая �активацию нейрона .
Смещение, как и прежде, инициализируем нулём.
Используя генерацию весов с нулевым мат. ожиданием () и свойство
получим:
Предполагая независимость входов и весов,
где мы воспользовались симметрией распределения (как функции от весов с симметрично распределёнными весами относительно нуля), у которого половина отрезается нелинейностью ReLU:
Таким образом, чтобы сохранить дисперсию при переходе от предыдущего слоя к текущему, необходимо инициализировать веса по правилу:
Поэтому веса можно инициализировать из следующих распределений:
-
-
.
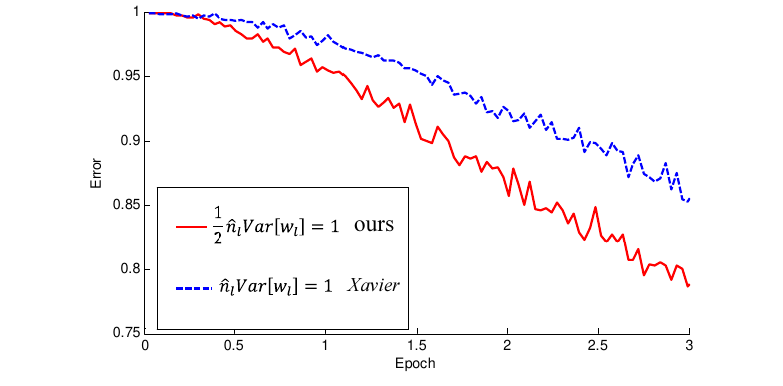
Инициализация Хе ускоряет обучение глубоких нейронных сетей с функцией нелинейности ReLU [2]:
Для функции активации Leaky ReLU:
требование по равномерности дисперсии по слоям становится [2]:
Легко заметить, что полученная формула
-
при (случай ReLU) сводится к (3),
-
при (тождественная нечётная нелинейность) сводится к (1).
Итог
-
Веса сети нужно инициализировать из нормального или равномерного распределения с нулевым мат. ожиданием и малой дисперсией.
-
Дисперсия должна быть тем меньше, чем больше нейронов в слое.
-
Инициализация Ксавьера используется для слоя с нечётными функциями активации.
-
Инициализация Хе используется для слоя с функциями активации ReLU и LeakyReLU.
Литература
- Glorot X., Bengio Y. Understanding the difficulty of training deep feedforward neural networks //Proceedings of the thirteenth international conference on artificial intelligence and statistics. – JMLR Workshop and Conference Proceedings, 2010. – С. 249-256.
- He K. et al. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification //Proceedings of the IEEE international conference on computer vision. – 2015. – С. 1026-1034.