Позиционное кодирование
Все этапы в блоке кодировщика модели трансформера [1] (feed forward, суммирование, нормализация, самовнимание) работают независимо для каждого токена. Это ускоряет работу модели, позволяя производить вычисления параллельно, однако при этом полностью теряется информация о позиции каждого токена последовательности.
Но эта информация важна. Например, фразы "the mother loves the daughter" и "the daughter loves the mother" состоят из одних и тех же слов, но имеют разный смысл!
Для интеграции информации о позиции каждого токена используется позиционное кодирование (positional encoding), состоящее в том, что каждой позиции pos (индекса токена в последовательности) сопоставляется свой -мерный эмбеддинг, а затем эти эмбеддинги прибавляются к эмбеддингам самих токенов.
Позиционные эмбеддинги прибавляются только ко входам первого блока кодировщика. Последующие блоки кодировщика работают с выходными эмбеддингами предыдущего блока в неизменном виде.
В блоках декодировщика позиционное кодирование т�акже используется только для входов самого первого блока.
Вектор позиционного кодирования для токена на позиции заполняется синусами от этой позиции на чётных элементах вектора и косинусами от позиции - на нечётных, причем для разных элементов используются синусы и косинусы разных периодов от до :
Можно объединить эти вектора в матрицу .
Пример визуализации этой матрицы при кодировании последовательности из 32 токенов в 16-мерном пространстве приведён ниже [2]:
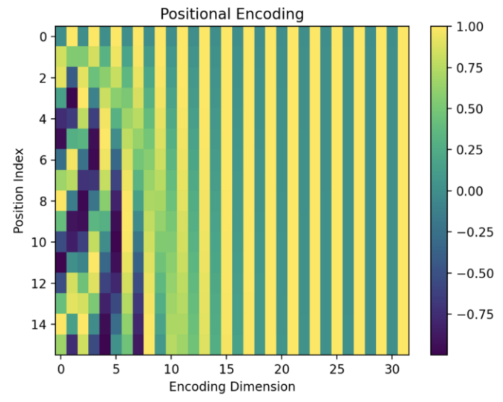
-му токену будет соответствовать -й столбец. Как видим, существует взаимно однозначное соответствие между номером позиции и её эмбеддингом.
Позиционное кодирование идейно повторяет кодирование номеров позиций в виде двоичного представления:
В этом представлении более поздние биты представления меняются более плавно, чем более ранние. Такой же эффект реализуется и в формулах позиционного кодирования, что позволяет нейросети восстановить позицию по эмбеддингу этой позиции.