Специальные меры качества для бинарной классификации
В случае бинарной классификации , а соответствующие классы называются положительными и отрицательными. Положительному классу обычно сопоставляют более редкий целевой класс, который мы стремимся обнаружить.
Например, при распознавании �болезни пациентов по симптомам положительным классом будет наличие заболевания, а отрицательным - отсутствие.
Матрица ошибок будет размера и каждый элемент этой матрицы имеет своё название:
| TP (true positives) | FN (false negatives) | |
| FP (false positives) | TN (true negatives) |
Второе слово в названии обозначает прогноз, а первое - за его корректность. Например, ложно-положительные объекты (FP штук) - это объекты, ошибочно предсказанные как положительные, в то время как истинный класс был отрицательный. А ложно-отрицательные объекты (FN штук) были предсказаны как отрицательные, в то время как на самом деле они принадлежали полож�ительному классу.
Как по значениям TP,TN,FP, FN вычислить точность и частоту ошибок классификации?
Меры качества для несбалансированных классов
Точность и полнота
В случае несбалансированных классов (unbalanced classes), когда положительный класс встречается существенно реже, чем отрицательный, предложенные меры недостаточны для оценки модели!
Например, если положительный класс встре�чается в 1% случаев, а отрицательный - в оставшихся 99%, то константный прогноз, всегда назначающий отрицательный класс, будет показывать точность 99%, а частоту ошибок - всего 1%. Однако это никак не будет свидетельствовать об адекватности модели, поскольку она даже не пыталась выделить положительный класс!
Поэтому для таких ситуаций используются специальные меры качества - точность (precision, не путать с accuracy!) и полнота (recall):
где мы использовали обозначения:
-
- общее число положительный объектов;
-
- общее число объектов, предсказанных как положительные.
Precision показывает долю верно-положительных объектов среди всех объектов, предсказанных как положительные. Например, при классификации болезни - это доля действительно больных пациентов среди всех предсказанных как больные. Precision важен, если мы хотим минимизировать число ложных срабатываний классификатора (предсказаний болезни для здоровых пациентов).
Recall показывает долю верно-положительных объектов среди всех объектов, в действительности принадлежащих положительному классу. В примере выше recall важен, если мы хотим обнаружить всех больных пациентов, пусть и с некоторой долей ложных срабатываний.
Таким образом, precision и recall измеряют различные аспекты качества модели.
F-мера
На практике важен и precision, и recall, поэтому считают их среднее гармоническое [1], называемое F-мерой (F-measure, -score):
Преимущество F-меры по сравнению с обычным усреднением заключается в том, что F-мера будет штрафовать как низкие значения precision, так и низкие значения recall одновременно. В частности, она будет равна нулю, если хотя бы один из показателей равен нулю.
Обычное же усреднение будет давать 0.5 в случае плохо настроенной модели, когда
-
Precision 1, Recall = 0 (когда только одного пациента, в болезни которого мы максимально уверены, считаем больным);
-
Precision 0, Recall = 1 (когда назначаем больными всех пациентов без разбора).
Будет ли этому свойству удовлетворять среднее геометрическое?
Да, будет, поскольку зависит от произведения этих величин.
Взвешенная F-мера
На практике точность и полнота имеют разную важность для конечной задачи. При идентификации болезни по симптомам важнее полнота (хотим отпустить минимальное число больных с диагнозом "здоров"), а в интернет-поиске важнее точность (хотим вернуть в поисковой выдаче только те страницы, которые действительно релевантны поисковому запросу, пусть и не все релевантные, поскольку их слишком много). Поэтому используется взвешенная F-мера (weighted F-measure, -score):
Более высокое значение будет повышать значение Precision и занижать вклад Recall при агрегации.
Использование мер качества в ранжировании
Классификатор часто используется не для прогнозов меток классов, а для сортировки объектов по степени уверенности модели в том, что они принадлежат положительному классу.
Например, компания в первую очередь обзванивает тех клиентов, кому спецпреложение будет максимально интересно. В информационном поиске документы соритруются от более релевантных к менее релевантным.
Поскольку каждый бинарный классификатор представим в виде:
то относительная дискриминантная функция как раз и будет служить оценкой уверенности классификатора в положительном классе для объекта , по которой можно отранжировать объекты. Рассмотрим для определённости информационный поиск, в котором по запросу пользователя возвращаются релевантные документы. В подобных задачах задают некоторый порог (предельное число докумен�тов, которые пользователь просмотрит в поисковой выдаче), после чего считают меры:
-
precision@K - долю релевантных документов среди первых в выдаче;
-
recall@K - долю показанных релевантных документов среди всех релевантных.
Далее можно по ним можно считать взвешенную F-меру. Примеры расчётов precision@K и recall@K можно прочитать в [2].
Недостатком precision@K и recall@K является то, что эти меры никак не зависят от порядка следования корректных классификаций среди представленных. А нам бы хотелось, чтобы релевантные объекты (положительного класса) шли именно в начале списка. Мерой, поощ�ряющей выдачу релевантных объектов именно в начале отранжированного списка является average precision.
Average Precision
Если варьировать K, то получим зависимость точности от полноты (precision-recall curve), пример которой приведён ниже:
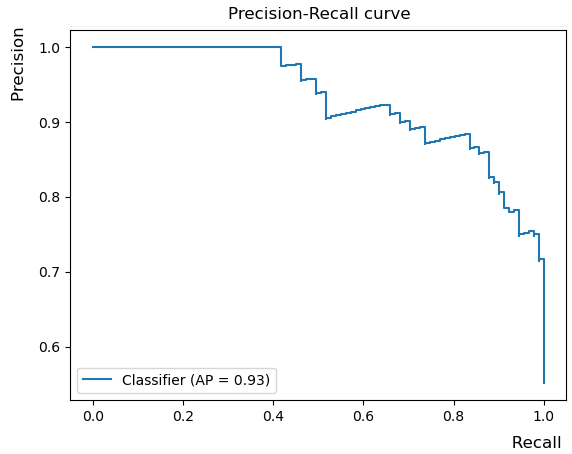
Мы бы хотели получить выше precision при каждом уровне recall, поэтому чем выше этот график, тем качественнее работает классификатор. Агрегированной мерой качества классификации служит площадь под графиком зависимости точности от полноты, которая называется Average Precision (AP). Она поощряет ситуацию, когда при ранжировании объектов по степени принадлежности положительному классу в начале списка идут именно представители положительного класса.
В случае информационного поиска это будут документы, релевантные поисковому запросу. Поскольку нас интересует качество ран�жирующей системы для разных пользователей и поисковых запросов, то величины Average Precision усредняют по пользователям и запросам, получая величину Mean Average Precision.
Пример расчёта Average Precision и Mean Average Precision можно посмотреть в [3].