Настройка решающего дерева
Решающее дерево строится сверху вниз, начиная от корневой вершины, содержащей все объекты обучающей выборки. Сначала настраивается правило для корня, разделяющее эти объекты на две группы, первая из которых уходит левому потомку, а вторая - правому. Затем процесс расщепления вершин производится рекурсивно для каждой из образовавшихся вершин, как показано на рисунке:
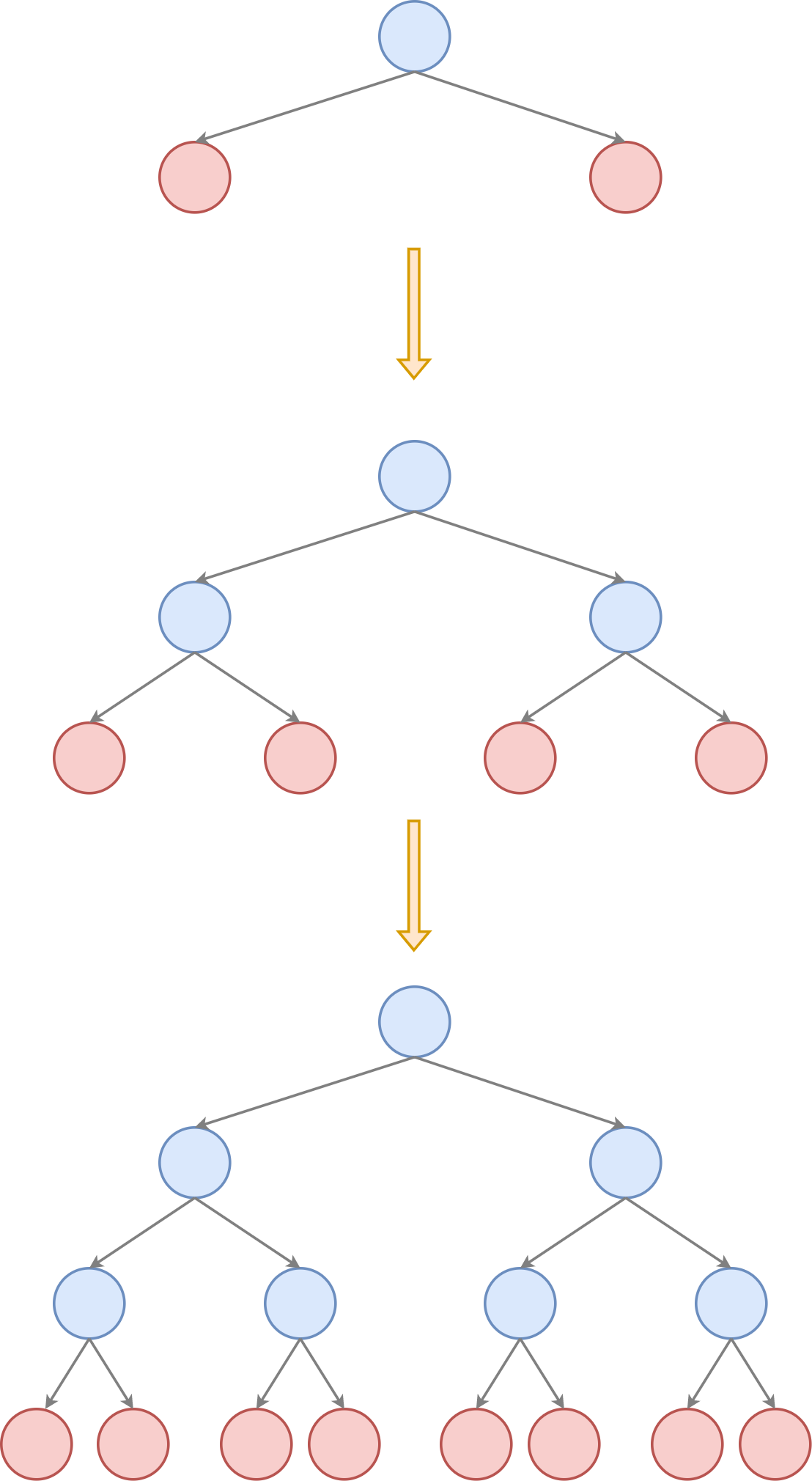
Синим показаны внутренние узлы (inner nodes), в которых подбираются правила вида
а красным - листовые вершины (terminal nodes, leaves), в которых строится итоговый прогноз.
