Вариации метода K представителей
Общая схема алгоритма представителей позволяет гибко настраивать метод под природу данных, изменяя функцию расстояния и способ обновления центров. Рассмотрим наиболее важные частные случаи помимо метода K-средних.
Метод K-медиан (K-medians)
Этот метод получается, если вместо квадратичного Евклидова расстояния использовать Манхэттенское расстояние (-норму).
Спецификация
Функция потерь для одного объекта:
Глобальный функционал ошибки (инерция):
Обновление центров
На шаге пересчета центров нам необходимо найти вектор , минимизирующий сумму модулей отклонений для объектов кластера :
Поскольку слагаемые по разным измерениям независимы, задачу можно решать для каждого признака отдельно. Известно, что сумма модулей разностей минимизируется, когда является медианой выборки .
Следовательно, новый центр кластера вычисляется как покомпонентная медиана:
Особенности метода
- Форма кластеров: Использование -метрики приводит к тому, что линии уровня имеют форму гипероктаэдров (ромбов в 2D). Кластеры стремятся выравниваться вдоль осей координат.
- Устойчивость к выбросам: Это главное �преимущество метода. Квадратичная функция в K-means сильно штрафует большие отклонения, поэтому один далекий выброс может сильно сместить среднее значение. Медиана же устойчива к отдельным аномальным значениям.
Пусть кластер состоит из точек .
- Среднее (K-means): . Центр смещен в сторону выброса, далеко от основной массы наблюдений.
- Медиана (K-medians): . Центр находится внутри плотной группы, игнорируя выброс .
Финансы и экономика: Выбросы часто возникают при анализе, например, финансовых данных, таких как доходы населения. Среднее значение в таких случаях становится слабо репрезентативным.
Кластеризация с расстоянием Махаланобиса
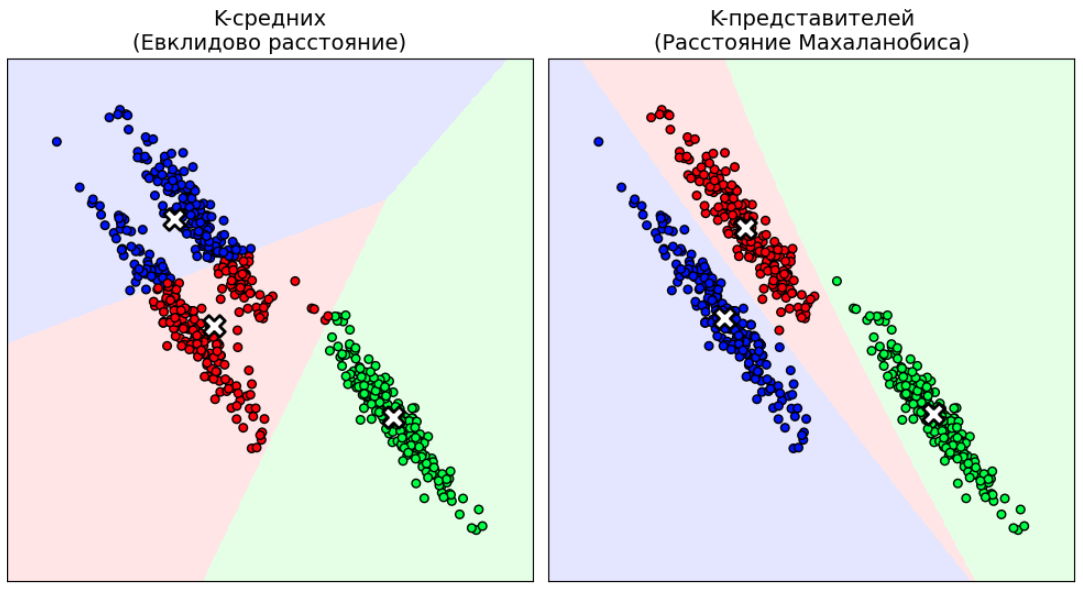
Классический метод K-средних строит сферич�еские кластеры, так как использует Евклидово расстояние. Если данные вытянуты в эллипсоиды (есть корреляция между признаками) или имеют разный масштаб, K-средних может работать некорректно, разбивая один вытянутый кластер на части.
