Настройка параметров модели
Можно вручную задать функцию соответствия (которую называют прогностической или прогнозной функцией), которая бы выдавала прогнозы отклика по известным признакам, однако зачастую это сложно сделать из-за многообразия объектов и сложных зависимостей между признаками и откликом. Поэтому в машинном обучении с учителем соответствие между признаками и откликом ищется в некотором клас�се функций , параметризованном вектором параметров , которые подбираются по обучающей выборке, состоящей из объектов:
Параметры модели также будем называть весами модели (model weights).
Например, класс функций может быть множеством всех константных прогнозов:
или состоять из всех линейных функций от признаков:
Существуют и более сложные семейства функций, о которых будет рассказано в следующих главах.
Чтобы из семейства функций выбрать наилучшую (что эквивалентно выбору определённого вектора параметров ) необходимо численно формализовать, какие прогнозы мы будем считать хорошими, а какие - плохими. Для этого задаётся функция потерь (loss function) , зависящая от истинного значения отклика и предсказанного . Чем выше значение функции потерь, тем хуже считается прогноз.
Основные функции потерь в задаче регрессии
Рассмотрим основные функции потерь в задаче регрессии:
| название | формула |
|---|---|
| квадрат ошибки (squared error, L2 loss) | |
| модуль ошибки (absolute error, L1 loss) |
Также широко используется гладкая комбинация обоих функций потерь, называемая функцией Хубера (smooth L1 loss):
В последнем случае - гиперпараметр, задающий область квадратичной зависимости, которая продлевается линейно за пределами этой области, сохраняя непрерывность самой функции и непрерывность её производной.
Будучи гладкой, эта функция удобна для оптимизации, но в то же время так же устойчива к нетипичным наблюдениям, как и модуль ошибки.
Пример потерь для классификации
Для задачи классификации простейшей функцией потерь является индикатор ошибки, вычисляемый по формуле , где функция индикатора возвращает 1, если условие выполнено, и 0 иначе. Забегая вперёд, скажем, что на практике для настройки моделей эту функцию применить нельзя, поскольку она не является дифференцируемой. Поэтому в классификации используются другие функции потерь, о которых будет рассказано далее.
Функцию потерь не нужно путать с функцией выигрыша (score function) , которая также часто встречается в машинном обучении. Для более плохих прогнозов функция потерь должна принимать более высокие значения, а функция выигрыша - наоборот, более низкие.
Например, для классификации функцией выигрыша является индикатор в�ерного угадывания класса .
Теоретический и эмпирический риск
Для настройки параметров модели традиционно желают минимизировать ожидаемые потери на новых объектах, поступающих из некоторого вероятностного распределения, называемые теоретическим риском:
Практически эта величина невычислима из-за того, что мы не обладаем информацией о теоретическом распределении объектов , а знаем лишь ограниченную обучающую выборку . Поэтому на практике параметры находятся минимизацией эмпирического риска , представляющего собой вы�борочную оценку теоретического риска по обучающей выборке:
Оценка параметров определяется как минимизатор эмпирического риска:
где - матрица "объекты-признаки", также называемая матрицей признаков (feature matrix). Строки этой матрицы соответствуют -мерным векторам признаков для каждого из объектов обучающей выборки, а - вектор откликов, которые мы хотим научиться предсказывать по признакам.
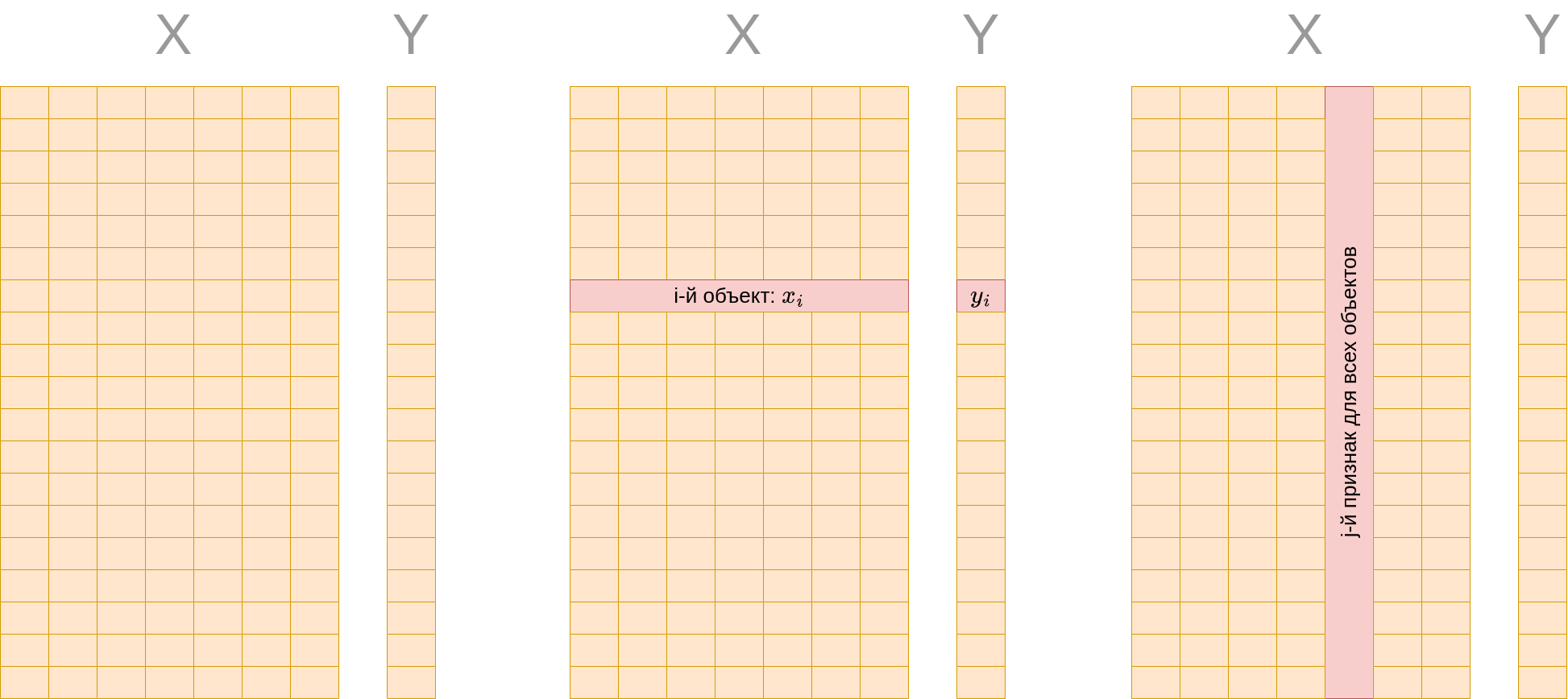
Модель с настроенными параметрами также называют алгоритмом прогнозирования.
Параметры модели не стоит путать с гиперпараметрами (hyperparameters), которые не настраиваются по обучающей выборке, а задаются пользователем либо подбираются по отдельной выборке, называемой валидационной.
Вы также можете прочитать о принципе минимизации эмпирического риска в [1].