Эмбеддинги параграфов
Ранее мы рассматривали методы построения эмбеддингов слов. Однако c помощью эмбеддингов можно представлять не только отдельные слова, но и целые фрагменты текста, такие как предложения, параграфы или даже документы. Это позволяет обрабатывать фрагменты нейросетями и другими моделями машинного обучения целиком, учитывая их совокупную семантику как целого (а не по смыслу отдельных слов, которые могут идти в разном порядке, меняя смысл фрагмента).
Вспомним классическое:
"казнить, нельзя помиловать"
"казнить нельзя, помиловать".
Для определённости будем рассматривать случай параграфов, хотя те же методы применимы, когда мы делим текст на предложения, главы и документы. Задача состоит в том, чтобы каждому известному параграфу обучающей выборки сопоставить его эмбеддинг .
Полученные эмбеддинги можно потом использовать для классификации параграфов (определение темы параграфа), нахождения параграфов, являющихся переформулировками друг друга, создания поисковой системы по параграфам и т.д.
В работе [1] предложено кодировать параграфы эмбеддингами двумя методами: PV-DM и PV-DBOW.
PV-DM
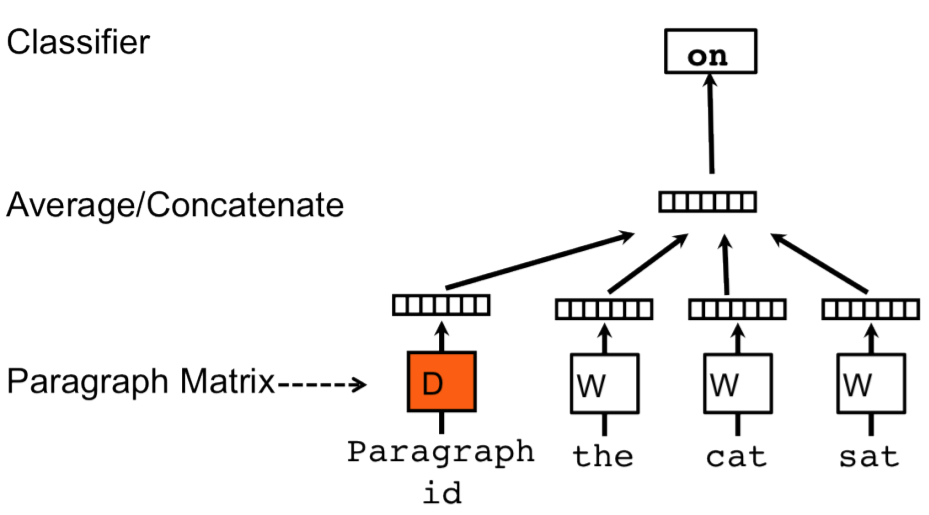
Метод PV-DM (Distributed Memory Model of Paragraph Vectors [1]) оценивается точно так же, как метод CBOW для слов, но центральное слово скользящего окна предсказывается по среднему от эмбеддингов окружающих его слов и эмбеддингу параграфа , в котором это слово находится.
Для этого можно:
-
строить эмбеддинг известного контекста, усредняя не только по эмбеддингам соседних слов, но и по эмбеддингу параграфа;
-
конкатенировать эмбеддинг параграфа к эмбеддингу, построенному как среднее соседних известных слов контекста.
Графически это можно представить в следующем виде [1]:
PV-DBOW
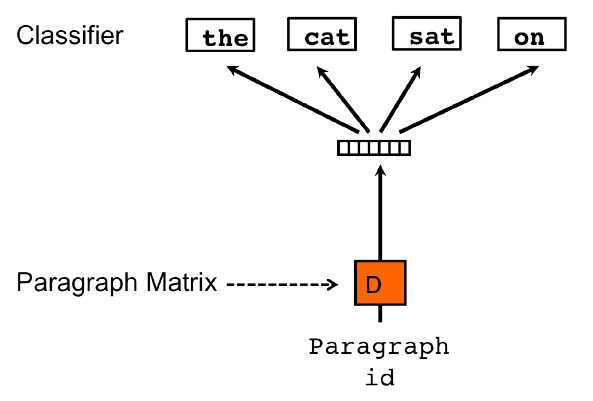
Метод PV-DBOW (Distributed Bag of Words version of Paragraph Vector [1]) работает точно так же, как Skip-Gram для слов: обучающий текст обрабатывается скользящим окном, но на этот раз
-
предсказываются все слова окна (то есть и центральное слово окна тоже);
-
контекстом выступает не центральное слово, а параграф, содержащий слова окна.
Графически это визуализировано ниже [1]:
Обратим внимание, что для построения эмбеддингов параграфа этот параграф должен быть известен заранее в обучающем тексте. Модель будет полезна, когда мы хотим создать поисковую систему по документам электронной библиотеки из заранее известных документов. Но мы не сможем её применить для поиска по новым документам.
Для генерации эмбеддингов для новых текстов нужно либо дообучать под них уже настроенную модель, либо использовать другие методы построения эмбеддингов, например, используя рекуррентные нейросети.