Контроль качества предсказания вероятностей
Калибровка вероятностей
Во многих задачах классификации важно не только уметь предсказывать метки классов, но и их вероятности. Например:
-
При обнаружении неправомерных злонамеренных действий в сети важно оценивать их вероятность, чтобы балансировать между ложными срабатываниями и пропущенными инцидентами.
-
При медицинской диагностике важно оценивать вероятность болезни по снимкам/анализам, чтобы принимать решение о дальнейшей диагностике.
Подбор преобразования и его параметров , переводящего рейтинг класса в его вероятность, называется калибровкой вероятностей (probability calibaration).
График калибровки
Для контроля качества калибровки бинарной классификации строят график калибровки (calibration-plot), показанный ниже [1]:
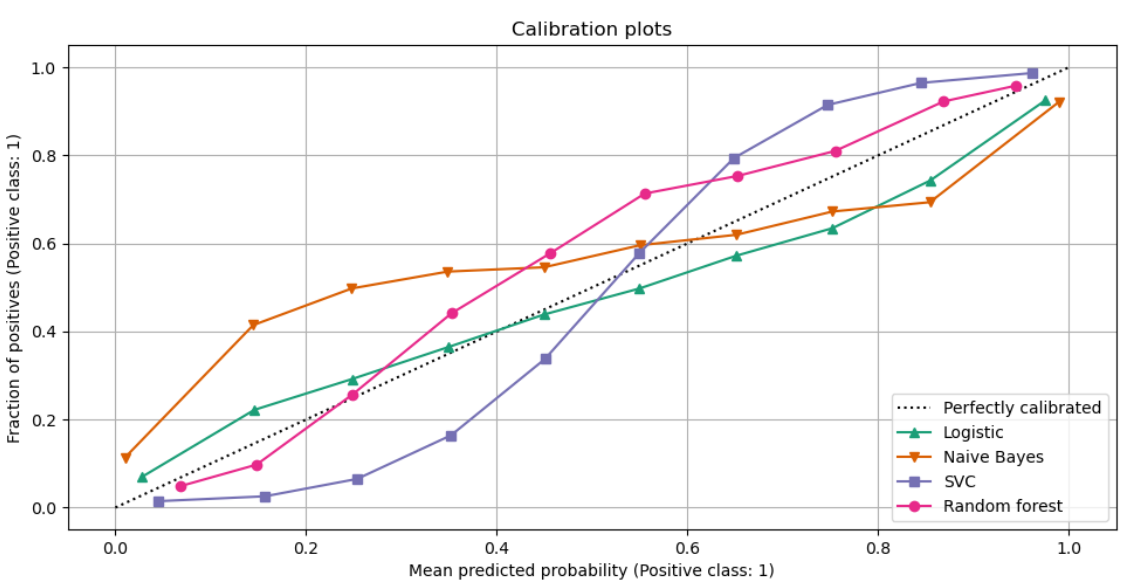
По оси X откладывают предсказанную вероятность положительного класса, а по оси Y - фактическую. Чем получаемая зависимость ближе к диагонали Y=X, тем лучше классификатор предсказывает вероятности.
Например, на графике выше видно, что метод Naive Bayes недооценивает истинную вероятность, когда предсказывает её малое значение, и, наоборот, переоценивает вероятность, когда предсказывает её большое значение.
Поскольку в обучающей выборке нам даны только истинные классы, а не их вероятности, то для расчета истинных вероятностей мно�жество предсказанных вероятностей разбивают на отрезки, например:
В рамках каждого отрезка вычисляют фактическую вероятность положительного класса как долю объектов, принадлежащих этому классу.
Качество прогнозов меток и вероятностей классов
Подчеркнём, что даже если классификатор хорошо предсказывает метки классов, вероятности классов он может предсказывать плохо, как, например, на рисунке ниже:
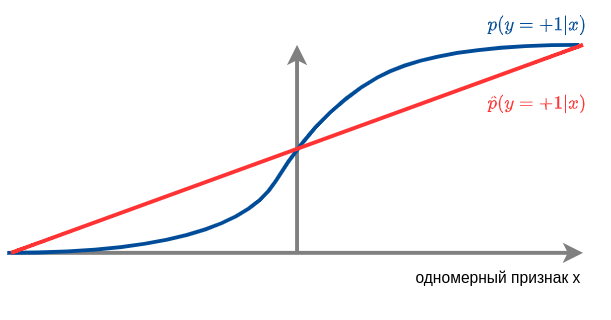
Классификатор верно настроился на то, что:
-
При вероятность положительного класса меньше 0.5, и надо предсказывать отрицательный класс.
-
При положительный класс более вероятен, и нужно предсказывать его.
Поэтому точность предсказания меток класса будет высокой, однако вероятности классов предсказываются неверно, поскольку !
Базовые меры качества классификации, такие как accuracy, error rate, precision, recall и др., оценивают только качество предсказания меток классов.
Для оценки качества предсказания вероятностей можно использовать среднее значение логарифма правдоподобия или оценку Бриера. Эти меры будут описаны ниже.
Во избежание переобучения необходимо, как и для других мер качества, проводить оценку на внешней выборке, а не на обучающей (по которой настраивались параметры) и валидационной (по которой настраивались гиперпараметры)!
Средний логарифм правдоподобия
Наша вероятностная модель сопоставляет каждому наблюдению вероятность пронаблюдать именно такой класс . При предположении, что объекты выборки распределены независимо, вероятность пронаблюдать ответы на всей выборке факторизуется в произведение вероятностей пронаблюдать ответ на каждом объекте выборки:
Чем выше правдоподобие [2], тем больше прогнозы модели согласуются с фактическими наблюдениями, и тем лучше модель прогнозирует вероятности классов. Поскольку произведение большого числа вероятностей будет вырождаться в машинный ноль из-за ограничения точности переменных с плавающей запятой, то на практике анализируют средний логарифм правдоподобия (log-likelihood):
Оценка Бриера
Оценка Бриера представляет собой другой популярный способ оценки качества предсказанных вероятностей с помощью функции потерь Бриера (Brier score [3]), равной среднему квадрату отклонений вектора предсказанных вероятностей от вектора истинных вероятностей по L2-норме.
Пусть - вектор предсказанных моделью вероятностей, а - вектор истинных вероятностей.
Например, если для объекта реализуется -й класс, то будет представлять собой вектор из нулей, в котором на -й позиции стоит единица.
Тогда оценка Бриера вычисляется по формуле:
Правдоподобие выборки, логарифм правдоподобия и оценка Бриера измеряют степень ошибки (чем больше, тем хуже) или качество прогноза вероятностей (чем больше, тем лучше)?
Для лучшего понимания процесса калибровки вероятностей рекомендуется ознакомиться с демонстрационным кодом [4].