Кластеризация K представителями
Кластеризация K представителями (representative-based clustering) обладает следующими свойствами:
- Кластеризация плоская (не иерархическая).
- Число кластеров задается пользователем.
- Каждый объект соотносится с одним и только одним кластером .
Каждый кластер определяется своим центром (представителем) , где .
В общем виде решается задача оптимизации суммарного отклонения объектов от центров их кластеров:
Настраиваемыми параметрами выступают
-
назначения объектам номеров их кластеров ;
-
центры каждого кластера , называемые также центроидами.
Метод оптимизации
Для решения этой задачи находится локальный минимум методом покоординатного спуска: Мы итеративно обновляем то метки кластеров объектов при фиксированных центроидах, то сами центроиды при фиксированных метках до сходимости. Визуально метод покоординатного спуска для минимизируемого критерия с заданными линиями уровня приведён ниже [1]:
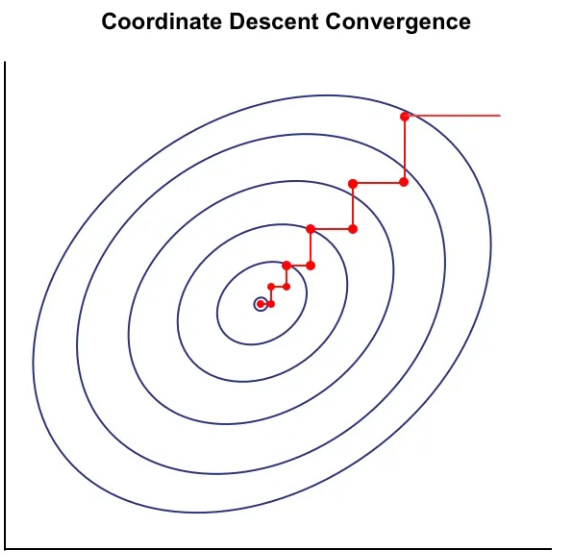
Алгоритм кластеризации представителями
Обозначим за индексы объектов, принадлежащих кластеру :
Тогда алгоритм кластеризации представителями в общем виде выглядит так:
-
Инициализировать (например, случайными объектами выборки).
-
ПОВТОРЯТЬ до сходимости:
-
Для обновить метки кластеров:
-
Для обновить центроиды кластеров:
-
-
ВЕРНУТЬ .
Этот алгоритм представляет собой не один, а целое семейство методов кластеризации, параметризованное выбором конкретной функции расстояния между объектами:
-
при получим метод K-средних;
-
при получим метод K-медиан;
Целевой функционал невыпуклый и содержит много локальных минимумов. Поэтому рекомендуется запускать оптимизацию несколько раз из разных случайных инициализаций и выбирать с наименьшим значением целевого критерия.
Критерий сходимости
В качестве критерия сходимости можно задать условие, что метки кластеров объектов не поменялись по сравнению с предыдущей итерацией. Это будет соответствовать точной сходимости алгоритма к локальному оптимуму и применимо для малых выборок.
Для больших выборок эффективнее не дожидаться полной сходимости, а прерывать настройку досрочно, когда изменения критерия а останавливаться, когда изменение положения центроидов или уменьшение значения целевой функции становится меньше заданного порога.
Также на практике часто используют жесткое ограничение на максимальное количество итераций (например, 100 или 300), так как основные изменения структуры кластеров обычно происходят на начальных этапах работы алгоритма.
Инициализация центров
Результат работы алгоритма существенно зависит от выбора начальных позиций ц�ентров . Неудачная инициализация может привести к тому, что алгоритм «застрянет» в плохом решении или будет сходиться медленнее.
Рассмотрим подходы к выбору начальных представителей.
Случайная инициализация
представителей инициализируются случайными объектами обучающей выборки. Это гарантирует, что представители будут принадлежать тому же распределению, что и исходные данные.
Это самый распространённый и простой подход, но он существенно зависит от случайности. В результате могут происходить неблагоприятные инициализации:
-
Несколько центров могут быть выбраны внутри одного плотного кластера, в то время как другие кластеры останутся без начальных центров. Это может привести к тому, что один кластер будет раздроблен, а несколько других ошибочно объединены.
-
Центр может совпасть с объектом-выбросом, лежащим далеко от остальных объектов. В результате выделится кластер, состоящий только из этого объекта.
При использовании этого метода особенно важно предварительно очистить данные от выбросов. Также, чтобы снизить чувствительность метода к случайной инициализации, рекомендуется перезапускать сходимость из разных случайных инициализаций, полученных предложенным способом, а потом выбирать наилучшее решение, обладающее минимальным значением целевого критерия и более-менее равномерно распределяющее объекты по кластерам.
Усреднение случайных подвыборок
Этот метод является модификацией случайной инициализации, направленной на повышение �устойчивости. Для инициализации каждого из центров мы выбираем не один случайный объект, а небольшую группу из случайных объектов, и вычисляем их среднее (или медиану) в качестве .
Этот подход существенно снижает риск неблагоприятной инициализации за счёт присутствия объектов-выбросов (особенно при использовании медианы, которая устойчива к выбросам). Даже если выброс попадет в подвыборку, усреднение с другими объектами «притянет» центр ближе к основной массе данных.
При увеличении параметра по закону больших чисел средние значения разных случайных подвыборок будут стремиться к общему среднему для всей выборки, что замедлит последующее расхождени�е центров по разным кластерам.
K-means++
Этот метод стал де-факто стандартом в современных библиотеках (например, в scikit-learn). Идея состоит в том, чтобы распределить начальные центры как можно дальше друг от друга, но с учетом плотности данных.
Алгоритм инициализации:
-
Первый центр выбирается случайно из объектов выборки.
-
Для каждого следующего центра :
-
Для каждого объекта вычисляется квадрат расстояния до ближайшего уже выбранного центра:
-
Новый центр выбирается из объектов случайным образом, но с вероятностью, пропорциональной вычисленному квадрату расстояния:
-
-
Процесс повторяется, пока не выбрано центров.
Детерменированный вариант В классическом варианте K-means++ является вероятностным алгоритмом. Однако его можно сделать детерминированным, если на шаге 2 выбирать не случайный объект с учетом вероятности, а объект, имеющий максимальное расстояние до текущих центров: . Такой подход, называемый MaxMin инициализацией, гарантирует воспроизводимость результата при перезапусках, но делает алгоритм чрезвычайно чувствительным к выбросам, так как именно на объектах-выбросах расстояние будет максимизироваться.
Инициализация по главной компоненте (PCA partitioning)
Этот детерминированный метод использует глобальную структуру данных. Идея состоит в том, что наибольшая вариативность данных содержится вдоль первой главной компоненты. Если «разрезать» данные вдоль этой оси, можно получить хорошее начальное приб�лижение.
Алгоритм:
- Вычислить первую главную компоненту (собственный вектор, соответствующий максимальному собственному значению ковариационной матрицы данных).
- Спроецировать все объекты выборки на этот вектор, получив одномерный массив значений .
- Разбить диапазон проекций на интервалов (по квантилям распределения), содержащих равное количество объектов.
- В качестве начальных центров взять средние значения объектов, попавших в каждый интервал или просто центров этих интервалов.
Этот подход хорошо работает, когда кластера действительно распределены вдоль одного направления, но игнорирует другие направления вариативности данных.