Стэкинг
Алгоритм стэкинга (stacking [1]) решает задачу настройки ансамбля моделей
для общей ситуации, когда агрегирующая функция имеет свои собственные настраиваемые параметры.
Агрегирующей функции, помимо прогнозов базовых моделей, можно передавать и исходный вектор признаков . В результате получим следующую функцию предсказания:
В этом случае агрегирующая модель получит возможность по-разному использовать прогнозы базовых моделей в разных частях признакового пространства.
Базовые модели в стэкинге можно настраивать неточно, поскольку агрегирующая функция будет подправлять итоговый прогноз, учитывая ответы других моделей.
Линейный стэкинг
Простейшим примером выступает линейная комбинация базовых моделей с настраиваемыми весами .
Смещение включают, если агрегируются недообученные модели с систематическими смещениями. Если в базовых алгоритмах присутствуют переобученные модели, то они будут давать несмещенные прогнозы, и смещение можно не включать.
Настройка весов производится методом линейной регрессии, в которой признаками выступают не исходные признаковые описания объектов, а прогнозы базовых моделей.
При настройке базовых моделей и агрегирующей нельзя использовать одну и ту же обучающую выборку, иначе будет происходить переобучение!
Рассмотрим пример. Пусть среди базовых моделей присутствует алгоритм одного ближайшего соседа. Очевидно, на обучающей выборке он будет обеспечивать 100% точность, поскольку ближайшим соседом для прогнозируемых объектов обучающей выборки будут выступать они сами. Тогда, при обучении параметров базовой модели на той же обучающей выборке, всё внимание агрегирующей модели будет направлено на самую переобученную модель!
Правильная настройка стэкинга б�удет рассмотрена ниже.
Специальные виды регуляризации
Веса будут находиться неустойчиво из-за сильной корреляции признаков, которыми выступают прогнозы одной и той же целевой величины разными базовыми моделями. Чтобы повысить устойчивость оценки весов и качество всего ансамбля, необходимо использовать регуляризацию на веса. Это может быть стандартная L1- или L2-регуляризация, но в контексте решаемой задачи целесообразно использование специального регуляризатора:
который будет прижимать веса не к нулевым значениям, а к равномерному усреднению базовых моделей, что представляет естественный вид равномерного усреднения.
Дополнительно можно настраивать веса при условии их неотрицательности:
поскольку прогнозы базовых моделей должны получаться положительно скоррелированными с целевой величиной .
Стэкинг общего вида
В качестве агрегирующей модели может выступать не только линейная регрессия, но вообще любая модель: логистическая регрессия, решающее дерево или даже другой ансамбль, например, решающий лес. Теоретически можно рассмотреть даже стэки�нг над стэкингом, хотя это редко используется в связи со сложной процедурой настройки.
Настройка стэкинга
Если настраивать базовые модели и агрегирующую на одной и той же обучающей выборке, то будет происходить переобучение, вызванное тем, что базовые модели настраиваются на известные отклики, а агрегирующая повторно использует те же самые отклики. Чтобы так не происходило, можно использовать две стратегии: блендинг и стэкинг с кросс-валидацией.
