Оценка качества прогнозов
Мы можем использовать для прогнозирования разные модели или одну и ту же модель, но при разных значениях гиперпараметров. Также для обработки варьируют весь конвейер обработки данных (пайплайн, pipeline), включающий как предобработку данных (заполнение пропущенных значений, отсев аномальных наблюдений, отбор и кодирование признаков), так и итоговое построение прогнозов. Важно уметь оценивать качество модели, чтобы подобрать самую точную модель и её наилучшую конфигурацию, а также знать, на какое качество работы мы можем рассчитывать на новых данных.
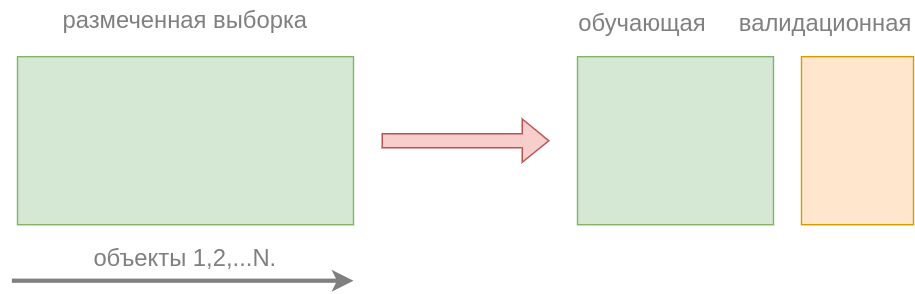
Как можно было бы оценить качество прогнозов модели? Как мы выяснили раньше, средние потери на об�учающих объектах представляют собой необъективную и слишком оптимистическую оценку потерь модели на новых объектах, занижая потери, поскольку её параметры подбираются так, чтобы именно на обучающих объектах модель работала хорошо. Для более объективной оценки модели есть два подхода - использование отложенной валидационной выборки и кросс-валидация.
Валидационная выборка
В этом подходе предлагается разбить размеченную выборку случайно на две подвыборки:
-
обучающую (training set, ~80% объектов), на которой настраивать параметры модели .
-
валидационную (validation set, ~20% объектов), на которой оценивать её качество.
Таким образом, множество индексов всех объектов случайным образом разбивается на два подмножества:
-
- индексы объектов обучающей выборки;
-
- индексы объектов валидационной выборки.
Настройка параметров производится по обучающим объектам ( - число элементов в множестве ):
При желании можно также производить настройку с регуляризацией.
Оценка качества прогнозов производится по объектам валидационной выборки:
В этом случае регуляризация не используется, т.к. нас интересует только точность итоговых прогнозов.
Данный подход также называется валидацией на отложенных данных (hold-out validation).
После того, как мы оценили качество модели на валидационной выборке, итоговая модель обучается на всех размеченных данных (и на обучающей, и на валидационной выборке). Так мы повысим качество итоговой модели, настраивая её, используя всю доступную информацию.
Кросс-валидация
Недостатком отложенной валидационной выборки является то, что приходится обучать модель на подмножестве данных, а не на всех, поскольку часть данных резервируется на оценку качества (валидационную выборку). Валидационная выборка должна занимать существенную пропорцию от всех данных, чтобы ре�презентативно представлять разнообразие новых наблюдений в будущем. Из-за этого тестируемая модель будет в общем получаться хуже, чем итоговая модель, которая обучается на всех данных.
Кросс-валидация (перекрёстный контроль, кросс-проверка, cross-validation) - другой подход, который позволяет задействовать больше размеченных объектов для обучения, и все размеченные объекты для тестирования качества прогнозов, что обеспечивает более точное оценивание качества прогнозов.
Для этого размеченная выборка делится на примерно равных групп объектов, называемых блоками (folds), а подход целиком называется -блоковой кросс-валидацией (K-fold cross-validation).
обычно берется равным от 3 до 8. Дальнейшее наращивание слишком усложняет настройку, но не приводит к существенному улучшению качества оценок.
Далее каждый из этих блоков поочерёдно исключается, а модель настраивается по оставшимся блокам, как показано на рисунке, где строки - это этапы работы алгоритма, а столбцы - блоки объектов, на которые мы разбили обучающую выборку:

После прохода по всем блокам мы получим несмещённые вневыборочные прогнозы для всех объектов, усреднением потерь на которых мы получим итоговую оценку качества.
Преимущества
-
Полученная таким образом оценка будет точнее, чем предыдущий подход, поскольку качество прогнозов будет оценено на всех располагаемых объектах, а не только на валидационной выборке.
-
Также, поскольку каждый раз исключается лишь один из небольших блоков, тестируемая модель обучается на большем объеме данных и получается ближе к итоговой, которую мы обучаем на всей выборке.
-
Поскольку модель в кросс-валидации перенастраивается раз, можно исследовать стабильность п�отерь и стабильность настроенных параметров по отдельным блокам, анализируя их стандартные отклонения по блокам. Также можно следить за тем, насколько рассогласованными получаются прогнозы между моделями, обученными на каждой подвыборке, что позволит оценивать уверенность в прогнозах.
