Метод K-средних
Кластеризация представителями
Повторим общую схему работы метода представителей:
-
Инициализировать .
-
ПОВТОРЯТЬ до сходимости:
-
Для обновить метки кластеров:
-
Для обновить центроиды кластеров:
-
-
ВЕРНУТЬ .
Здесь
-
индексы объектов, принадлежащих кластеру ;
-
назначения объектам номеров их кластеров ;
-
центры каждого кластера , называемые также центроидами.
Кластеризация методом средних
Метод средних (K-Means) является самым популярным частным случаем общего алгоритма представителей. Он получается, если в качестве меры расстояния выбрать квадрат Евклидова расстояния:
где — вектор объекта, а — вектор центра кластера. Инде�кс здесь обозначает номер признака.
Минимизируемая функция потерь называемая инерцией или внутрикластерной суммой квадратов и выглядит так:
Расчёт центроидов
Почему же метод называется " средних"? Рассмотрим шаг обновления центров при фиксированных метках кластеров . Нам нужно найти такой вектор , который минимизирует сумму квадратов расстояний до всех объектов , входящих в кластер :
Функция является суммой квадратичных функций, а значит — строго выпуклой (параболоиды с ветвями вверх). Следовательно, условие равенства градиента нулю является не только необходимым, но и достаточным условием глобального минимума.
Возьмем производную по вектору и приравняем её к нулю:
Раскрывая сумму, получаем:
Отсюда следует формула пересчета:
Таким образом, оптимальным представителем кластера по квадрату метрики является среднее арифметическое всех объектов этого кластера.
Алгоритм Ллойда
Классическая реализация метода средних называется алгоритмом Ллойда. Она выглядит следующим образом:
-
Инициализировать центры (случайно или методом K-means++).
-
ПОВТОРЯТЬ до сходимости:
-
Для обновить метки кластеров (Assign step):
-
Для обновить центроиды кластеров (Update step):
-
-
ВЕРНУТЬ .
Метод K-средних, как частный случай метода K-представителей, чувствителен к начальной инициализации центров кластеров. К нему применимы те же приёмы повышения эффективности инициализации, что и для метода K-представителей.
Пример работы
Ниже приведен процесс работы алгоритма шаг за шагом:
