Обрезка решающих деревьев
Идея метода
В итеративном построении решающих деревьев сверху вниз мы анализировали различные правила остановки, и был приведён пример, когда ранняя остановка может приводить к неоптимальным решениям, поскольку начальные правила разбиения не приводят к снижению неопределённости, а последующие - приводят.
Это ситуация весьма распространена на прак�тике, поэтому для повышения точности прогнозов:
-
деревья строят до самого низа (пока в узлах не останется по одному объекту или все объекты листа не будут иметь один и тот же отклик);
-
потом обрезают лишние ветви дерева, что называется обрезкой дерева (tree pruning).
Простые подходы
В обрезке дерева его поддеревья заменяются их корнями, которые назначаются листовыми вершинами (с константным прогнозом). Делать это можно полным перебором, сравнивая качество прогнозов полного решающего дерева с обрезанным на валидационной выборке, однако придётся перебирать слишком много вариантов.
Поэтому в качестве кандидатов на обрезку можно перебирать только предпоследние вершины, потом предпредпоследние и так далее снизу вверх по дереву, однако это также требует большого числа вычислений.
Чтобы сделать поиск кандидатов на обрезку более направленным и эффективным используется алгоритм обрезки по минимальной цене.
Алгоритм обрезки по минимальной цене
В алгоритме обрезки по минимальной цене (minimal cost complexity pruning), являющегося составной частью алгоритма CART [1] дерево строится до самого низа (хотя также можно применять досрочный останов, например, по минимальному числу объектов в листьях), после чего для каждой внутренней вершины полного дерева оценивается целесообразность разрастания вершины до поддерева, сравнивая 2 ситуации:
-
когда эта вершина имеет под собой исходное поддерево;
-
когда эта вершина является терминальной (без поддерева под ним).
Эти ситуации проиллюстрированы ниже для вершины :
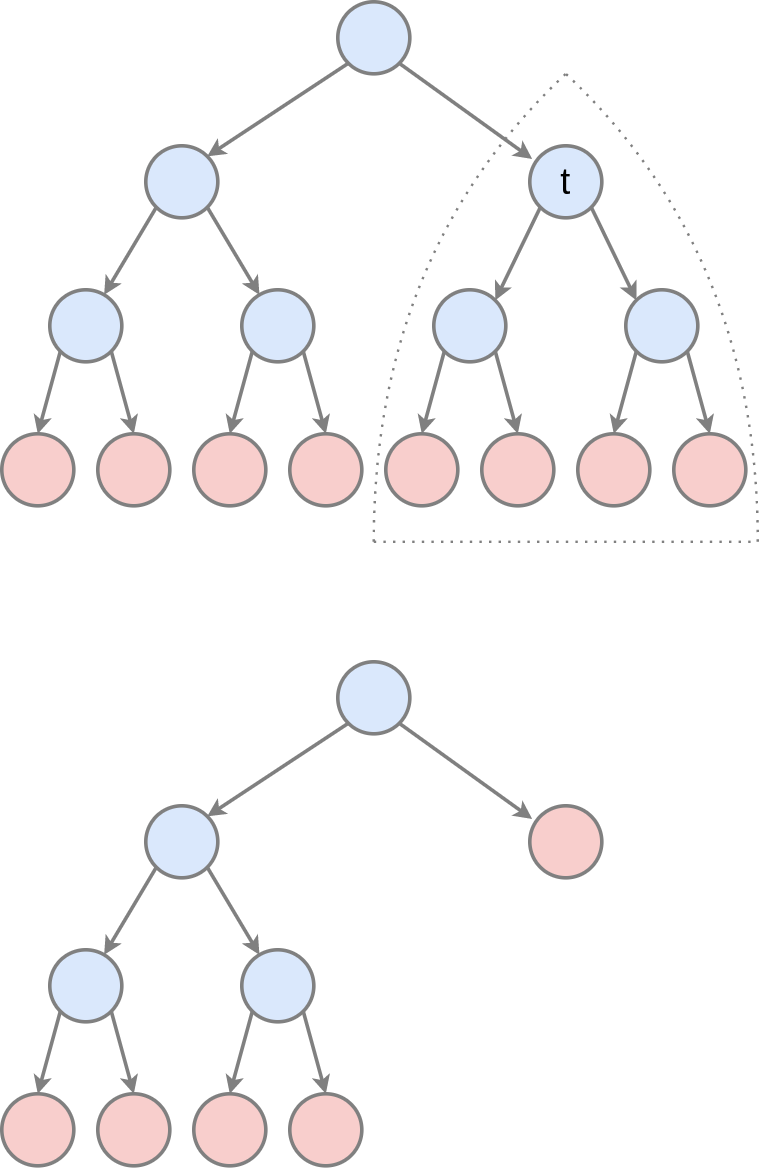
Обозначим через поддерево с корнем во внутренней вершине . Зададим штраф , вычисляющий неточность прогнозов поддерева как среднюю функцию неопределённости в листовых вершинах поддерева . Например, для регрессии это может быть дисперсия откликов, а для классификации - частота ошибок. Усреднение необходимо производить пропорционально числу объектов, попадающих в каждый лист дерева.
Дополнительно определим регуляризованный штраф , который, помимо штрафа за неточность прогнозов, штрафует поддерево за сложность, вычисляемую как количество листьев в этом поддереве. Гиперпараметр обозначает штраф за каждый дополнительный лист поддерева.
Найдём равновесное значение , при котором регуляризованный штраф за поддерево совпадёт с регуляризованным штрафом, когда поддерево заменяется на его корень (в котором сразу будет строиться прогноз, как на рисунке выше):
Это можно переписать в виде
поскольку поддерево состоит всего из одного листа.
Отсюда равновесное будет равно:
Равновесное задаёт целесообразность разрастания внутренней вершины в поддерево .
Если оно равно нулю, то разрастание полностью нецелесообразно, поскольку одиночная вершина и образованное из неё поддерево даёт одинаковый уровень ошибок. Но чем выше , тем построение поддерева целесообразнее, поскольку, чтобы компенсировать более высокую точность поддерева по сравнению с корнем, приходится сильнее штрафовать увеличение числа листов.
В алгоритме обрезки по минимальной цене вычисляются целесообразности для каждого поддерева полного дерева, после чего удаляется поддерево с минимальной целесообразностью. Далее пересчитываются для всех оставшихся вершин (достаточно пересчитывать не для всех, а только для поддеревьев, затронутых удалением с предыдущего шага), и процесс повторяется до тех пор, пока не останется одна корневая вершина исходного дерева. Таким образом, алгоритм выдаст систему вложенных друг в друга поддеревьев:
среди которых выбирается поддерево, дающее максимальную точность на валидационной выборке.
Дополнительно об алгоритмах обрезки решающих деревьях вы можете прочитать в [2]. В [3] подробно разобран пример расчёт алгоритма обрезки по минимальной цене и приведены вариации алгоритма. В [4] описано применение алгоритма в библиотеке sklearn.