Особенности прогнозов решающего дерева
В силу структуры прогнозов решающего дерева, прогнозирующая функция делит всё пространство признаков на непересекающиеся прямоугольники, каждый из которых соответствует своему листу дерева. Поскольку дерево назначает свои прогнозы каждой точке пространства признаков, некоторые прямоугольники будут иметь бесконечно вытянутые стороны в одном из направлений. В каждом прямоугольнике предсказывается некоторое константное значение целевой переменной.
Прогнозы для классификации
Рассмотрим задачу бинарной классификации на красный и синий класс в пространстве двух признаков.
Ниже приведены прогнозы для решающего дерева глубины 1,2,3,10:
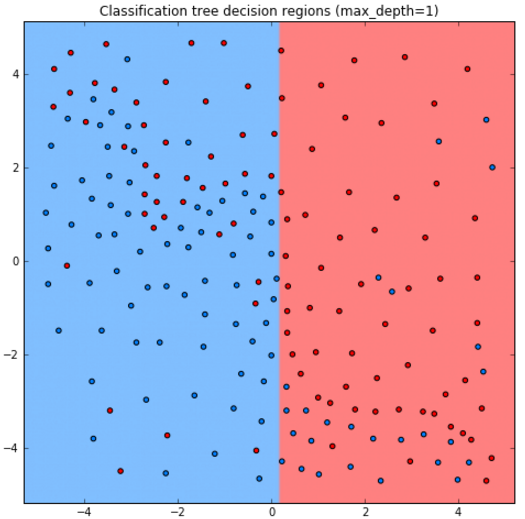
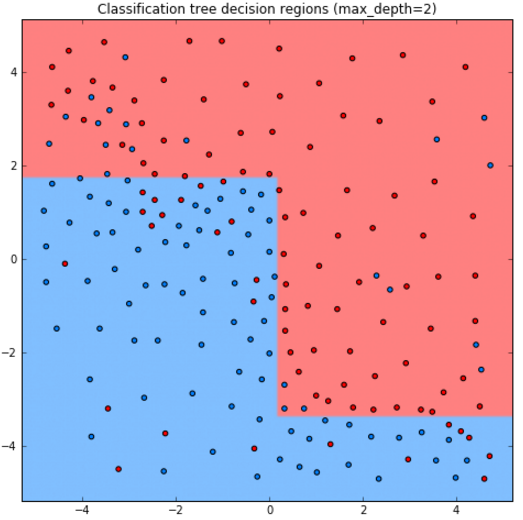
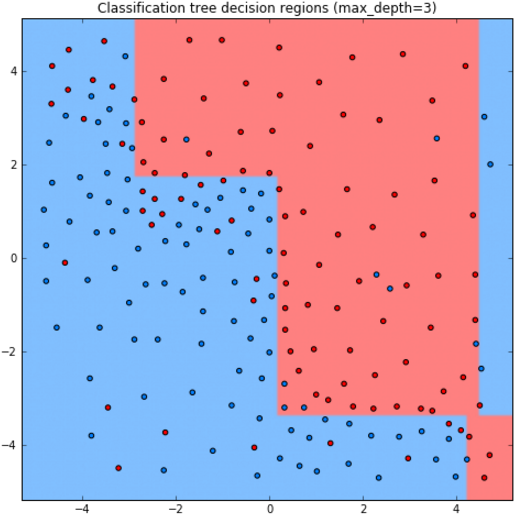
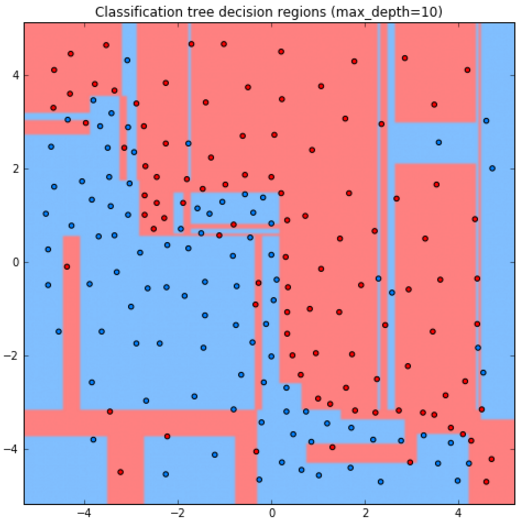
Как видим, дерево получается слишком простым при глубине 1,2, а при глубине 10 уже переобучается.
Стороны прямоугольников перпендикулярны осям координат, поскольку сами прямоугольники выделяются суперпозицией (сочетанием) условий признак порога и признак>порога. Прогноз имеет ступенчатый кусочно-постоянный вид.
