Word2vec
Методы построения эмбеддингов слов, описанные ранее, основаны на вычислении счётчиков совстречаемости слов и применения к ним сингулярного разложения.
Одним из первых очень популярных нейросетевых методов построения эмбеддингов является Word2vec [1], [2], представляющий собой две модели: Skip-Gram и CBOW.
Обе модели анализируют текст, составленный из большого количества документов, о�бъединённых в одну длинную последовательность слов.
В классической реализации документы просто объединялись, но если необходимо явно обозначить границы между документами, то каждый документ перед объединением можно дополнить токеном START раз в начале и токеном STOP раз в конце, где - гиперпараметр, определяющий ширину контекста.
После объединения все документы представляют собой последовательность слов
состоящую из уникальных слов (возможно, дополненных спец. токенами START и STOP).
Skip-Gram и CBOW представляют собой языковые модели (language models), то есть модели, предсказывающие часть текста по другой части текста. В них текст сканируется скользящим окном из соседних слов с центром в слове , , как показано для примера ниже:
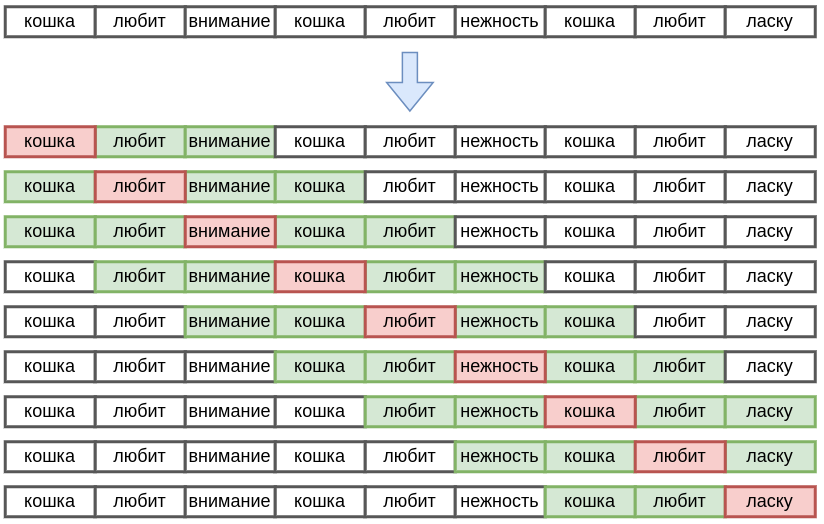
Каждое слово этих моделей может выступать в двух ролях:
-
когда слово известно, и по нему нужно предсказывать другое слово;
-
когда слово предсказывается по соседним словам.
Поэтому каждому слову ставится в соответствие два настраиваемых эмбеддинга:
-
- входной эмбеддинг (когда слово известно);
-
- выходной эмбеддинг (когда слово предсказывается по соседям).
Размерность эмбеддингов берётся равной примерно 300.
В моделях настраиваются параметры , представляющие собой все входные и выходные эмбеддинги для каждого слова:
Конечной целью настройки языковых моделей является не прогнозирование слов само по себе, а настроенные эмбеддинги слов, которые затем используются в других задачах анализа текста, используя трансферное обучение.
Skip-Gram
В методе Skip-Gram модель по известному центральному слову окна (контексту) учится предсказывать соседние слова в этом окне для каждого положения скользящего окна:
Слово считается более сочетаемым с контекстным словом , если скалярное произведени�е их эмбеддингов выше, поэтому вероятность появления слова в контексте другого считается через SoftMax-преобразование от скалярных произведений:
Результатом настройки Skip-Gram являются входные эмбеддинги каждого слова . Можно было бы использовать и выходные эмбеддинги, но, как будет ясно из методов ускоренной настройки Skip-Gram, они играют вспомогательную, а не основную роль.
CBOW
В методе CBOW модель по соседним словам окна учится предсказывать центральное слово:
Здесь - общая длина текста, а - настраиваемые параметры.
Таким образом, в CBOW известным контекстом выступают соседние слова вокруг слова .
Информация о соседних словах представляется в виде контекстного эмбеддинга, вычисляемого как сумма входных эмбеддингов этих слов:
Слово считается более сочетаемым с контекстом, если скалярное произведение его эмбеддинга с эмбеддингом контекста выше, поэтому вероятность предсказываемого центрального слова считается через SoftMax-преобразование от скалярных произведений:
Результатом настройки CBOW являются выходные эмбеддинги каждого слова , несущие семантическую информацию о каждом отдельном слове. Входные эмбеддинги же менее информативны, поскольку используются не сами по себе, а в контексте других соседних слов.
Регулярности в эмбеддингах
Простота моделей Skip-Gram и CBOW позволила их обучить на гигантских коллекциях текстов из интернета и получить эмбеддинги, качественно отражающие смысл (семантику) этих слов.
