Обобщающая способность модели
После настройки параметров модели на обучающей выборке (training set) , нам бы хотелось оценить, насколько хорошо она будет работать на новых данных - тестовой выборке (test set) , т.е. оценить так называемую обобщающую способность (generalization ability) - способность модели успешно экстраполировать выученные зависимости при обучении. Ведь именно для этого мы и настраивали модель!
Тут важно помнить, что эмпирический риск на обучающей выборке не будет репрезентативно отражать эмпирический риск на новых данных, и в общем случае мы будем наблюдать, что , поскольку выбиралась так, чтобы минимизировать ошибки именно на обучающих данных , но не новых. Мы лишь надеемся, что новые данные будут распределены примерно так же, как в обучающей выборке.
Чем более сложная (гибкая, с большим числом параметров) у нас модель, тем легче ей подстроиться под обучающую выборку и тем меньше будет , однако это далеко не всегда будет приводить к снижению ! Например, мы решаем задачу линейной регрессии по одномерному признаку и отклику . Управлять сложностью получаемой модели можно за счет поиска линейной зависимости не только от , но и от квадрата признака , куба признака и так далее до определённой степени . Тогда наша модель будет иметь вид:
и будет моделировать множество всевозможных полиномиальных зависимостей от . Выбирая различные , мы будем управлять сложностью получаемой модели. На рисунке ниже обучающая выборка в осях показана точками, а прогнозы модели при различных показаны пунктирной линией. Видно, что малое (слева) будет приводить к линейной зависимости, которая слишком проста для реальной зависимости в данных, что соответствует недообученной модели (underfitted model), в то время как при высоком (справа) зависимость получается сложнее реальной зависимости и приводит к переобученной модели (overfitted model). Промежуточное приводит к модели, сложность которой примерно соответствует сложности реальных данных.
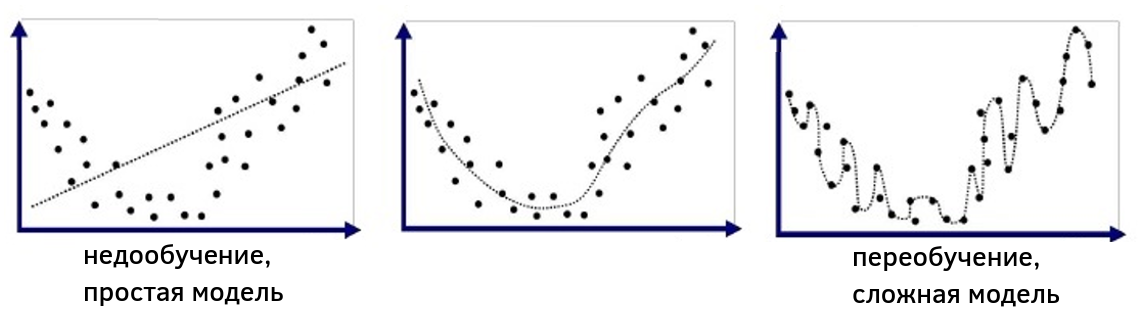
Более формально понятия недообученных и переобученных моделей будут рассмотрены в отдельном разделе учебника.
Гиперпараметры моделей
Такой параметр, как в примере, который не настраивается на обучающей выборке (как вектор весов ), а выбирается пользователем, называется гиперпараметром (hyperparameter).
Подумайте, почему K нельзя настраивать на обучающей выборке?
Такой способ настройки будет всегда поощрять более гибкую модель с большим значением K.
В частности, при K>=N-1 модель будет иметь как минимум столько же настраиваемых параметров, сколько объектов в выборке, и сможет обеспечить безошибочные прогнозы на всех объектах обучающей выборки, но не на новых тестовых объектах!
У большинства моде�лей машинного обучения есть гиперпараметр, отвечающий за сложность модели. Важно тщательно настроить этот гиперпараметр, чтобы сложность модели соответствовала сложности реальной зависимости в данных.
Если модель будет слишком простой, то она будет показывать недостаточную точность из-за того, что у неё не хватает выразительной способности описать реальную зависимость.
Если же модель будет слишком сложной, то она начнёт перенастраиваться на особенности реализации обучающей выборки (которая случайна в силу случайного отбора объектов в неё) вместо подгонки под реальную зависимость, что также негативно повлияет на её обобщающую способность на тестовых данных. Детальнее недообученные и переобученные модели будут описаны в отдельном разделе книги.
Вы также можете прочитать недообученных и переобученных моделях в [1].