Решение состоит в использовании в методе K-представителей в качестве функции расстояния не квадрата Евклидовой, а квадрата расстояния Махаланобиса:
где - ковариационная матрица объектов, попавших в -й кластер, позволяющая учитывать эллипсоидальную форму кластера.
Сравнение разбиения кластеров эллипсоидальной формы с помощью K-средних и K-представителей с расстоянием Махаланобиса приведён ниже:
Обновление параметров
В этом методе, помимо центров , на каждом шаге необходимо обновлять и матрицы ковариации для каждого кластера.
-
Центры: Как и в K-means, остаются средними арифметическими:
-
Ковариационные матрицы: Вычисляются как выборочная ковариация точек кластера:
Особенности метода
- Адаптивность формы: Метод способен выделять кластеры эллиптической формы, причем эллипсы могут быть повернуты и иметь разный размер для разных кластеров.
- Инвариантность: Результат не зависит от линейных преобразований координат - масштабирования и поворота.
- Связь с GMM: Данный подход с точностью до сдвига эквивалентен алгоритму кластеризации смесью Гауссиан (Gaussian Mixture Models, GMM) при сопоставлении каждому объекту одного кластера.
Необходимость хранить и обращать матрицу размера на каждой итерации делает метод вычислительно дорогим (). Кроме того, для корректной оценки ковариации требуется много данных (), иначе матрица может стать вырожденной.
Этот метод удобен для кластеризации разнородных данных, в которых признаки имеют разную природу и масштаб, когда мы не хотим подбирать коэффициенты нормализации вручную.
Метод K-медоидов (K-medoids)
Методы К-средних и K-представителей с расстоянием Махаланобиса основаны на итеративном уточнении центроидов кластеров как выборочных средних по объектам кластера. В случае K-медиан они вычисляются как медиа�ны. Подобная агрегация не возможна, если агрегируются объекты разного размера и структуры, такие как
-
временные ряды разной длины;
-
изображения разного размера
-
графы с разным числом вершин и рёбер.
Даже если объекты представимы в виде векторов одинаковой длины, подобная агрегация не всегда имеет смысл.
Рассмотрим задачу логистики, в которой нужно выбрать существующих складов из возможных, чтобы минимизировать время доставки. Мы не можем построить склад в "средней точке" (в чистом поле или озере), мы должны выбрать конкретную локацию.
В таких случаях используется метод K-медоидов, в котором накладывается дополнительное ограничение в том, что центр кластера обязан совпадать с одним из объектов обучающей выборки:
Такой объект-представитель называется медоидом.
При этом функция расстояния может быть любой, лишь бы она описывала степень различия между рассматриваемыми �объектами.
Обновление центров
На шаге пересчета центров в методе K-представителей для каждого кластера мы ищем такой объект из этого же кластера, который минимизирует суммарное расстояние до остальных:
Здесь требуется для каждого объекта вычислить расстояния до всех остальных объектов его кластера, что делает сложность пересчёта "в лоб" по числу объектов, а не , как в методе K-средних и K-медиан.
Наиболее популярная реализация этого подхода называется PAM (Partitioning Around Medoids).
Особенности метода
- Интерпретируемость: Центр кластера — это реальный пример (например, "типичный покупатель" или "эталонная статья"), а не абстрактный усредненный вектор.
- Универсальность: Работает с любыми типами данных, для которых определена мера близости (строки, множества, временные ряды).
- Устойчивость: Как и K-medians, метод устойчив к выбросам, так как медоид выбирается перебором и не может переместиться в пустое пространство.
Недостатки
Высокая �вычислительная сложность. Поиск медоида требует вычисления расстояний "всех со всеми" внутри кластера, что дает квадратичную сложность на каждой итерации. Существуют улучшенные реализации метода K-представителей для решения задачи K-медоид, такие как алгоритм PAM (Partitioning Around Medoids [1]), FastPAM и FasterPAM [2], но все они всё ещё имеют квадратичную сложность относительно числа объектов.
Поэтому применять метод K-медоид для больших данных можно лишь приближённо, находя примерные расположения медоидов по случайной подвыборке.