Блендинг
В блендинге настройка базовых моделей и агрегирующей производится на двух разных выборках объектов, как показано на схеме:
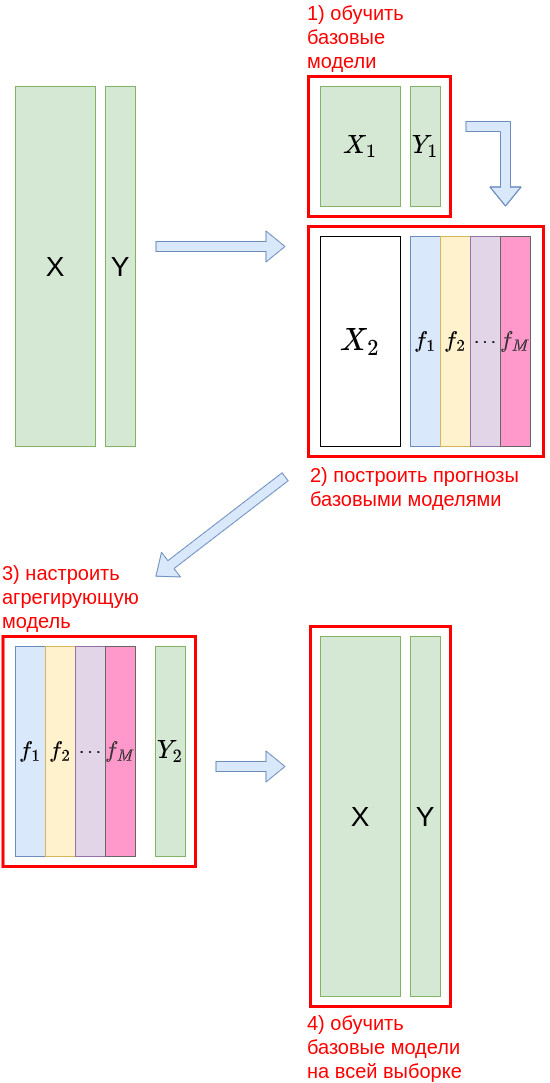
Формально последовательность действий записывается следующим образом:
-
Разбить обучающую выборку на две случайные подвыборки и размера и .
-
Обучить базовые модели на .
-
Предсказать объекты выборки каждой базовой моделью, в результате чего получить матрицу прогнозов базовыми моделями .
-
На обучающей выборке обучить агрегирующую модель .
-
Донастроить базовые модели на всей обучающей выборке .
Последний шаг не приводит к переобучению и опционален. Без него агрегирующая модель максимально согласуется с базовыми, поскольку именно на них она настраивалась. Если же использовать последний шаг, то базовые модели получаются лучше настроенными (используя все наблюдения, а не часть), но будут хуже сочетаться с агрегирующей функцией, которая использовала их настройк�у на подвыборке , а не на всей выборке.
Обучающая выборка разбивается на первую и вторую выборку в пропорции примерно 80/20%, поскольку в стэкинге основная тяжесть прогнозирования ложится на базовые модели, а агрегирующей модели остаётся лишь оптимальным образом скомбинировать уже имеющиеся прогнозы.
Стэкинг с кросс-валидацией
Недостаток блэндинга заключается в том, что при настройке агрегирующей модели используются не все объекты, а лишь их подмножество, оказавшееся во второй выборке, что приводит к недостаточно точной настройке .
Повысить точность позволяет стэкинг с кросс-валидацией - это и есть алгоритм стэкинга по умолчанию.
Последовательность действий при настройке с кросс-валидацией будет следующей:
-
Разбить обучающую выборку на случайных подвыборок одинакового размера (состоящие из объектов).
-
Для :
-
настроить базовые модели на всех подвыборках кроме -ой, получив их настроенные версии ;
-
спрогнозировать с помощью объекты исключённой -й выборки, получив матрицу прогнозов .
-
-
Объединить все подвыборки прогнозов в одну .
-
Добавить к небольшой случайный шум.
-
На выборке настроить агрегирующую модель .
-
Обучить базовые модели на всей выборке .
Последний шаг нужен для замены версий каждой базовой модели одной финальной.
Настройка агрегирующей модели корректна, поскольку основывается на честных вневыборочных прогнозах базовыми моделями на тех объектах, которые они не использовали при обучении. Настройка производится весьма точно, поскольку задействуются все объектов исходной выборки.
Поскольку на втором шаге для каждой подвыборки настраивается своя версия каждой базовой модели, объединять напрямую их прогнозы не совсем правильно - это будут прогнозы, сделанные немного отличающимися моделями. Для их выравнивания используется шаг 4, на котором к прогнозам базовых моделей добавляется случайный шум с небольшой дисперсией (гиперпараметр метода).