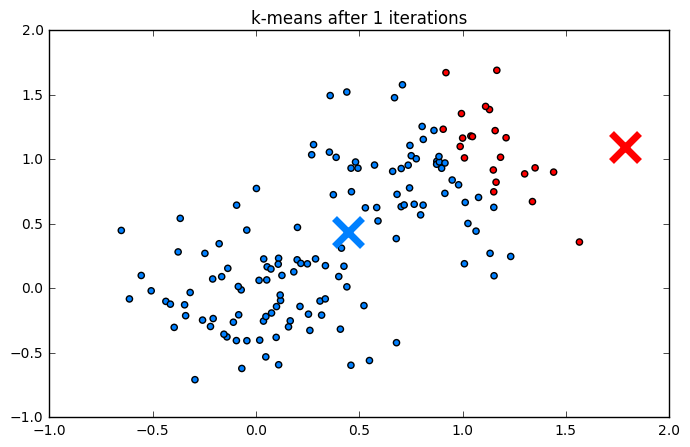
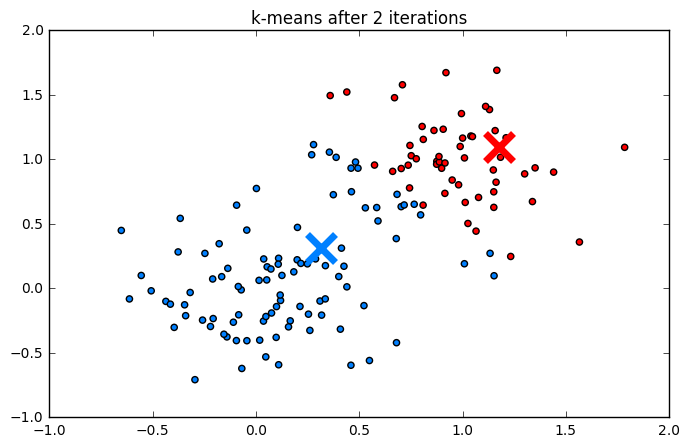
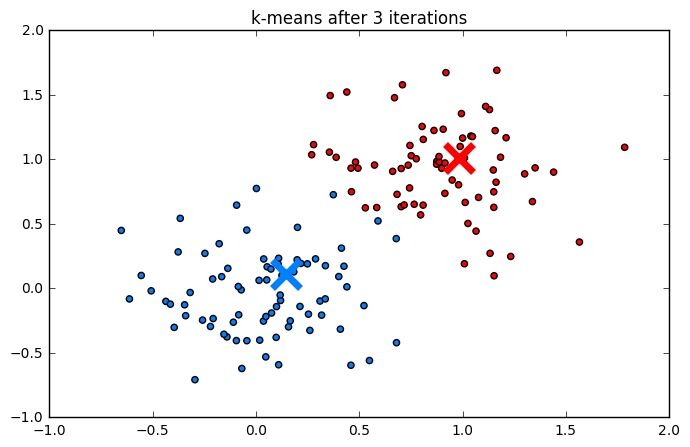
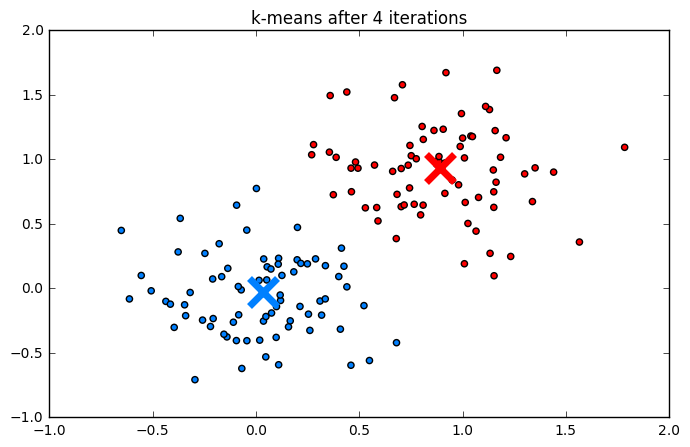
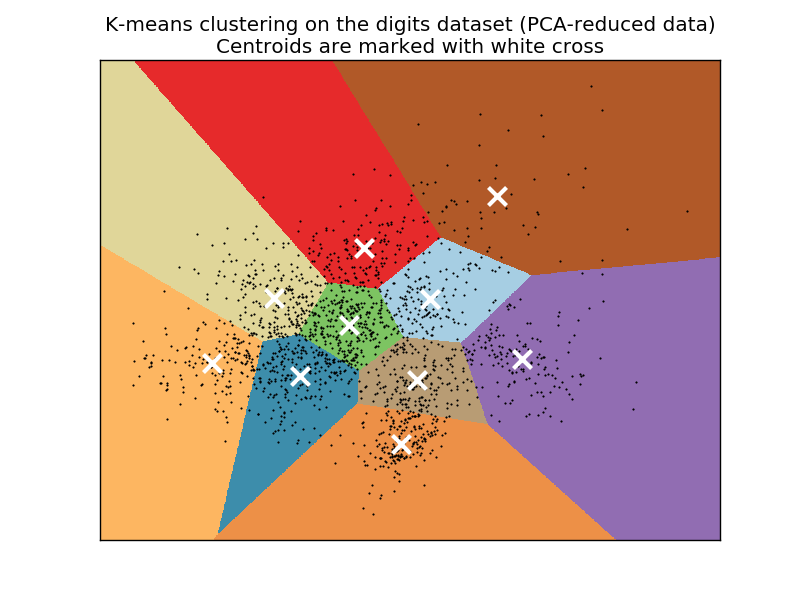
Кластеризация рукописных цифр (MNIST):
Если кластеризовать уменьшенные до двух измер�ений с помощью метода главных компонент данные датасета Digits (рукописные цифры [1]), то разбиение на кластера будет следующим [2]:
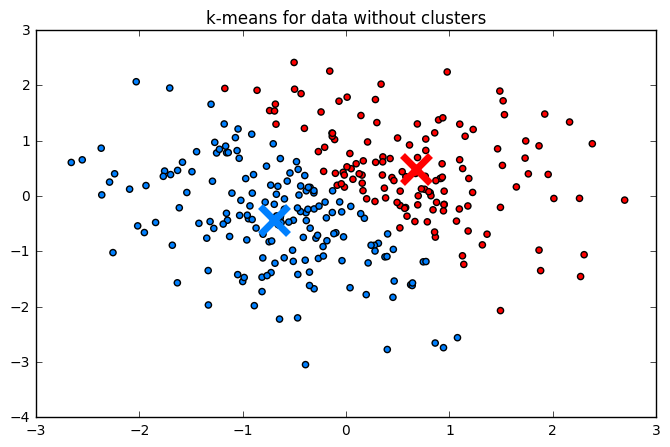
Метод всегда возвращает кластеров, где специфицированно пользователем, даже если кластерная структура в данных реально отсутствует, как на примере ниже:
Ограничения метода
Выбор Евклидова расстояния накладывает строгие ограничения на форму получаемых кластеров. Действительно, объект сильнее принадлежит -му, а не -му кластеру, если выполняется условие:
Это уравнение задает линейную полуплоскость. Множество объектов -го кластера будет получаться пересечением всех таких полуплоскостей
и представлять собой выпуклый многогранник. Таким образом, алгоритм конструктивно не сможет выделять невыпуклые кластеры, как на примере ниже:
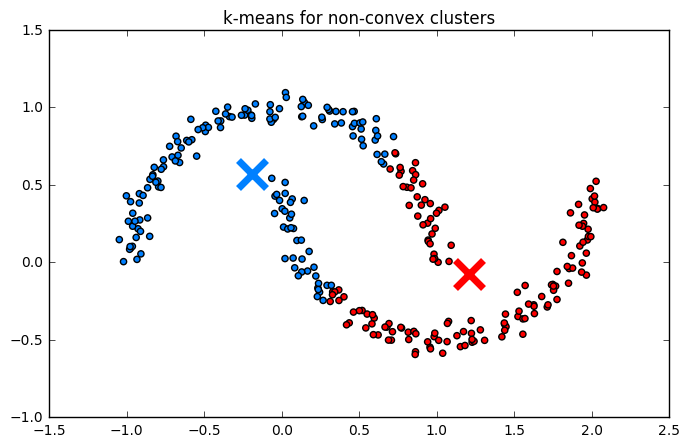
Также алгоритм стремится минимизировать дисперсию во всех направлениях одинаково. Это означает неявное предположение, что кластеры имеют сферическую форму, поэтому он будет плохо справляться с выделением сильно вытянутых кластеров.
Из равномерности учёта всех расстояний следует предположение, что кластера имеют примерно одинаковый размер.
Алгоритм K-means плохо работает с невыпуклыми кластерами (например, "два полумесяца") и может находить кластеры там, где их нет (на равномерном распределении).
Алгоритмическая сложность
Вычислительная сложность алгоритма Ллойда оценивается как , где:
- — количество объектов в выборке;
- — количество кластеров;
- — размерность пространства признаков;
- — количество итераций до сходимости.
Действительно, алгоритм состоит из итеративного повторения двух основных шагов. Рассмотрим сложность одной итерации:
-
Шаг назначения (Assignment Step): На этом этапе для каждого из объектов необходимо найти ближайший центроид.
- Чтобы вычислить квадрат Евклидова расстояния между одним объектом и одним центроидом, требуется операций.