Например, на сайте http://epsilon-it.utu.fi/wv_demo/ можно задать слово и получить наиболее похожие на него другие слова в пространстве эмбеддингов Word2Vec при сравнении по косинусной мере близости. Можно убедиться, что близким словам действительно соответствуют слова близкие по смыслу, например:
| слово | близкие слова |
|---|---|
| student | teacher, faculty, school, university |
| car | truck, jeep, vehicle |
| country | nation, continent, region |
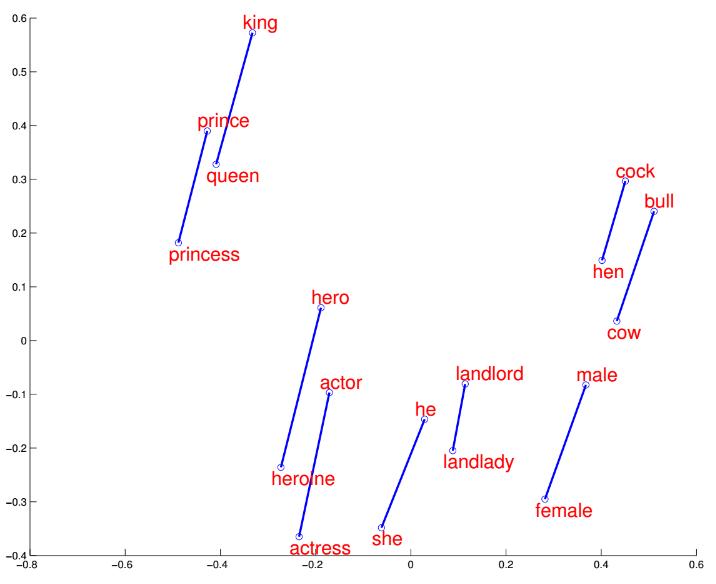
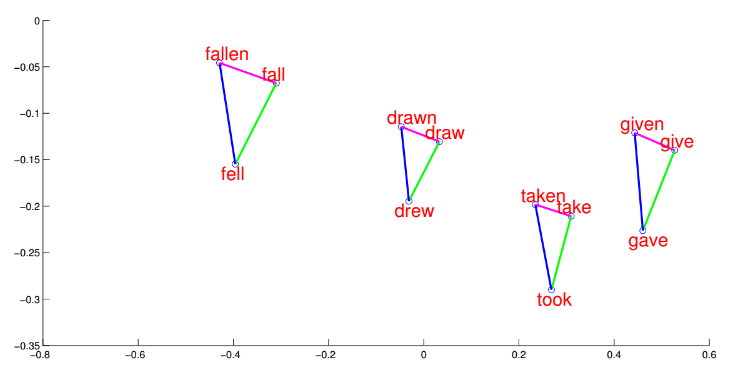
Примечательно, что связь между эмбеддингами слов оказалась приближённо линейной, например:
При отображении эмбеддингов слов в двумерном пространстве с помощью метода главных компонент эти линейные связи также хорошо видны [3]:
FastText
Эмбеддинги, настроенные методом Word2Vec, будут известны только для тех слов, которые хотя бы раз встретились в обучающей текстовой коллекции. При этом на практике в языке постоянно появляются новые слова, а известные слова часто пишутся с опечатками (например, в поисковой системе). Чтобы строить эмбеддинги для новых слов и слов с опечатками, в методе FastText [4] предложено представлять каждое слово в виде эмбеддинга не само по себе, а как сумму его n-грамм, то есть групп из подряд идущих символов, которые встретились в слове.
При этом для того, чтобы обозначить начало и конец слова, слово дополняется спец. символами:
-
[ - начало слова;
-
] - конец слова.
Например, при построении 3-грамм слова "person", оно вначале будет представлено как "[person]", а затем из него уже будут извлечены соответствующие 3-граммы: "[pe","per","ers","rso","son","on]".
Входной эмбеддинг слова заменяется на сумму эмбеддингов составляющих это слово n-грамм:
В fastText рассматривались n-граммы с , а также в число n-грамм включалось всё слово целиком.
При предсказываемое слово задаётся единственным эмбеддингом всего слова, как в модели SkipGram.
При применении fastText, если модель увидит новое слово или старое, но зап�исанное с опечаткой, она всё равно сможет сопоставить ему эмбеддинг как сумму входных эмбеддингов от составляющих это слово n-грамм, которые уже встречались в других словах.
Настройка FastText вычислительно сложнее настройки SkipGram, поскольку нужно настраивать не только эмбеддинги слов, но и эмбеддинги составляющих их n-gram. В целях оптимизации памяти в статье предлагалось отображать в эмбеддинги не каждую n-грамму, а каждое хэш-значение n-граммы. Для этого все n-граммы отображались в редуцированный набор значений, используя хэш-функцию. А эмбеддинги строились не для всех n-грамм, а только для всех выходных значений хэш-функции.
FastText настраивается точнее SkipGram за счёт более точного учёта морфологии слов, поскольку даже если само слово встречается в обучающем тексте редко, то составляющие его n-граммы встречаются гораздо чаще.
Например, модель SkipGram обрабатывает слова run, running, runned, runner как независимые слова. Их общность воссоздаётся лишь за счёт похожих контекстов. Модель FastText же сразу увидит схожесть этих слов за счёт общего корня run.
Литература
- Mikolov T. Efficient estimation of word representations in vector space //arXiv preprint arXiv:1301.3781. – 2013. – Т. 3781.
- Mikolov T. et al. Distributed representations of words and phrases and their compositionality //Advances in neural information processing systems. – 2013. – Т. 26.
- Yu Su lectures: word embeddings.
- Bojanowski P. et al. Enriching word vectors with subword information //Transactions of the association for computational linguistics. – 2017. – Т. 5. – С. 135-146.