Вместо шага 6, на котором происходит перенастройка базовых моделей на всей обучающей выборке, для нового объекта можно строить прогноз каждой версией всех базовых моделей, полученных на шаге 2. То есть построить прогнозов моделями для . Затем нужно для каждой версии базовых моделей провести агрегирование их прогнозов и усреднить по версиям:
Это в раз замедляет построение прогноза, но может обеспечивать более высокую точность на некоторых типах данных.
Пример запуска в Python
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import StackingClassifier
from sklearn.metrics import accuracy_score
from sklearn.metrics import brier_score_loss
X_train, X_test, Y_train, Y_test = get_demo_classification_data()
# Инициализируем базовые модели и проверим их качество
knn = KNeighborsClassifier(n_neighbors=100) # инициализация модели
knn.fit(X_train, Y_train) # обучение модели
Y_hat = knn.predict(X_test) # построение прогнозов
print(f'Точность прогнозов: {100*accuracy_score(Y_test, Y_hat):.1f}%')
tree_model = DecisionTreeClassifier() # инициализация дерева
tree_model.fit(X_train, Y_train) # обучение модели
Y_hat = tree_model.predict(X_test) # построение прогнозов
print(f'Точность прогнозов: {100*accuracy_score(Y_test, Y_hat):.1f}%')
# Инициализируем стэкинг
ensemble = StackingClassifier(estimators=[('K nearest neighbors', knn), # базовые модели
('decision tree', tree_model)],
final_estimator=LogisticRegression(), # агрегирующая модель
cv=3, # количество блоков кросс-валидации при настройке стэкинга
n_jobs=-1) # используем все ядра процессора для настройки
ensemble.fit(X_train, Y_train) # обучение базовых моделей` ансамбля
Y_hat = ensemble.predict(X_test) # построение прогнозов
print(f'Точность прогнозов: {100*accuracy_score(Y_test, Y_hat):.1f}%')
P_hat = ensemble.predict_proba(X_test) # можно предсказывать вероятности классов
loss = brier_score_loss(Y_test, P_hat[:,1]) # мера Бриера на вероятности положительного класса
print(f'Мера Бриера ошибки прогноза вероятностей: {loss:.2f}')
Больше информа�ции. Полный код.
from sklearn.neighbors import KNeighborsRegressor
from sklearn.tree import DecisionTreeRegressor
from sklearn.linear_model import Ridge
from sklearn.ensemble import StackingRegressor
from sklearn.metrics import accuracy_score
from sklearn.metrics import brier_score_loss
X_train, X_test, Y_train, Y_test = get_demo_classification_data()
# Инициализируем базовые модели и проверим их качество
knn = KNeighborsRegressor(n_neighbors=100) # инициализация модели
knn.fit(X_train, Y_train) # обучение модели
Y_hat = log_model.predict(X_test) # построение прогнозов
print(f'Средний модуль ошибки (MAE): {mean_absolute_error(Y_test, Y_hat):.2f}')
tree_model = DecisionTreeRegressor() # инициализация дерева
tree_model.fit(X_train, Y_train) # обучение модели
Y_hat = tree_model.predict(X_test) # построение прогнозов
print(f'Средний модуль ошибки (MAE): {mean_absolute_error(Y_test, Y_hat):.2f}')
# Инициализируем стэкинг
ensemble = StackingRegressor(estimators=[('K nearest neighbors', knn), # базовые модели
('decision tree', tree_model)],
final_estimator=Ridge(), # агрегирующая модель
cv=3, # количество блоков кросс-валидации при настройке стэкинга
n_jobs=-1) # используем все ядра процессора для настройки
ensemble.fit(X_train, Y_train) # обучение базовых моделей ансамбля
Y_hat = ensemble.predict(X_test) # построение прогнозов
print(f'Средний модуль ошибки (MAE): {mean_absolute_error(Y_test, Y_hat):.2f}')
Больше информации. Полный код.