- Это вычисление проводится для каждого из центроидов.
- Следовательно, для одного объекта сложность поиска ближайшего центра составляет .
- Для всех объектов суммарная сложность шага: .
-
Шаг обновления (Update Step): На этом этапе пересчитываются координаты центров.
- Для вычисления нового центра необходимо просуммировать векторы всех объектов, попавших в кластер , и разделить на их количество.
- Сложение двух векторов размерности требует операций.
- Поскольку каждый из объектов принадлежит ровно одному кластеру, он участвует в суммировании ровно один раз за итерацию.
- Следовательно, суммарная сложность пересчета всех центров составляет .
Важной особенностью K-Means является то, что его сложность линейно зависит от количества объектов . Это делает алгоритм пригодным для обработки больших массивов данных, в отличие от многих других методов кластеризации, имеющих более высокий порядок сложности по .
Алгоритмические оптимизации
Стандартный алгоритм Ллойда на каждой итерации вычисляет расстояния от каждого объекта до всех центров. Существуют алгоритм Элкана [3], ускоряющий этот процесс (ценой увеличенных расходов на память), который основан на использовании неравенства треугольника для расстояний:
Это позволяет отбрасывать далекие центры без явного вычисления расстояний до них, если известно, что объект уже достаточно близок к своему текущему центру.
Ускорение достигается ценой повышенных расходов на память для промежуточных переменных.
Mini-batch K-means
Для больших очень данных используется стохастическая версия алгоритма - K-средних на минибатчах (Mini-batch K-means [4]), представляющий собой аналог алгоритма стохастического градиентного спуска.
Обозначим — текущее число элементов кластера . Тогда алгоритм работает следующим образом:
-
Инициализировать (случайно).
-
Повторять до сходимости:
-
Сэмплировать минибатч случайных объектов .
-
Для :
-
определить кластер для (по принципу ближайшего центроида).
-
Обновить размер кластера: .
-
Обновить центроид кластера:
-
-
Выходом алгоритма являются центроиды по близости к которым можно кластеризовать любые данные.
