Кластеризация данных
Постановка задачи
Кластеризация — это разбиение объектов на группы, такие что:
- внутри групп объекты метрически похожи;
- объекты из разных групп метрически непохожи.
Метрическая похожесть определяется согласно дополнительно вводимой функции расстояния , измеряющей степень непохожести объектов друг на друга.
Чаще всего используется Евклидово расстояние или его квадрат, но строго говоря выбор расстояния диктуется логикой задачи. Используя разные функции мы будем получать разные результаты кластеризации!
Это задача обучения без учителя (unsupervised learning), так как в классической постановке здесь нет правильных ответ�ов.
Пример входных данных и результата из разбиения на кластеры показан ниже:
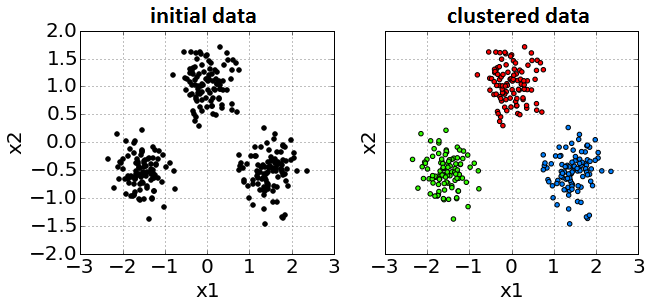
Характеристики алгоритмов
Поскольку классическая кластеризация - это задача обучения без учителя, сравнение алгоритмов кластеризации между собой по точности работы не представляется возможным. Но методы кластеризации можно сравнивать по следующим критериям:
- Используемая метрика похожести.
- Вычислительная сложность.
- Устойчивость к выбросам.
- Находится ли число кластеров автоматически или задается вручную?
- Гибкость формы извлекаемых кластеров, могут ли они быть разной плотности и невыпуклые?
- Строится ли плоская или иерархическая структура?
Применения кластеризации
Рассмотрим основные сценарии применения результатов кластеризации.
Сегментация клиентов
Это классическая задача маркетинга. Понимание того, какие группы клиентов существуют в базе, позволяет бизнесу делать персонализированные предложения (uplift) и удерживать пользователей (churn prevention).
Пример: Банк анализирует транзакции клиентов и выделяет кластеры:
- «Студенты»: много мелких транзакций в фастфуде и транспорте, малые остатки. Им предлагаем кэшбэк на развлечения.
- «Путешественники»: редкие, но крупные траты в разных странах, покупка авиабилетов. Им предлагаем страховку и премиальные карты с милями.
- «Домохозяйства»: регулярные траты в супермаркетах и аптеках. Им предлагаем ски�дки в продуктовых сетях.
Классификация без обучающей выборки
Если у нас есть большой набор данных, но нет разметки (меток классов), размечать каждый объект вручную слишком дорого. Мы можем кластеризовать данные, а затем вручную просмотреть только центры кластеров или несколько случайных примеров из каждого кластера, чтобы присвоить метку всей группе сразу. Это также называют псевдо-разметкой (pseudo-labeling).
Пример: У новостного агрегатора есть 100,000 новостных статей без тегов. Алгоритм кластеризации разбивает их на группы по встречаемости слов. Редактор просматривает ключевые слова центроидов:
- Кластер 1 (слова "гол", "матч", "счет") помечаем как "Спорт".
- Кластер 2 (слова "индекс", "акции", "торги") помечаем как "Финансы".
Так мы разметили тысячи статей, просмотрев лишь пару примеров.
Рекомендательные системы
Кластеризация позволяет строить рекомендательные системы, которые бы рекомендовали пользователям востребованные товары и услуги. Идея заключена в том, что если пользователю нравится определенный контент, то ему, скорее всего, понравится то, что популярно в его кластере среди похожих на него людей.
Пример: Онлайн-кинотеатр группирует зрителей по истории просмотров. Пользователь Иван попал в кластер любителей фэнтези вместе с Марией. И Иван, и Мария высоко оценили фильмы «Хоббит» и «Аватар». Мария также посмотрела и лайкнула «Хроники Нарнии», который Иван еще не видел. Система рекомендует этот фильм Ивану, так как он популярен в его кластере среди пользователей со схожими вкусами.
Детекция выбросов
Объекты, которые не попадают ни в один кластер (находятся от них слишком далеко) или образуют очень маленькие, разреженные кластеры, часто являются аномалиями. Выявлять подобные аномалии критически важно в финтехе и кибербезопасности.
Пример: Система мониторинга серверов собирает метрики (CPU, RAM, трафик). В обычном режиме сервера работают в нескольких стандартных состояниях. Вдруг появляется точка, далекая от всех центров: CPU 100%, а трафик 0%. Это аномалия — возможно, процесс завис или идет скрытый майнинг.
Ускорение поиска похожих объектов
Многие алгоритмы основаны на поиске ближайших соседей к объекту . Приведём примеры таких задач.
- Алгоритм k-ближайших соседей (k-NN): Поиск соседей выполняется для того, чтобы построить прогноз (классификация или регрессия). Мы ищем похожие объекты в обучающей выборке, чтобы на основе их меток предсказать метку для .
- Информационный поиск: Поиск соседей выполняется для того, чтобы найти похожих представителей в базе данных. Система должна просто вернуть пользователю список объектов (картинки, документы, товары), которые наиболее похожи на запрос .
На больших данных поиск ближайших соседей полным перебором слишком медленен, поэтому данные предварительно кластеризуют, чтобы искать соседей только внутри подходящего кластера.
