Моделирующие способности нейросети
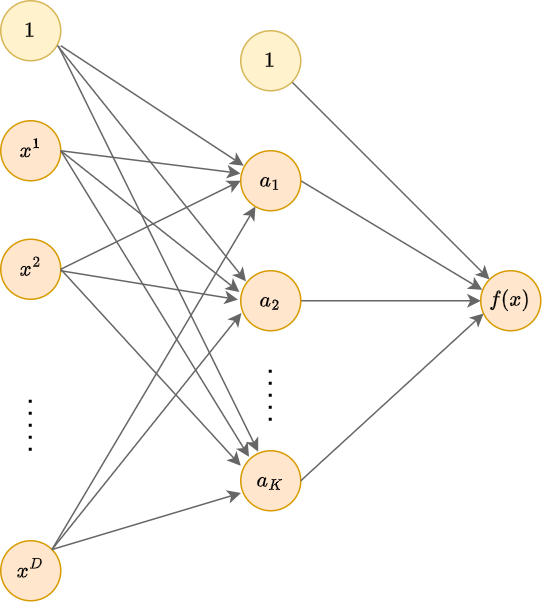
Двухслойный персептрон
Сколько слоёв достаточно для моделирования произвольной регрессионной или классификационной зависимости? Теоретические результаты в статьях [1-4] показывают, что двухслойная нейросеть является универсальным аппроксиматором, то есть способна приблизить любую регулярную зависимость для широкого класса функций активации, включая все изученные, кроме тождественной.
В частности, в статье [2] доказывается теорема:
Теорема (Цыбенко, 1989): для любой непрерывной функции и для любого найдётся число , вектора и числа , , для которых
для любых объектов из единичного куба: .
Таким образом, двухслойной сети с сигмоидными функциями активации достаточно, чтобы с любой заданной точностью моделировать любую непрерывную функцию в ограниченной (компактной) области. Аналогичные утверждения справедливы и для других изученных нелинейных функций активации.