Обратим внимание, что указанные правила в узлах одинаково хорошо работают и для вещественных, и для бинарных признаков. В последнем случае как раз образуются две ветки в зависимости от значения бинарного признака. Категориальные признаки можно закодировать через one-hot кодирование, тогда спуск по дереву будет осуществляться вправо, если категориальный признак равен определённой категории, и влево иначе. Если категорий много, то потребуется много сравнений, и всё равно не все значения категорий окажутся перепробованными.
Поэтому для решающих деревьев рекомендуется кодирование средним. Тогда при использовании образовавшегося признака объекты с высоким средним значением отклика пойдут вправо, а с низким - влево, что резко упростит прогнозирование для последующих этапов.
Выбор решающего правила во внутренних узлах дерева
Чтобы задать решающее правило в каждом внутреннем узле дерева , необходимо специфицировать, какой именно признак с каким порогом сравнивать. Для этого вводится функция неопределённости (impurity fuction) , характеризующая степень неопределённости откликов для объектов, попавших в соответствующий узел . Примеры основных таких функций будут д�аны в следующей главе, а пока достаточно знать, что
-
эта функция равна нулю, когда все объекты, попавшие в лист, имеют одинаковый отклик (соответствуют одному значению в регрессии или одному классу в классификации);
-
функция тем выше, чем сильнее неопределённость в откликах (выше дисперсия для вещественных откликов, а в случае классификации - когда распределение классов ближе к равномерному).
Для -го признака и порога решающее правило разобьёт узел на два дочерних узла: левый и правый . Если изначально в узле было объектов, то они распределятся между левым и правым потомков в количествах и .
Тогда применение правила изменит неопределённость откликов с в родительском узле на в дочерних, в результате чего получим общее изменение неопределённости:
Подбор признака и порога осуществляется перебором всевозможных признаков и значений порога (среди уникальных значений -го признака для объектов, попавших в узел ) и выбором такой пары , для которых достигается минимальная неопределённость в дочерних узлах или (что то же самое) достигается максимальное изменение неопределённости при переходе от родительского узла к дочерним:
Стоит отметить, что в алгоритме вещественные признаки будут �выбираться чаще, чем бинарные, поскольку для них больше уникальных значений порога, что даёт оптимизации больше гибкости подогнаться по порогу именно по вещественному признаку.
Сложность расчета , как будет видно из следующей главы, имеет порядок , поэтому сложность подбора решающего правила равна , поскольку для каждого признака в качестве порога нужно перебрать его всевозможные уникальные значения, число которых не превосходит .
Эту сложность можно снизить двумя способами:
-
Перебирать не все возможные пороги, а только основные. В качестве таковых можно взять 10%,20%,...90% персентиль в распределении признака. Тогда сложность подбора правила снизится до , поскольку мы будем перебирать всего 9 значений порога. Правда, для расчёта персентилей потребуется предварительно отсортировать значения каждого признака, что имеет порядок . Разумеется, можно брать и более детализированную сетку значений. Перебор по более грубой сетке значений повысит влияние бинарных признаков, т.к. они станут более конкурентоспособными в сравнении с вещественными. Также это повысит ожидаемую глубину дерева, необходимую для точного приближения данных.
