Латентный семантический анализ
Методы, основанные на совстречаемости слов, выдают эмбеддинги длины (число уникальных слов словаря). При раздельном учёте левого и правого контекста эмбеддинг будет размера . Поскольку число уникальных слов велико, то эмбеддинги будут получаться очень длинными, а работа с такими длинными эмбеддингами будет неэффективной, поскольку
-
потребуется много вычислений,
-
полученная перепараметризованная модель будет переобучаться.
Поэтому после получения высокоразмерного эмбеддинга его сжимают до значительно более низкой размерности .
Усечённое сингулярное разложение
Для этого к матрице совстречаемости применяют усечённое сингулярное разложение (truncated singluar values decomposition, truncated SVD [1]), являющееся наиболее точным низкоранговым приближением исходной матрицы по норме Фробениуса [2]:
где обозначает единичную матрицу размера , а - диагональную с элементами , называемыми сингулярными числами (singluar values).
Размеры соответствующих матриц: , а является выбираемым гиперпараметром.
Чем выше, тем приближение �матрицы будет менее экономичным, зато более точным. Безошибочная точность достигается, когда больше либо равна ранга матрицы .
Графически сингулярное разложение можно представить следующим образом (рядом с каждой матрицей указан её размер):
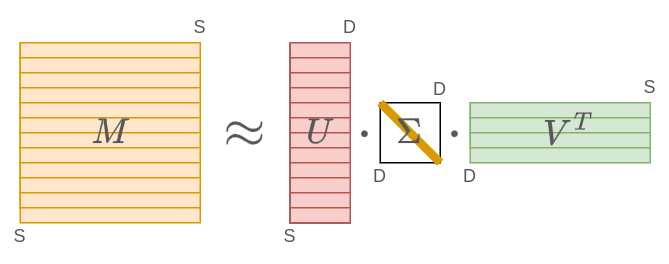
Интуиция сингулярного разложения
В методах совстречаемости -му слову соответствует -й полноразмерный эмбеддинг в виде -й строки матрицы . Из сингулярного разложения следует, что все эмбеддинги представляются линейной комбинацией строк матрицы . Можно показать, что это первые главных компонент [3] для эмбеддингов всех слов. Интуитивно эти строки показывают основные темы или высокоуровневые смысловые концепции, линейно комбинируя которые, можно получить эмбеддинг любого слова с высокой точностью.
Например, при анализе новостей такими концепциями могут быть темы политики, экономики, спорта, культуры и т.д.
-й элемент матрицы будет весом, на который домножается каждая тема. По смыслу этот коэффициент показывает важность темы для восстановления полноразмерных эмбеддингов (состоящих из всех слов).
А -ая строка матрицы будет обозначать коэффициенты, с которыми каждую из тем нужно сложить/вычесть, чтобы (приближённо) получить исходный полноразмерный эмбеддинг.
Построение низкоразмерных эмбеддингов
Чтобы эффективно представить -ое слово, достаточно перейти от его полноразмерного эмбеддинга к сокращённому - -й строке матрицы .
По сути при этом мы перейдём от описания слова по контекстным словам, с которыми оно часто встречается, к его описанию в терминах семантически высокоуровневых тем, к которым оно принадлежит. Такой подход называется латентным семантическим анализом (Latent Semantic Analysis, LSA).
Более часто подход LSA используется не для построения эмбеддингов слов, а для построения эмбеддингов документов:
-
Каждый документ представляется -мерным эмбеддингом по тому, насколько часто в нём встречается каждое слово языка (в виде счётчиков встречаемости, частоты встречаемости либо TF-IDF [4] представления).
-
Эти эмбеддинги конкатенируются в матрицу , где - число документов.
-
Далее точно так же к матрице применяется метод LSA, в результате которого каждый документ кодируется уже сокращенным -мерным эмбеддингом, представляющим собой степени представленности каждой темы уже не в слове, а в документе среди тем, заданных строками матрицы .
Пока мы изучили построение эмбеддингов слов методами классического машинного обучения. Далее мы изучим нейросетевой подход Word2vec для построения эмбеддингов слов, а также нейросетевой метод для построения эмбеддингов целых параграфов в тексте.