В этом можно убедиться на практике, моделируя, например, следующую целевую функцию:
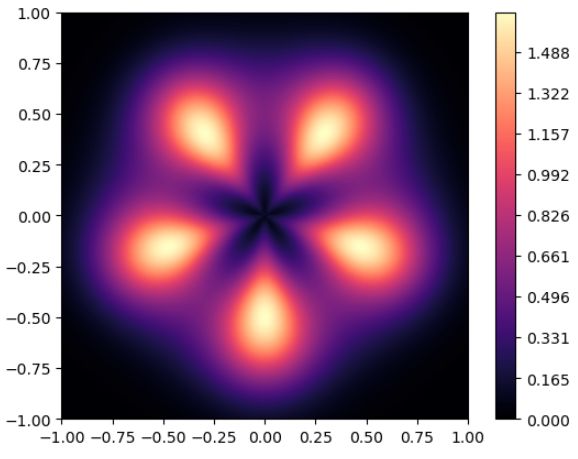
Попробуем её приближать с помощью двухслойного персептрона c нейронами на скрытом слое, использующим активации LeakyReLU:
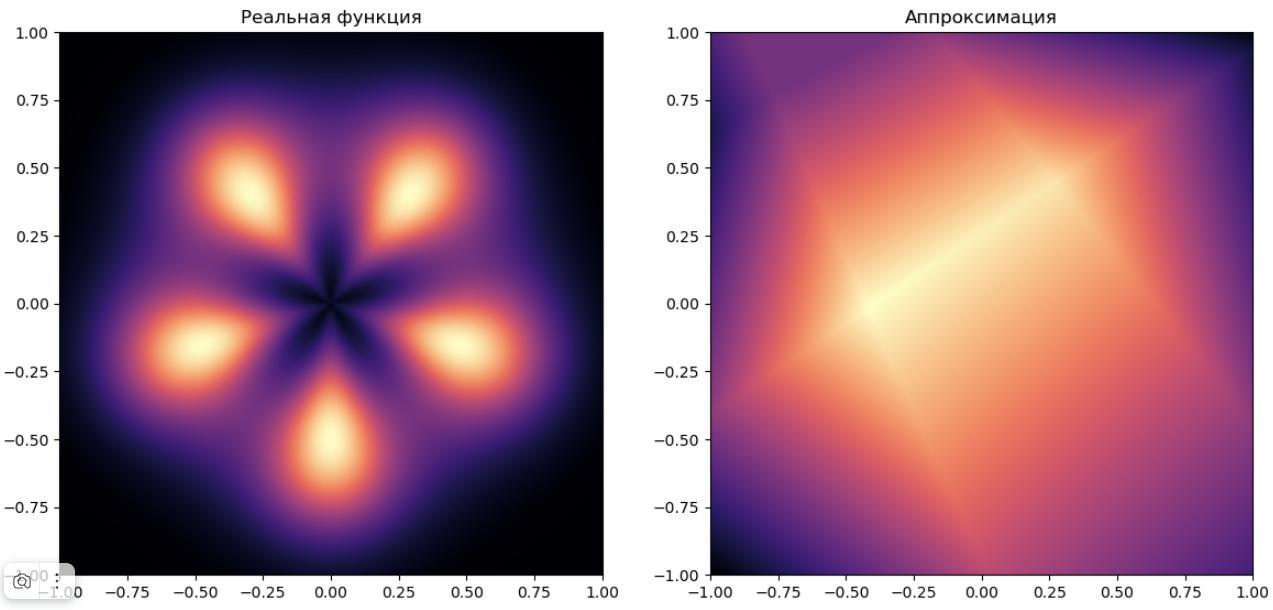
При (у модели будет 21 параметр) получаем не очень точную аппроксимацию:
При K=50 (у модели уже 201 параметр) качество аппроксимации вырастает:
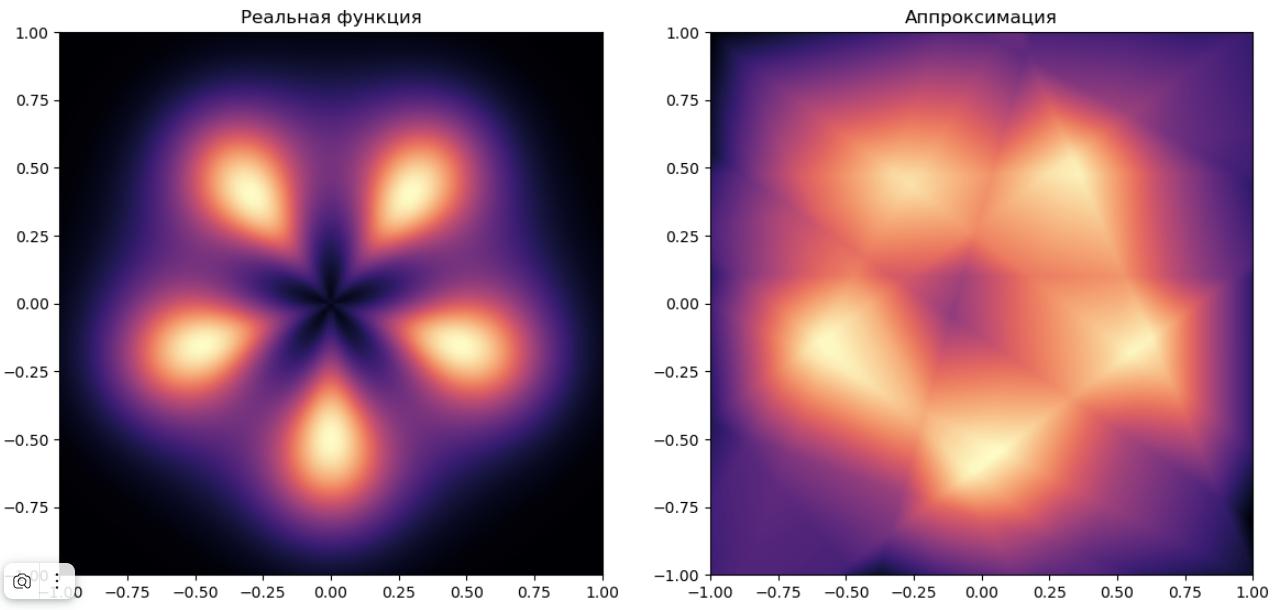
При (60001 параметр) получим очень высокое качество:
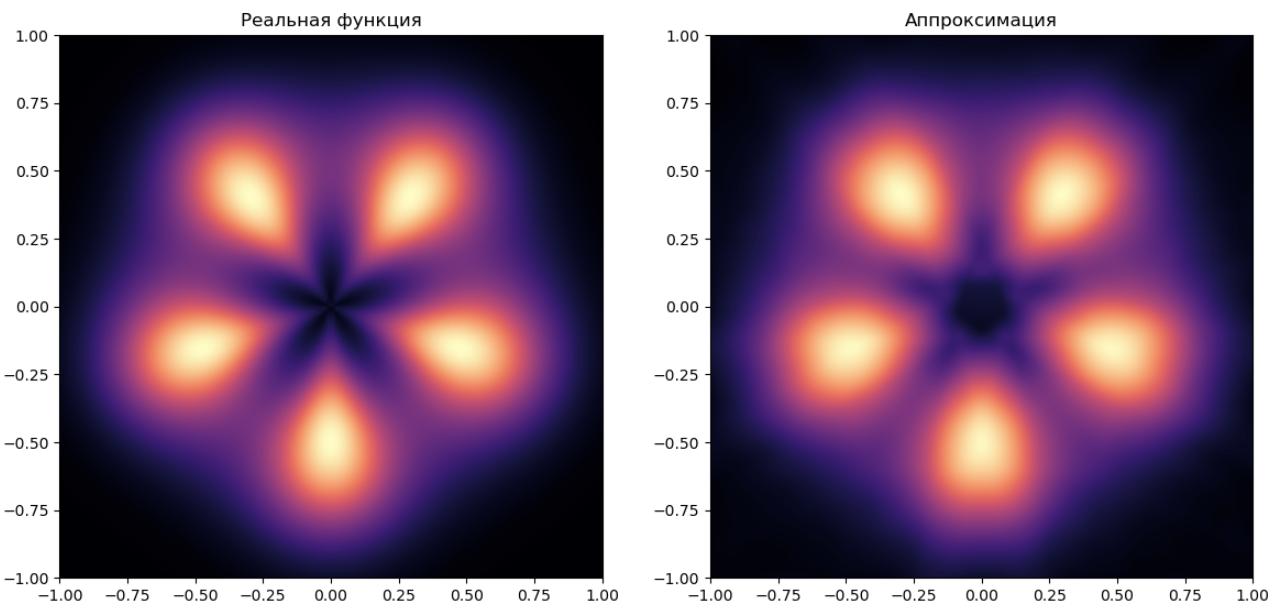
Оно всё же пока неидеальное (см. аппроксимацию чёрной звезды в центре изображения), но может и дальше улучшаться за счёт дальнейшего повышения числа нейронов в скрытом слое .
