Бинарная логистическая регрессия
Идея метода
Логистическая регрессия (logistic regression) - это частный случай линейной классификации, когда для оценки весов используется логистическая функция потерь.
Достоинством метода является то, что он может выдавать не только метки классов, но и их вероятности.
Для удобства обозначений включим дополнительный признак, равный тождественной единице, в число признаков:
Тогда линейный бинарный классификатор можно переписать в более компактном виде:
Эквивалентно логистическая регрессия может быть переформулирована в виде вероятностной модели, выдающей вероятность положительного класса по правилу:
где график сигмоидной функции представлен ниже:
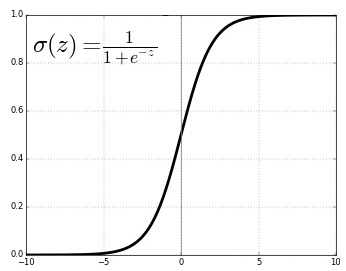
Она удовлетворяет следующему свойству:
поэтому
Таким образом, для вероятностный прогноз строится по правилу:
Оценим методом условного максимального правдоподобия:
Поскольку максимизация положительной функции эквивалентна минимизации обратной к ней, то исходная задача эквивалентна следующей:
Прологарифмировав критерий, получим классическую задачу минимизации эмпирического риска с логистической функцией потерь (logistic loss):
Пример запуска в Python
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import brier_score_loss
from sklearn.metrics import accuracy_score
X_train, X_test, Y_train, Y_test = get_demo_classification_data()
model = LogisticRegression(C=1, penalty='l2') # инициализация модели, (1/C) - вес при регуляризаторе
model.fit(X_train, Y_train) # обучение модели
Y_hat = model.predict(X_test) # построение прогнозов
print(f'Точность прогнозов: {100*accuracy_score(Y_test, Y_hat):.1f}%')
P_hat = model.predict_proba(X_test) # можно предсказывать вероятности классов
loss = brier_score_loss(Y_test, P_hat[:,1]) # мера Бриера на вероятности положительного класса
print(f'Мера Бриера ошибки прогноза вероятностей: {loss:.2f}')
Больше информации. Полный код.
Настраивать логистическую регрессию можно различными численными методами. Их сравнение приводится в [1]. В следующей главе мы рассмотрим обобщение логистической регрессии для решения задачи многоклассовой классификации.
Больше информации о логистической регрессии вы можете прочитать в [2], [[3]](Дьяконов А.Г. Машинное обучение и анализ данных: линейные классификаторы.) и [4].