Декодировщик трансформера
Декодировщик модели трансформера (transformer) [1] принимает на вход эмбеддингов элементов уже сгенерированной последовательности и выдаёт вероятностное распределение следующего предсказываемого элемента последовательности.
Будем, как и в оригинальной статье [1], рассматривать задачу машинного перевода текста с одного языка на другой, в которой:
-
входная последовательность - текст на исходном языке;
-
выходная последовательность - текст на целевом языке.
Каждая последовательность состоит из токенов, которыми выступают слова текста.
Декодировщик состоит из последовательных применений блоков декодировщика, каждый раз - со своими параметрами. В оригинальной статье [1] бралось .
Задача каждого блока - ут�очнить эмбеддинги сгенерированных токенов с учётом их контекста из других сгенерированных токенов.
Последний блок выдаёт окончательные эмбеддинги, к каждому из которых независимо применяется линейный слой (с одинаковыми параметрами) и SoftMax-преобразование. Итоговый вектор выходов интерпретируется как вероятность токенов на каждой позиции выходной последовательности. Нас интересует только токен на позиции , который выбирается максимально вероятным. После этого декодировщик перезапускается для предсказания токенов в позициях пока не будет сгенерирован токен [EOS] (end of sequence), означающий конец генерации.
Блок декодировщика
Схема блока декодировщика в модели трансформера [1] показана на рисунке справа внизу [2]:
![]()
Блок декодировщика показан в контексте двух блоков кодировщика и ещё одного блока декодировщика и последующих преобразований (в оригинальной работе использовалось 6 блоков).
Как видим, блок декодировщика состоит из тех же преобразований, что и блок кодировщика. Преобразования применяются к каждому токену независимо.
Отличия декодировщика от кодировщика
Для декодировщика входными токенами является уже не входная, а выходная последовательность, сдвинутая на один шаг вперёд спец. токеном [BOS] (beginning of sequence), как описывалось ранее.
Это сделано для того, чтобы каждый раз для всех ранее сгенерированных токенов предсказывался следующий, а в самом начале - первый токен.
Крупным пунктиром на схеме выше обозначена тождественная связь, когда входной эмбеддинг в неизменном виде прибавляется к выходному.
Блок самовнимания
Блок самовнимания (self-attention) в декодировщике применяется точно так же, как и в случае кодировщика, с тем лишь отличием, что степени внимания маскируются таким образом, чтобы из позиции нельзя было смотреть в будущие позиции , которые ещё не сгенерированы (masked attention). Реализуется это прибавлением к скалярным произведениям запроса и каждого ключа в запрещённых (будущих) позициях, что после применения SoftMax-преобразования, делает степень внимания к этим позициям нулевой, препятствуя заглядыванию декодировщика в будущие элементы последовательности, которые ещё не сгенерированы.
Блок кросс-внимания
Также в декодировщике используется блок кросс-внимания (cross-attention, encoder-decoder attention), уточняющий эмбеддинги декодировщика, опираясь на информацию о входной последовательности. Ведь чтобы осуществить перевод на другой язык, необходимо прочитать текст на исходном языке! Он устроен точно так же, как и блок самовнимания в кодировщике, но внимание в нём направлено от токенов выходной последовательности к итоговым токенам входной последовательности, полученных с выходов последнего блока кодировщика. Это реализуется тем, что:
- запросы (queries) генерируются по уже сгенерированным токенам выходной последовательности;
- ключи (keys) и значения (values) генерируются по эмбеддингам входной последовательности.
Этот вид внимания визуализирован на схеме выше линиями с мелким пунктиром.
Виды внимания в трансформере
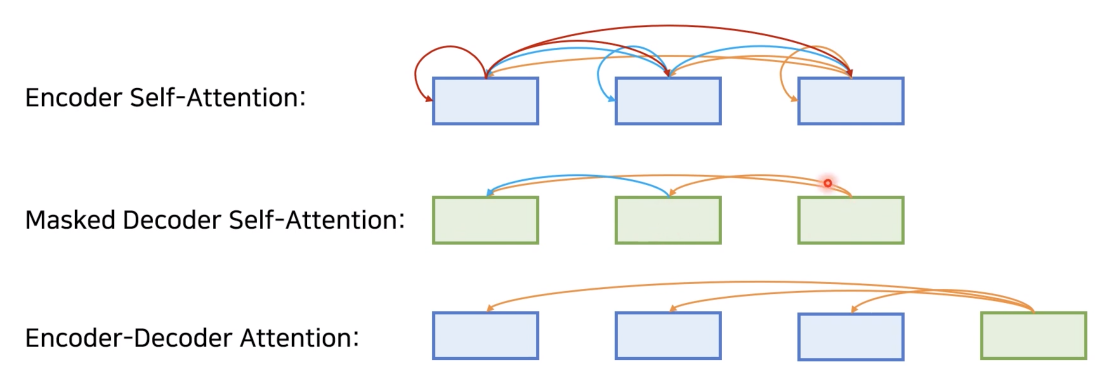
Таким образом, в модели трансформера использовались три типа внимания:
-
самовнимание в кодировщике, когда входной токен мог смотреть на любой другой входной токен;
-
маскированное внимание в декодировщике, когда текущий выходной токен мог смотрет�ь только на себя и на предыдущие;
-
кросс-внимание в декодировщике, когда выходной токен мог смотреть на любые входные токены.
Эти типы внимания проиллюстрированы ниже [3]: