Кодировщик трансформера
Кодировщик модели Transformer (transformer) [1] принимает на вход эмбеддингов элементов входной последовательности и выдаёт уточнённых эмбеддингов для каждого элемента с учётом его контекста (других элементов последовательнос�ти).
Например, в предложениях "Замок запирается ключом" и "Замок окружён рвом, заполненным водой" слово "Замок" имеет разные смыслы, что становится ясным из контекста.
Кодировщик состоит из последовательных применений блоков кодировщика, каждый раз - со своими параметрами. В оригинальной статье [1] бралось .
Блок кодировщика
Схема одного блока кодировщика представлена ниже [2] для перевода входного предложения "Thinking machines":
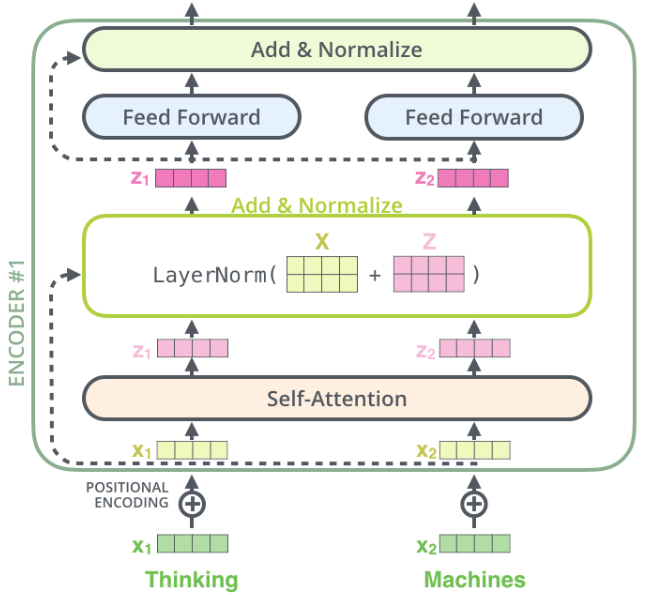
Первый блок кодировщика принимает -мерные эмбеддинги каждого токена входной последовательности, прибавляет к ним эмбеддинги позиции токена в последовательности (чтобы сеть знала, где каждый токен расположен), после чего выдаёт такое же количество -мерных выходных эмбеддингов, которые в результате некоторых преобразований уже учитывают контекст всей входной последовательности (всего переводимого предложения). В статье берётся .
Поскольку в трансформере предлагается наслаивать такие блоки раз (каждый раз - со своими параметрами), каждый из блоков будет всё больше уточнять эмбеддинги по контексту, пока последний блок не выдаст итоговые эмбеддинги, с которыми впоследствии будет работать декодировщик модели, состоящий из отдельных блоков декодировщика.
Считается, что сети достаточно передать информацию о позициях токенов в последовательности лишь один раз в самом начале, поэтому позиционные эмбеддинги прибавляются к эмбеддингам входных токенов только для первого блока декодировщика. Последующие блоки работают только с выходными эмбеддингами предшествующих блоков в неизменном виде.
Каждый блок кодировщика имеет свои параметры, но функционально устроен единообразно:
-
каждый входной эмбеддинг преобразуется через блок самовнимания (self-attention) в выходной эмбеддинг;
-
входной и выходной эмбеддинги суммируются, как показано пунктиром на схеме;
-
суммарный эмбеддинг пропускается через послойную нормализацию (LayerNorm);
-
результирующий эмбеддинг преобразуется двухслойным персептроном (Feed Forward) в выходной;
-
затем опять входной и выходной эмбеддинги (в контексте предыдущего шага) суммируются, как показано пунктиром на схеме;
-
суммарный эмбеддинг снова пропускается через послойную нормализацию (LayerNorm).
Для каждого из блоков декодировщика этапы 1-6 применяются к элементу входной последовательности (представленному эмбеддингом) независимо с одинаковыми весами. При этом веса внутри каждого блока свои. Рассмотрим подробнее каждый этап.
Сумма входного и выходного эмбеддингов
Суммирование входа с выходом, как и в модели ResNet, мотивировано тем, что
-
градиент функции потерь по весам более ранних слоёв при обучении ведёт себя более стабильно — не взрывается и не затухает, что упрощает настройку этих слоёв и ускоряет обучение всей сети;
-
в глубоких сетях целесообразно наслаивать слои, оставляя возможность модели сохранить текущее представление (что обеспечивает тождественная связь), а при необходимости — вносить лишь небольшие уточнения (с помощью нелинейного блока, веса которого инициализируются малыми числами).
Feed Forward
Feed Forward преобразование представляет собой двухслойный персептрон с активаци�ей ReLU:
где
-
- входной эмбеддинг токена,
-
- его нелинейно преобразованная версия той же размерности,
-
- обучаемые матрицы,
-
- обучаемые вектора смещений.
Этот блок позволяет модели настраивать сложные зависимости и строить более богатые признаковые представления.
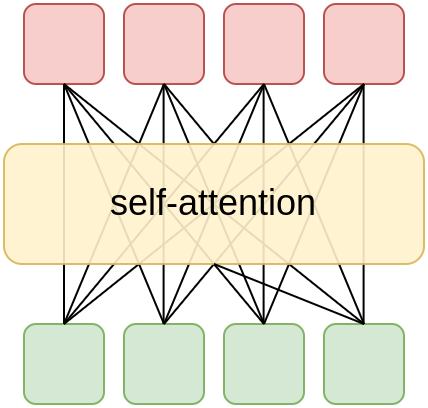
Self-attention
Блок самовнимания (self-attention) призван обогатить эмбеддинг каждого токена информацией о других токенах последовательности. Каждый токен при этом использует информацию со всех других токенов, что схематично представляется в виде:
Рассмотрим детально, как работает блок самовнимания. Для большей ясности изложения будем писать сбоку внизу размерности векторов и матриц.
Пусть мы обрабатываем последовательность длины и каждый токен этой последовательности представляется -мерным эмбеддингом. Тогда входную последовательность можно представить в виде матрицы .
Используется механизм внимания (attention mechanism), в котором по эмбеддингу каждого токена генерируются:
-
-м�ерный запрос (query) ;
-
-мерный ключ (key) ;
-
-мерное значение (value) .
В статье [1] использовались , поскольку самовнимание впоследствии повторялось 8 раз.
Объединяя для каждого токена последовательности вектора их запросов, ключей и значений, получим:
-
матрицу запросов ;
-
матрицу ключей ;
-
матрицу значений .
Тогда выходной эмбеддинг вычисляется агрегацией значений для всех токенов последовательности:
Агрегация производится суммированием значений с весами, равными соответствиям соответствующих ключей запросу. Соответствия вычисляются по их отмасштабированному скалярному произведению (scaled dot-product attention).
Матричная запись
Для повышения производительности вычисления производятся для всех токенов одновременно, используя матричную запись.
Генерируются матрицы:
– запросов: ;
– ключей: ;
– значений: .
Вычисления над полученными матрицами графически проиллюстрированы ниже [2]:
![]()
Результат самовнимания для всех токенов запишется как
что можно изобразить графически [2]:
![]()
Объединяя все операции, одна головка самовнимания (self-attention head) работает следующим образом:
Multi-head self-attention
В трансформере [1] используется не одна, а 8 головок самовнимания, каждая - со своими весами . Каждая головка призвана собирать свою контекстную информацию, что и наблюдается на практике.
После применения головок самовнимания их результаты конкатенируются, после чего пропускаются через линейное преобразование c матрицей , чтобы вернуть размерность эмбеддинга к исходному -мерному вектору:
Графически это выглядит следующим образом [2]:
![]()
Весь процесс совместно можно визуализировать как [2]:
![]()
Сравнение с рекуррентной сетью
Сравним головку самовнимания трансформера с рекуррентной сетью. Пусть для простоты обрабатываются -мерные эмбеддинги, размерность скрытого состояния рекуррентной сети совпадает с размерностями эмбеддингов самовнимания и тоже равна .
Для суммаризации информации о -мерных эмбеддингах последовательности длины рекуррентной сети требуется операций, в то время как модулю самовнимания - (обоснуйте!). Таким образом, сложность вычислений трансформера сильнее зависит от длины обрабатываемой последовательности.
Для сбора информации для эмбеддинга с другого эмбеддинга рекуррентной сети требуется порядка проходов по последовательности (а с каждой итерацией часть информации теряется!), в то время как самовнимание считывает эту информацию напрямую за , поэтому информация передаётся с меньшими искажениями.
Рекуррентная сеть хранит историю целиком в одном -мерно�м внутреннем состоянии, а трансформеру требуется хранить все -мерных эмбеддингов, в связи с чем трансформеру для работы требуется значительно больше памяти.
Итог
Подытоживая, блок кодировщика уточняет начальные эмбеддинги каждого токена входной последовательности, пропуская их через нелинейные преобразования Feed Forward и агрегируя информацию с эмбеддингов других токенов последовательности, используя self-attention. Для удобства настройки блоки самовнимания и Feed Forward реализуются как остаточные блоки.
Всего в трансформере [1] использовано 6 таких блоков, работающих последовательно.
Первый блок кодировщика обрабатывает эмбеддинги входных токенов в сумме с эмбеддингами, кодирующими расположение этих токенов в последовательности (позиционное кодирование). Последующие блоки кодировщика обрабатывают выходные эмбеддинги предыдущего блока в неизменном виде.
В следующей главе мы рассмотрим, как устроено позиционное кодирование.