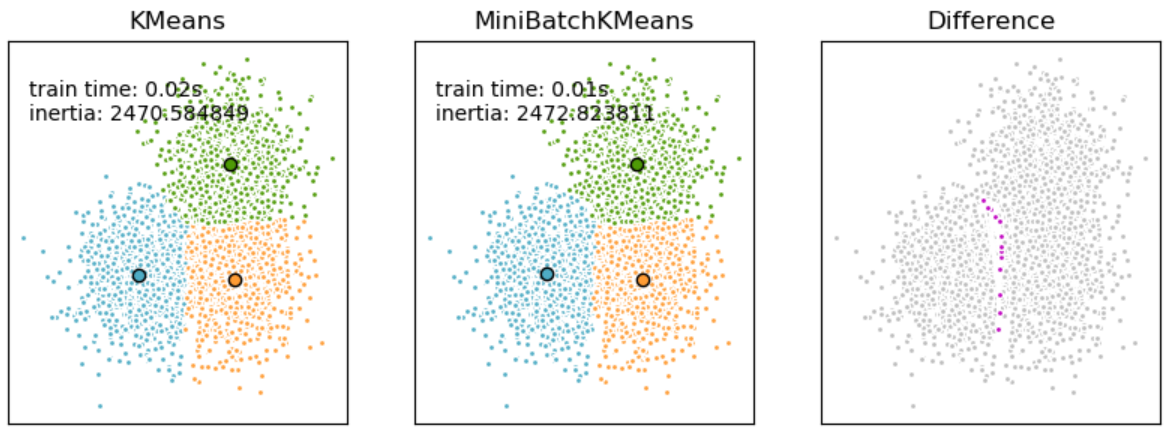
K-средних на минибатчах существенно ускоряет сходимость на очень больших данных ценой небольшого снижения качества [5]:
Ядерное обобщение K-средних
Метод K-средних выделяет лишь линейные границы между кластерами, а границы кластеров могут иметь только выпуклую форму. Однако метод K-средних допускает ядерное обобщение (Kernel K-means), которое способно сделать границы между классами нелинейными, а выделяемые области каждого класса - невыпуклыми, как показано на примере ниже:

Ядерное обобщение соответствует обычному методу K-средних, но не в исходном пространстве , а в новом пространстве , которое называемом спрямляющим.
При этом центроиды кластеров формально вычисляются по формуле
но напрямую не вычисляются, поскольку спрямляющее пространство может быть сложной структуры и даже бесконечномерным.
Расстояние от объекта до центроида кластера вычисляется по формуле:
Воспользуемся тем, что квадрат L2-нормы можно вычислить через скалярное произведение, а также свойствами скалярного произведения:
Теперь выразим каждое слагаемое через функцию ядра
-
Первое слагаемое:
-
Второе слагаемое:
-
Третье слагаемое:
Итоговая формула:
Алгоритм Ядерного K-средних
В отличие от стандартного K-means, здесь мы не можем явно хранить и пересчитывать координаты центров . Вместо этого состояние алгоритма определяется текущим распределением объектов по кластерам (метками ), которые неявно задают центроиды в спрямляющем пространстве.
Вход:
- — набор данных.
- — число кластеров.
- — функция ядра (например, RBF: ).
Алгоритм:
-
Инициализация: Случайным образом назначить начальные метки кластеров для всех объектов . Это определяет начальные множества .
-
Повторять до сходимости:
-
Для каждого кластера вычислить слагаемое, отвечающее за его компактность (не зависит от текущего объекта ):
-
Для каждого объекта :
- Вычислить расстояние от до центра каждого кластера :
(Примечание: слагаемое опущено, так как оно одинаково для всех и не влияет на выбор минимума).
- Назначить новый кластер:
-
-
Вернуть .
Недостатком kernel K-means является высокая вычислительная сложность. Чтобы вычислить расстояние от одного объекта до центра кластера , нужно просуммировать значения ядра со всеми объектами этого кластера. Суммарная сложность одной итерации составляет . Это делает метод неприменимым для больших выборок.
Литература
- Репозиторий UCI: Optical Recognition of Handwritten Digits.
- Документация sklearn: A demo of K-Means clustering on the handwritten digits data.
- Elkan C. Using the triangle inequality to accelerate k-means //Proceedings of the 20th international conference on Machine Learning (ICML-03). – 2003. – С. 147-153.
- Sculley D. Web-scale k-means clustering //Proceedings of the 19th international conference on World wide web. – 2010. – С. 1177-1178.
- Документация sklearn: Mini Batch K-Means.