Глубокие нейросети
Применим принцип глубокого обучения, когда признаки автоматически настраиваются для итоговой прогностической модели. Для этого применим 5-слойный персептрон с 360, 80, 20, 5, 1 нейронами на слоях и активациями LeakyReLU (кроме выходного слоя с тождественной активацией).
Получим ещё более качественную аппроксимацию:
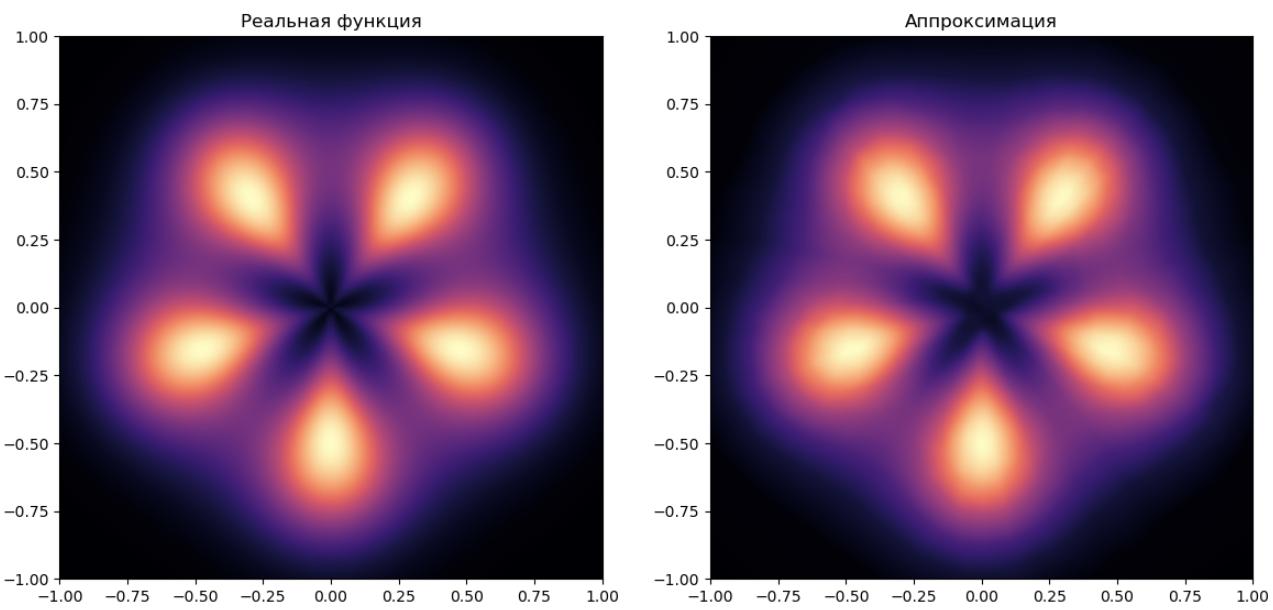
Визуально видно, что чёрная звезда в центре аппроксимируется лучше.
По формальным критериям (RMSE) качество выросло более, чем в 3 раза, при этом в модели настраивался всего 31691 параметр - почти в 2 раза меньше, чем в двухслойном персептроне с максимальным числом нейронов!
Это объясняется тем, что если неглубокой сети приходилось генерировать много простых признаков (грубо говоря, выделяющих полуплоскости), то в глубокой сети признаки получаются более сложными, за счёт чего исходную функцию удалось качественно приблизить меньшим числом таких признаков. Также в неглубокой сети простые признаки комбинировались лишь линейно, в то время как в глубокой сети высокоуровневые признаки нелинейно переиспользовались много раз. Это позволило описать сложную закономерность более экономично с меньшим числом параметров!
Извлечение сложных высокоуровневых признаков, позволяющих компактно описать сложные зависимости в данных, называется обучением представлений (representation learning).
Построение архитектуры, выделяющей качественные промежуточные представления для решения смежных задач, представляет собой отдельное направление исследований.