Оптимизация Skip-Gram
Для качественной настройки эмбеддингов слов в модели Skip-Gram её нужно настраивать на гигантских коллекциях текстовых данных (100 миллионов слов и больше). Это связано с вычислительными трудностями, поскольку при расчёте вероятностей каждого слова приходится вычислять знаменатель следующей дроби:
равный сумме величин для всех уникальных слов языка , а их очень много!
Поэтому для ускорения настройки Skip-Gram используются специальные вычислительно эффективные методы - иерархический SoftMax либо негативное сэмплирование [1].
В модели CBOW присутствует такая же проблема, и для её оптимизации используются свои усовершенствованные методики оптимизации. Здесь они не рассматриваются, так как на практике в основном используется Skip-Gram как более эффективное решение, поскольку в нём известный контекст вычисляется по одному слову, а не по совокупности.
Иерархический SoftMax
В методе Hierarchical SoftMax [1] строится бинарное дерево, каждому листу которого ставится в соответствие уникальное слово языка. Таким образом, в дереве будет листов, а если его строить сбалансированным (так, что расстояние до каждого листа одно и то же), то его глубина будет .
Ниже приведён пример такого дерева:
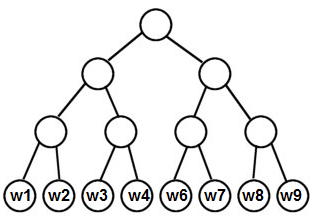
Вместо выходных эмбеддингов каждого слова вычисляются выходные эмбеддинги для каждого внутреннего узла бинарного дерева.
Пусть нам нужно посчитать вероятность . Эту вероятность можно посчитать не за , а за , осуществляя спуск по бинарному дереву от корня до предсказываемого слова .
Вероятности из каждого узла перейти в левого и правого потомка задаются по правилам:
где - сигмоидная функция, а целевая вероятность считается как произведение этих вероятностей при спуске от корня до слова .
После настройки Skip-Gram этим методом в конечном итоге используются входные эмбеддинги слов , поскольку выходные эмбеддинги соответствуют не словам, а узлам дерева.
Метод Hierarchical SoftMax можно дополнительно ускорить, строя не сбалансированное дерево, а несбалансированное дерево Хаффмана [2], которое более частым словам будет назначать более короткие пути на дереве от корня до соответствующего листа. В результате спуск по дереву для самых частых слов (таких, как стоп-слова) будет максимально коротким и быстрым!
Негативное сэмплирование
Метод негативного сэмплирования (negative sampling [1]) представляет собой альтернативный подход к настройке Skip-Gram модели. В нём для известного слова и предсказываемого максимизируется не логарифм вероятности , а другая суррогатная, зато быстро вычислимая функция.
Как и раньше, мы сканируем текст скользящим окном. Для каждого положения окна и известного слова в его центре, а также для предсказываемого соседнего слова сэмплируется случайных слов , после чего производится одна итерация оптимизационного алгоритма, максимизирующего следующий критерий:
Гиперпараметр берётся из диапазона 2-10.
Первое слагаемое сближает эмбеддинги слов, которые являются соседями, а второе - раздвигает эмбеддинги выбранного слова и случайных слов, которые (в общем случае) не попали в его контекст.
Случайные слова можно сэмплировать из априорного распределения:
то есть из вероятности встречи каждого слова в тексте самого по себе. Однако поскольку распределение слов сильно неравномерное (например, стоп-слова встречаются гораздо чаще остальных), то при таком методе методе сэмплирования будут в основном использоваться только часто встречаемые слова (такие, как стоп-слова)!
Для того, чтобы сэмплирование слов оказывалось более разнообразным, слова сэмплируются из распределения .
Метод негативного сэмплирования является более распространённым, чем иерархический SoftMax, поскольку одна его итерация работает за , а не за , а можно выбрать небольшим (). При этом оба метода обеспечивают примерно одинаковое качество итоговых эмбеддингов.