Недостатки
Недостатком кросс-валидации является то, что приходится раз перенастраивать модель, в отличие от подхода с отложенной валидационной выборкой, где оцениваемая модель настраивалась лишь один раз.
В частном случае кросс-валидации при модель будет применена к каждому объекту в отдельности. Такой метод называется скользящим контролем (leave-one-out), но применяется только для моделей с очень быстрой настройкой, поскольку требует перенастройки модели раз.
Mетоды оценки качества прогнозов моделей и их программные реализации в вы также можете прочитать в [1].
Особенности применения методов
Альтернативная итоговая модель
Вместо обучения итоговой модели на всех данных можно в качестве итоговой брать усреднение прогнозов по моделям, обученным на каждом этапе кросс-валидации.
Такая конфигурация может показывать более высокую точность. Сложность обучения у неё ниже (не нужно настраивать модель сразу на всех данных), но сложность прогнозирования выше (поскольку придётся �для каждого прогноза усреднять по прогнозам моделей).
Случайное перемешивание
Как перед применением подхода с отложенной выборкой, так и перед кросс-валидацией важно объекты перемешать в случайном порядке, поскольку исходный порядок объектов мог быть неслучайным. Например, при диагностике заболеваний пациентов поликлиники сначала могли идти здоровые пациенты, а потом больные (во время эпидемии). Для сбалансированного разбиения на подвыборки наблюдения по пациентам необходимо предварительно перемешать.
Стратифицированное разбиение
Важно помнить, что случайное разбиение на подвыборки меняет распределение признаков и отклика. Например, в случае задачи классификации распределение классов на полной выборке и подвыборках будет различаться в зависимости от характера разбиения. Для сохранения распределения по классам можно производить случайное разбиение со стратификацией (stratified split), позволяющее сохранить исходное распределение классов в каждой подвыборке. Такое разбиение проиллюстрировано ниже для случая 3-х классов:
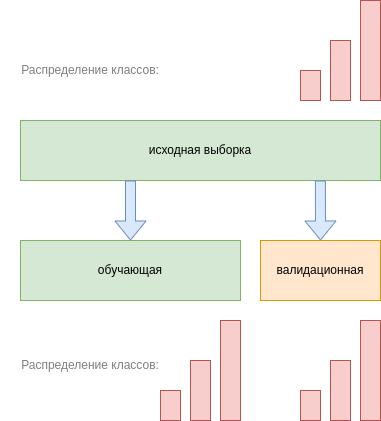
Предложите алгоритм генерации разбиения со стратификацией по классам.
Сохранить исходное распределение классов особенно важно в задаче несбалансированной классификации (umbalanced classification), в которой одни классы встречаются существенно реже остальных. В таком случае высока вероятность, что в подвыборку не попадёт ни одного объекта-представителя редкого класса, и подвыборка получится нерепрезентативной!
Примеры задач несбалансированной классификации: выявление редких заболеваний в медицинской диагностике, обнаружение мошеннических транзакций среди миллионов остальных.
Несбалансированная классификация требует особых подходов, реализованных, например, в библиотеке imbalanced-learn [2].
В случае, когда классы встречаются часто, стратификация не так критична, поскольку внутри больших подвыборок распределение классов и так будет получаться похожим на априорное распределение по всей выборке. Это следует из закона больших чисел [3].
Учет случайности результатов
Поскольку разбиение на обучающие и валидационные блоки происходит случайно, то результаты будут различаться при перезапусках. Для воспроизводимости экспериментов важно зафиксировать случайный порядок. Это достигается инициализацией генератора случайных чисел фиксированным числом (random state, random seed).
В обучающих ноутбуках генератор случайности часто инициализируют числом 42. Однако никакой магии именно в таком выборе нет, главное - зафиксировать случайность любым числом, например, нулём.
Если позволяют вычислительные ресурсы, можно перезапустить процедуру несколько раз с разной инициализацией, чтобы оценить влияние вида случайного разбиения на результат.
Анализ результатов
Полученное качество можно визуализировать в виде сравнительной таблицы качества работы разных моделей или одной и той же модели, но при разных значениях гиперпараметров.
В случае кросс-валидации полезно добавлять информацию о стандартном отклонении (standard deviation) оценки, полученной по разным блокам кросс-валидации. Эта информация позволит судить о статистической значимости различий.
