Обучение с учителем
Признаки, отклики и обучающая выборка
Машинное обучение работает с так называемыми объектами (objects). В задаче классификации спама объектами являются письма, а в задаче предсказания времени пути - начальная и конечная точка маршрута и информация об окружающей среде, которая влияет на длительность маршрута.
Каждый объект описывается парой , где
-
- входная информация, которую мы знаем об объекте;
-
- выходная информация, которую мы хотим предсказать для объекта по .
При этом для удобства обработки входную информацию в большинстве случаев кодируют некоторым вектором фиксированной длины , где каждый элемент этого вектора называют признаком (feature), а весь вектор - вектором признаков (feature vector). Номер признака далее будем обозначать верхним индексом: .
Выходную информацию называют откликом или целевой переменной (target).
В наиболее типичной ситуации нам известна размеченная выборка из N объектов:
Такая задача называется задачей обучения с учителем (supervised learning), поскольку модель может использовать правильную "учительскую" разметку для набора из объектов для настройки своих параметров. Учительская разметка получается либо в результате ручной разметки экспертами предметной области, либо в результате логирования входных и выходных данных (которые мы хотим предсказать по входным в будущем) заранее - например, можно логировать, какие письма пользователь самостоятельно разметил как спам, чтобы в будущем научиться заранее предугадывать его предпочтения.
Типы задач обучения �с учителем
В зависимости от типа отклика, задачи обучения с учителем разделяются на следующие категории:
-
Регрессия (regression): отклик представляет собой число .
- Примеры: предсказываем время пути по маршруту; фокусное расстояние в фотоаппарате для чёткости лиц или стоимость акции на следующий день.
-
Векторная регрессия: отклик представляет собой сразу вектор вещественных ответов .
- Примеры: прогнозируем будущую стоимость не одной акции, а сразу нескольких акций одновременно; при прогнозе погоды предсказываем сразу температуру, влажность, давление и скорость ветра.
-
Ранжирование (ranking): отклик принимает вещественные значения релевантности , однако при фактическом использовании важны не абсолютные значения отклика, а относительные, потому что итоговым результатом является упорядочивание объектов по степени релевантности.
- Примеры: в информационном поиске по поисковому запросу пользователя отранжировать релевантные документы или товары в магазине.
-
Классификация (classification): отклик принимает одно из C дискретных значений - . Частным случаем классификации является бинарная классификация (binary classification), когда классов всего два. В этом случае один из них называют положительным, а другой - отрицательным, и .
-
Примеры бинарной классификации: определить, болен ли человек или здоров по результатам анализов; определить, является ли письмо спамом или полезным сообщением; предсказать, вернёт ли клиент с определёнными характеристиками кредит банку или нет.
-
Примеры многоклассовой классификации: определить человека по фото, поставить диагноз болезни по симптомам; классифицировать новость по тематике (спорт / политика / экономика / технологии / культура).
-
-
Разметка (labeling): аналогично классификации, но объект может принадлежать сразу нескольким классам или ни одному.
- Примеры: автоматическая простановка хэштегов к изображению; отнесение текста к тематическим рубрикам, которые могут одновременно в нём присутствовать.
Выше описаны наиболее типичные виды откликов, но в общем случае откликом может выступать объект произвольного типа. В частности, модели машинного обучения можно научить генерировать:
-
тексты (при переводе с одного языка на другой, при ответе на вопросы),
-
графы (при подборе химических соединений, обладающих требуемыми химическими свойствами),
-
звук (при озвучивании текста),
-
изображения (в задачах перерисовки фотографий пользователей в стиле известных художников или по текстовому запросу).
Сложно-структурированные отклики реализуются нейронными сетями, что мы изучим во второй части книги про глубокое обучение.
Пример задачи регрессии
Ниже приведён пример задачи регрессии, в которой по одномерному признаку по оси X необходимо предсказать вещественный отклик по оси Y. Обучающая выборка обозначена оранжевыми точками, по которым требуется восстановить зависимость , чтобы уметь прогнозировать целевую величину �для любых новых объектов . Как видим, это можно делать различными способами с разными ошибками прогнозов.
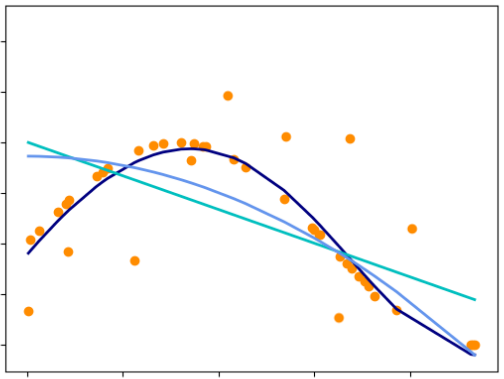
Пример задачи классификации
Далее приведен пример задачи классификации, в которой каждый объект описывается двумя признаками и , обозначенными по осям X и Y. Каждый объект обучающей выборки изображён точкой на графике. Целевая величина для прогнозирования представляет собой один из трех классов, каждый из которых показан своим цветом. По этим точкам требуется восстановить общую закономерность соотнесения любой точки одному из классов.
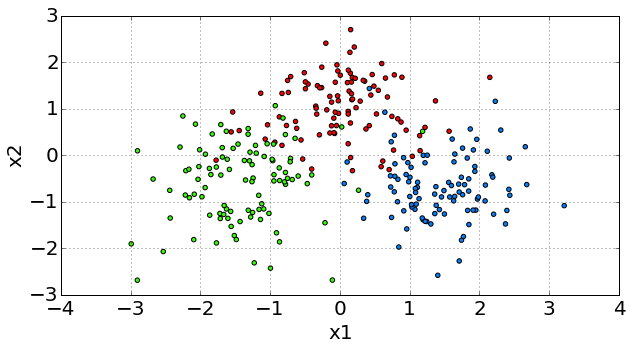
Детальнее задачи обучения с учителем описаны в [1] и [2].
Специальные постановки задачи обучения с учителем
Если, помимо обучающих объектов, заранее известны признаковые описания для тестовых объектов, для которых требуется построить прогноз в будущем, то такая задача называется трансдуктивным обучением (transductive learning). Дополнительное знание о тестовых объектах позволяет более точно настроить модель именно для этих объектов.
Существуют ситуации, когда для объектов обучающей выборки известны не только целевые переменные , но и пояснения (привилегированная информация, priveledged information), почему отклик именно такой. Рассмотрим в качестве примера задачу медицинской классификации, в которой для пациентов с заданными признаками (такими как пол, возраст, история визитов к врачу, общее состояние, текущие жалобы) требуется поставить диагноз болезни. В этой задаче разметка (итоговый диагноз врача), может содержать дополнительные пояснения , характеризующие комментарии врача, почему он поставил тот или иной диагноз. В этом случае обучающая выборка состоит уже из троек (входные признаки, отклик, пояснения):
Требуется построить модель, которая как и раньше, по входным признакам будет предсказывать отклик уже для новых объектов, но для более точной настройки модель может использовать ещё и пояснения , доступные в обучающей выборке. Настройка модели в таком случае называется learning using priviledged information (LUPI, [3]).