Модель нейрона
Нейронные сети (neural networks) изначально появились как попытка моделировать работу человеческого мозга, который состоит из нейронов, связанные друг с другом аксонами - вытянутыми отростками нервных клеток. Каждый нейрон может перейти в возбуждённое состояние, в этом случае он передаёт по аксонам сигнал другим нейронам посредством электро-химического взаимодействия.
Нейрон (neuron) моделируется следующим преобразованием:
где
-
- выход нейрона (что он посылает по аксонам другим нейронам);
-
- нейрон, всегда выдающий константу 1;
-
- нейроны, имеющие входящую связь с рассматриваемым нейроном;
-
- веса связей;
- они показывают, во сколько раз изменяется сигнал, передаваемый нейронами текущему нейрону ;
-
- некоторая фиксированная функция активации (activation function).
Геометрически это можно представить следующим образом:
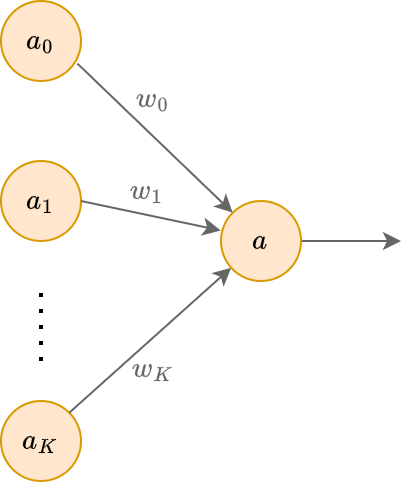
Модель нейрона в машинном обучении
В машинном обучении нейрон можно применять как прогнозирующую модель. Тогда вместо активаций нейронов предыдущего слоя на вход нейрону подаваться исходные признаки, а также константа 1:
Напомним, что в учебнике признаки обозначаются верхним индексом: - -й признак вектора признаков. А - -й объект обучающей выборки.
Одиночный нейрон будет моделировать закономерность:
где параметр называется смещением (bias).
Веса представляют собой параметры, настраиваемые по данным. В зависимости от того, как выбрать функцию активации, мы сможем решать как задачу регрессии, так и задачу бинарной классификации.
Регрессия
Регрессия получается при выборе . Тогда
Бинарная классификация
Классификация получается при выборе сигмоидной функции активации:
Эта функция принимает значения на интервале , поэтому её можно трактовать как вероятность положительного класса:
Тогда вероятность отрицательного класса можно посчитать как
Это даёт нам нейросетевую реализацию бинарной логистической регрессии.