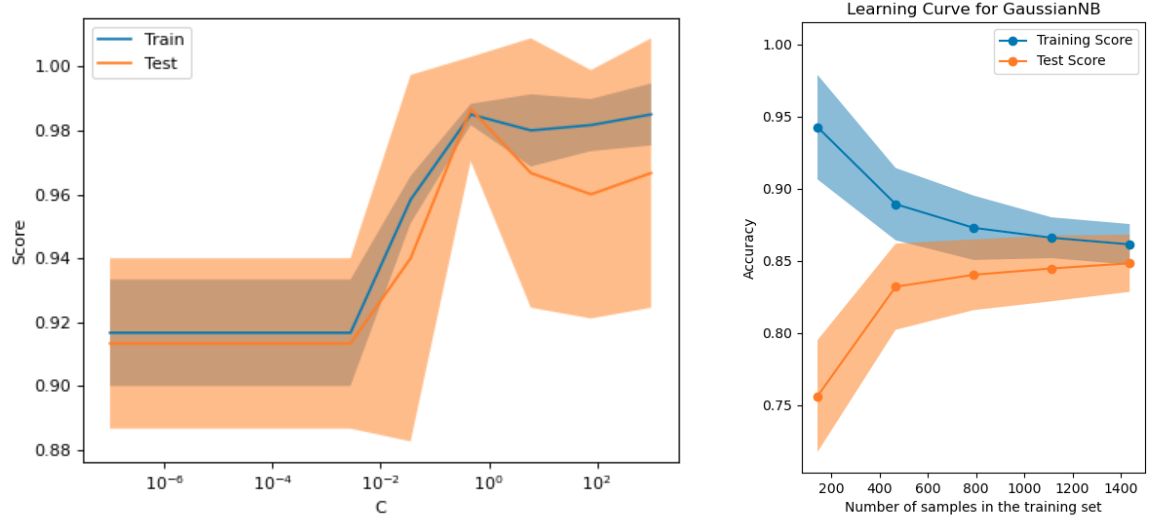
Информативно строить графики зависимости качества прогнозов от отдельного гиперпараметра (validation curve) и от размера обучающей выборки (learning curve), как показано ниже [4]:
Подбор гиперпараметров
С помощью валидационной выборки или кросс-валидации подбираются наилучшие гиперпараметры модели. Чаще всего гиперпараметры модели настраивают полным перебором по сетке значений (grid search), выбирая конфигурацию, обеспечивающую м�аксимальную точность прогнозов.
Вместо перебора по фиксированной сетке значений варианты гиперпараметров можно сэмплировать случайно из заданного диапазона (random search).
Когда случайный поиск лучше поиска по сетке?
Случайный перебор лучше поиска по сетке за счёт более полного перебора вариантов, если настраивается набор гиперпараметров, среди которых некоторые гиперпараметры слабо влияют на результат.
Рассмотрим два гиперпараметра , среди которых первый влияет, а второй - не влияет на функцию потерь. Если вычислительный бюджет позволяет сделать только 16 оценок, то при поиске по сетке будет использоваться сетка значений . Заметим, что мы переберём лишь 4 уникальных значения гиперпараметра , а перебор по всевозможным соответствующим значениям незначимого гиперпараметра будет производиться вхолостую! В случайном же поиске будут оцениваться все 16 различных значений гиперпараметра , что повысит полноту содержательного перебора.
Существуют и более продвинутые способы перебора гиперпараметров, обеспечивающие за минимальное число проверок более быструю сходимость к наилучшей конфигурации (см. hyperparameter optimization, [5]).
Если по валидационной выборке или кросс-валидации производилась настройка гиперпараметров, то использовать те же данные для итоговой оценки качества работы модели нельзя, так как при многократном переподборе значений гиперпараметров модель могла переобучиться, выбрав ту конфигурацию, которая хорошо работает именно на заданной валидационной выборке. Для несмещённой оценки качества подобранных гиперпараметров необходимо разбивать не на две, а на три выборки:
-
�обучающую (на которой настраиваем параметры модели),
-
валидационную (на которой настраиваем гиперпараметры модели),
-
тестовую (на которой уже тестируем качество итогового решения).
Только оценку качества прогнозов на отдельной тестовой выборке можно считать несмещенной в результате подбора гиперпараметров, поскольку только объекты этой выборки модель увидит в первый раз. Существует и кросс-валидационный подход многократного разбиения не на две, а сразу на три подвыборки (nested cross-validation [6]) для одновременного подбора гиперапаметров и оценки качества модели с наилучшими из них. Он обеспечивает более точную оценку качества при более высоких вычислительных ресурсах.
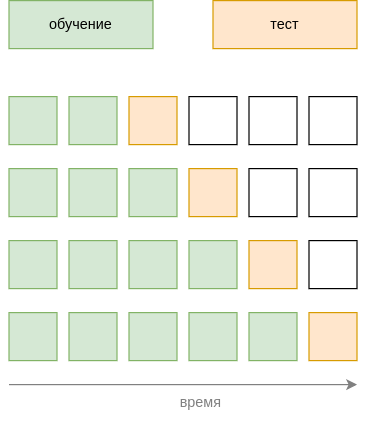
Оценка качества прогнозов для временных рядов
Для оценки качества прогнозирования временных рядов (последовательности наблюдений, которые поступают динамически по времени) нельзя использовать обычные подходы, поскольку они приведут к случайному перемешиванию объектов во времени, и мы начнём тестировать качество прогнозов более ранних наблюдений по более поздним данным!
Поэтому для временных рядов используется оценка качества прогнозов с контролем по времени (out-of-time control), при котором усредняется качество прогнозов на один или несколько шагов вперед при всевозможных временных разбиениях на известные прошлые и неизвестные будущие наблюдения, подлежащие прогнозированию, как показано на рисунке: