Функции неопределённости решающих деревьев
Задача регрессии
При предсказании вещественного отклика в качестве функции неопределённости (impurity function) используется дисперсия откликов:
где
-
- множество индексов объектов, попадающих в узел ,
-
- количество таких объектов,
-
- выборочное среднее по откликам объектов, попадающих в узел .
Также используется среднее абсолютное отклонение (mean absolute deviation):
где - выборочная медиана откликов объектов узла .
Для более неопределённых данных с изменяющимся откликом обе меры неопределённости будут давать высокие значения. А в случае одинаковых откликов они будут равны нулю.
Задача классификации
Для классификации функции неопределённости будут зависеть от вероятностей классов для объектов, попавших в узел . Ниже представлены популярные варианты этих функций:
| название | на английском | формула |
|---|---|---|
| классификационная ошибка | classification error | |
| критерий Джини | Gini | |
| энтропийный критерий | entropy |
Обоснование функций неопределённости
Рассмотрим бинарную классификацию и некоторый узел дерева .
Пусть вероятность положительного класса , а отрицательного .
Зависимости функций неопределённости от приведены ниже:
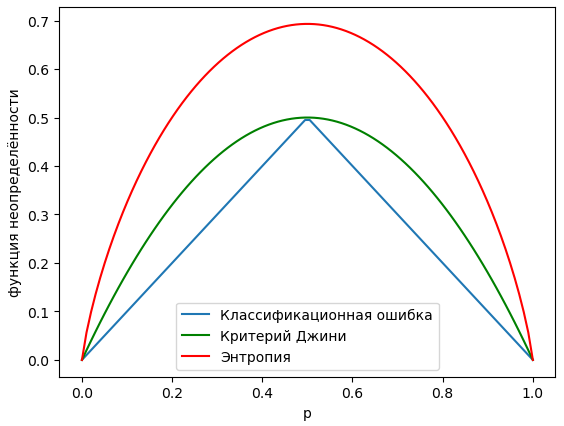
Как видим, максимальная неопределённость функций достигается в наиболее неопределённом случае, когда и оба класса равновероятны. А минимум неопределённости достигается, когда либо . В этих случаях все объекты узла принадлежат одному из классов, и неопределённость классификации отсутствует.
Для многоклассового случая представленные функции также измеряют степень неопределённости классов, достигая максимума при равномерном распределении классов, когда , а минимума, когда все объекты принадлежат одному из классов:
Интуитивно это можно понять следующим образом:
Классификационная ошибка измеряет ожидаемое число ошибок при классификации всех объектов максимально вероятным классом, у которого вероятность появления . Очевидно, что вероятность ошибки при такой классификации будет . Классификация будет безошибочной, когда в узле присутствуют объекты только одного класса, а максимум ошибок будет достигаться, когда все классы будут равновероятны.
Критерий Джини (Gini criterion) измеряет вероятность ошибки при случайном угадывании класса по правилу:
Тогда, расписывая вероятность ошибки по формуле полной вероятности [1], как раз и получим критерий Джини:
Эта ошибка будет максимальной, когда все классы равновероятны, и равняться нулю, когда все объекты принадлежат одному из классов.
Энтропийный критерий (entropy criterion) вычисляет энтропию случайной величины :
которая служит мерой её неопределённости. Покажем это.
Определим количество информации, которую мы получаем при случайном событии, реализующимся с вероятностью , по формуле
График этой зависимости показан ниже:
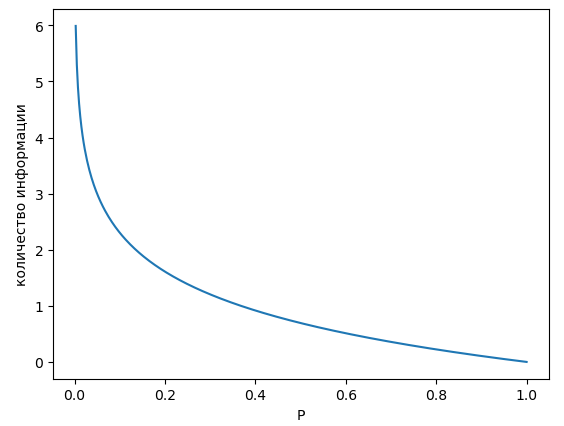
Именно так определить получаемую информацию разумно, поскольку такая функция:
-
будет выдавать нулевую информацию при реализации события, у которого вероятность наступления равна 1 (происходит всегда);
-
стремится к бесконечности при (событие происходит редко);
-
для двух независимых событий и будет выполнено свойство аддитивности:
Тогда энтропия случайной величины будет равна ожидаемому количеству информации, которую мы получим, узнав реализацию этой случайной величины:
Максимум информации мы будем получать для случая, когда все классы равновероятны, а минимум - когда реализуется всегда только один из классов.
Докажите формально, что энтропия максимизируется, когда все классы равновероятны. Для этого нужно её промаксимизировать при ограничении, что вероятности суммируются в единицу. Технически для этого используется метод множителей Лагранжа [2].