-
Предварительно отсортировать каждый признак. Это наложит дополнительные вычислительные расходы на сортировку, зато позволит более эффективно пересчитывать значения функций неопределённости за , поскольку мы будем знать, какой объект переходит из правой дочерней вершины в левую при каждом изменении порога без сканирования всех объектов, и сможем пересчитывать за , используя кумулятивные статистики. Итоговая сложность подбора правила по всем порогам тогда будет .
Используя второй метод эффективного подбора правила, совокупная сложность построения всех правил на уровне будет иметь сложность (поскольку все объектов выборки проходят через один из узлов на каждом уровне), а общая сложность построения дерева глубины будет иметь порядок .
Остановка при наращивании дерева
При построении дерева сверху вниз необходимо решить, когда оканчивать дробление узлов и превращать текущие узлы в листовые. Конечно, нет смысла продолжать разбиение, если все объекты текущего узла дают одинаковый отклик. В частности, это достигается, когда в листе остался всего один объект. Но также используются и досрочная остановка по одному из следующих критериев:
-
достигнута целевая глубина ;
-
число объектов в узле меньше ;
-
число объектов в одном из дочерних узлов после оптимального разбиения оказалась меньше ;
-
неопределённость отклика в узле меньше порога ;
-
максимальное изменение неопределённости при разбиении узла меньше порога: .
Сравнение критериев
Досрочная остановка целесообразна, чтобы контролировать сложность получаемого дерева, когда мы стремимся выровнять сложность модели и сложность реальных данных. Иначе дерево, обученное до самого низа, станет переобученным и будет иметь плохую обобщающую способность на новых наблюдениях.
Критерии 2 и 3 близки по смыслу, однако критерий 3 предпочтительнее тем, что он, в отличие от критерия 2, гарантирует, что в каждом листовом узле будет достаточное количество объектов (), чтобы делать статистически значимые выводы о прогнозе в листе.
Критерий 1 приводит в общем случае к построению сбалансированного дерева (расстояние от корня до каждого листа одно и то же), однако может оказаться неоптимальным с точки зрения числа объектов в листе: какие-то листы окажутся переполненными объектами, а какие-то - недозаполненными. Поэтому среди критериев 1,2,3 следует пользоваться третьим критерием.
Критерий 5 кажется максимально релевантным оптимизации, в котором мы стремимся минимизировать и досрочно прерываем процесс настройки, если видим, что не удаётся достичь существенного изменения в неопределённости. Однако тут стоит помнить, что остановка по этому критерию субоптимальна, поскольку в начале построения дерева мы можем видеть малое изменение неопределённости, которое может стать большим при более поздних разбиениях, как показано на рисунке для случая бинарной классификации, используя два признака:

Изначальное распределение классов 50/50%, и какое бы разбиение вдоль какой бы оси мы ни выбрали, оно примерно таким и останется, поэтому изменение неопределённости . Однако, если бы мы не останавливались, а стали бы производить последующие разбиения, то мы могли бы прийти к 100% точности прогнозов!
Из-за этого, для достижения максимальной точности прогнозов, рекомендуется строить дерево до самого низа (пока объекты в каждом узле не станут иметь одинаковый отклик), а потом производить обрезку лишних ветвей (tree pruning), описанную далее. Что, впрочем, не �отменяет досрочную остановку по критерию 3, чтобы обеспечить в каждом листе минимальное количество объектов для построения статистически достоверных прогнозов.
Назначение прогноза в листах
Как только принято решение об остановке процесса построения дерева, текущий узел дерева превращается в листовую вершину, которой нужно назначить прогноз. Для этого используют простые правила:
-
в задаче регрессии назначают среднее или медиану откликов для объектов, попавших в узел.
-
в задаче классификации:
-
в качестве прогноза метки класса выдают самый распространённый класс узла;
-
если нужно выдать вероятности классов, то возвращают частотное распределение классов для объектов, попавших в узел.
-
Для минимизации пользовательской функции потерь эффективнее назначать такой прогноз в листьях дерева, который будет её минимизировать напрямую, о чем будет рассказано далее.