Пример: Пусть мы реализуем поиск по изображениям, которые закодированы в виде компактных векторов признаков, называемых эмбеддингами. База содержит миллионы изображений. Все они предварительно кластеризованы. Когда вы загружаете фото кота, алгоритм определяет, что вектор этого фото ближе всего к кластеру, в котором сгруппированы «домашние животные / кошки». Поиск точного совпадения происходит тольк�о внутри этого кластера, игнорируя фото машин, зданий и людей.
Отладка моделей с учителем
Когда сложная модель (например, нейросеть) ошибается, анализ ошибок вручную может быть хаотичным. Если кластеризовать ошибочно обработанные объекты, а потом рассмотреть типичные случаи в рамках каждого кластера, то ошибки модели можно изучить более системно.
Пример: Модель автопилота распознает дорожные знаки с точностью 95%. Инженеры берут 5% ошибочных изображений и кластеризуют их. Анализ центров полученных кластеров выявляет разные типы системных сбоев:
- Кластер 1: Знаки ограничения скорости, частично закрытые ветками деревьев (проблема перекрытия).
- Кластер 2: Знаки «Стоп», на которые наклеены стикеры или нанесено граффити (проблема вандализма).
- Кластер 3: Знаки, залепленные снегом в сумерках (погодные условия).
Это дает чёткое понимание разных классов проблемных случаев.
Извлечение новых признаков
Результаты кластеризации использовать для генерации новых признаков, помогающих решать целевую задачу обучения с учителем. Обычно добавляют:
- One-hot кодирование номера кластера.
- Расстояния до центров кластеров.
Пример: Рассмотрим прогнозирование стоимости квартиры. Исходные признаки могут включать расположение недвижимости (широта и долгота). Линейная модель не может выучить сложную нелинейную зависимость цены от координат. Мы запускаем кластеризацию на координатах и получаем 10 кластеров (фактически, выделяем районы города: «центр», «спальный район», «промзона»). Добавление признака «Номер кластера» позволяет линейной модели назначать разную базовую цену для каждого района.
Генерация признаков для структурированных данных
Кластеризация играет ключевую роль в извлечении признаков (feature extraction) из сложных структурированных данных, таких как изображения, видео, аудиосигналы и временные ряды.
Сырые данные (например, массив пикселей или последовательность амплитуд звука) имеют слишком высокую размерность и содержат много шума. Также они могут различаться по длине и размерам. Чтобы применять к ним классические алгоритмы машинного обучения, необходимо перейти к их компактному векторному представлению фиксированной длины.
Общая идея подхода:
- Сложный объект разбивается на множество локальных фрагментов (патчи изображения, короткие нарезки звука/временного ряда).
- С помощью кластеризации находятся типичные паттерны (прототипы) среди всех фрагментов обучающей выборки.
- Каждый объект описывается частотами встречаемости этих паттернов в объекте (гистограммой).
Пример: Bag of Visual Words
Классическим примером этого подхода в компьютерном зрении является мешок визуальных слов (Bag of Visual Words, BoVW). Он позволяет представить изображение в виде вектора, используя идеи из анализа текстов. Поскольку у изображений нет естественных «слов», они создаются автоматически.
Процесс состоит из следующих шагов:
- Извлечение признаков. Из всего набора изображений выделяется множество локальных фрагментов или дескрипторов особых точек.
- Создание визуального словаря. Выделенные фрагменты кластеризуются. Полученные центры кластеров объявляются «визуальными словами», а их совокупность образует словарь (codebook).
- Квантование. Каждый фрагмент конкретного изображения заменяется на ближайшее к нему «визуальное слово» (центр кластера) из словаря.
- Построение гистограммы. Изображение описывается итоговым вектором, в котором записано, сколько раз каждое «визуальное слово» встретилось на этом изображении.
Визуальные слова и частоты их встречаемости проиллюстрированы ниже [1].
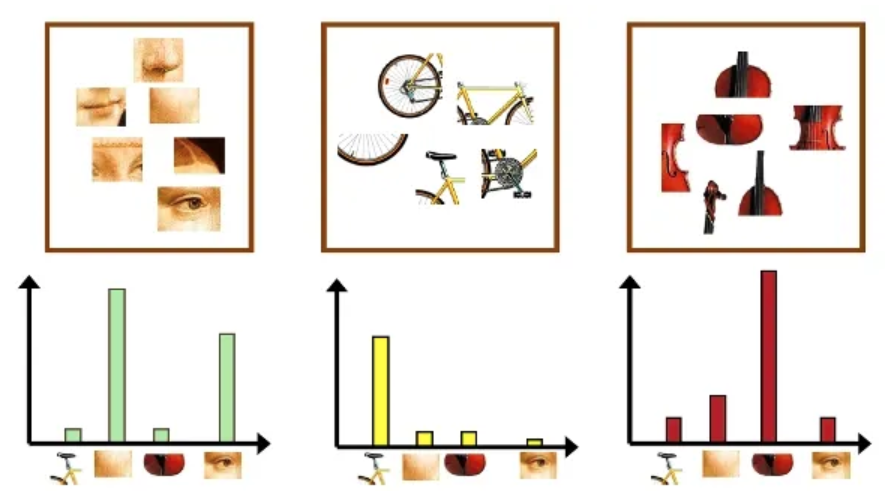
По распределению визуальных слов уже не составит большого труда обучить классификатор, умеющий различать лица, велосипеды и скрипки на изображениях.