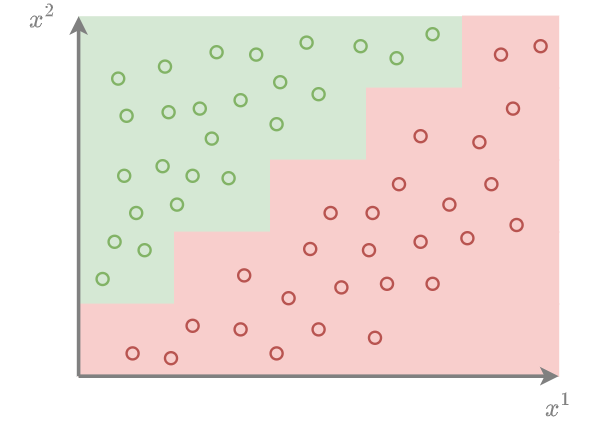
В результате решающее дерево хорошо аппроксимирует границы между откликами разных значений (для регрессии) и разных классов (в классификации), только если изменение происходит резко вдоль одного из признаков. Если же изменения отклика происходят постеп�енно или происходит не вдоль отдельного признака (например, когда граница между классами идёт под наклоном к осям), то решающему дереву потребуется сделать много разбиений, чтобы их приблизить
Ниже показан пример наклонной границы между классами, которую дереву будет сложно аппроксимировать:
Прогнозы для регрессии
Пусть целевая регрессионная зависимость имеет вид
где - одномерный признак, а - небольшой Гауссов шум. Построим решающее дерево глубины 1,2,3,4,5,10. Целевую зависимость обозначим пунктирной линией, обучающие объекты - черными точками, а прогноз дерева - синей кривой. Тогда получим следующую визуализацию прогнозов решающим деревом разной глубины:
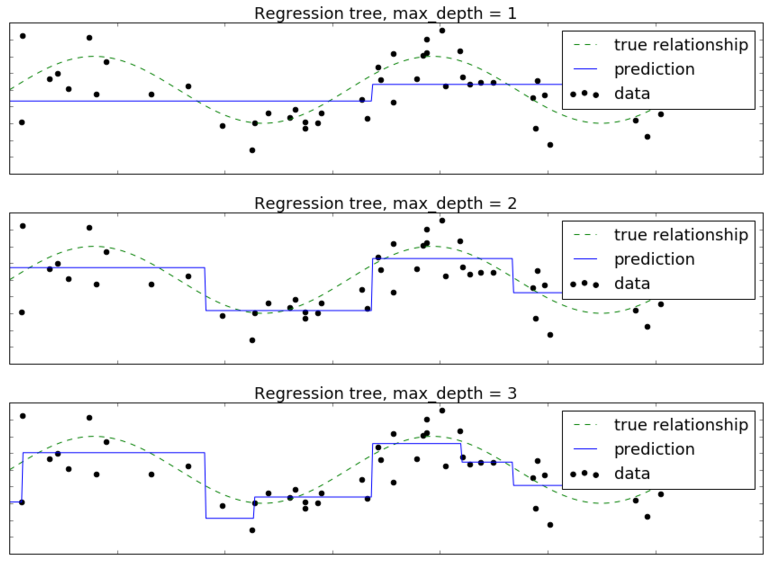
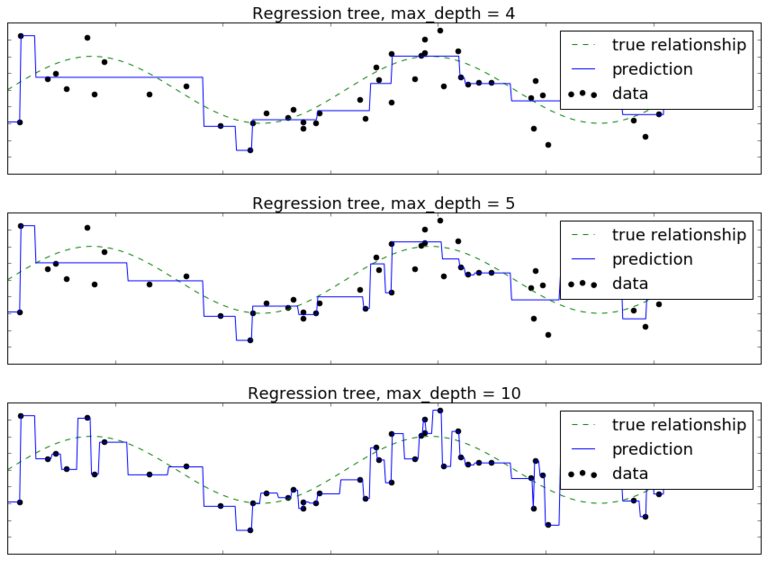
Видим, что при глубине 1,2 дерево недообучено, а при глубине 10 уже сильно переобучено. Прогнозная функция, как и в случае классификации, имеет кусочно-постоянный вид.
В многомерном случае предиктивная функция также будет иметь кусочно-постоянный вид с резкими перепадами значений вдоль осей. В результате дереву потребуется много разбиений для аппроксимации изменений отклика, происходящих под углом к осям признаков.
Решающему дереву сложно моделировать линейные зависимости между признаками и откликом, но это легко делать линейным моделям. Зато решающие деревья легко настраиваются н�а зависимости, в которых признаки оказывают совместное влияние на отклик (например, способны обработать совместный случай, когда число просрочек по кредиту>0 и объем задолженности 10.000 в примере). Линейные модели же учитывают вклад каждого признака независимо от значений остальных признаков. За счёт этого модели хорошо компенсируют ошибки друг друга, если действуют в композиции друг с другом. Композиции алгоритмов будут изучены в отдельной главе учебника.
Для комбинации линейных моделей и решающих деревьев можно использовать алгоритм RuleFit, который вначале настраивает решающие деревья, по ним извлекает набор бинарных признаков (попадает ли объект в каждый из узлов образовавшихся деревьев), после чего строит линейную модель по исходным признакам и извлечённым бинарным.
Пример запуска в Python
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
from sklearn.metrics import brier_score_loss
X_train, X_test, Y_train, Y_test = get_demo_classification_data()
# инициализация дерева (criterion - функция неопределённости):
model = DecisionTreeClassifier(criterion='gini')
model.fit(X_train, Y_train) # обучение модели
Y_hat = model.predict(X_test) # построение прогнозов
print(f'Точность прогнозов: {100*accuracy_score(Y_test, Y_hat):.1f}%')
P_hat = model.predict_proba(X_test) # можно предсказывать вероятности классов
loss = brier_score_loss(Y_test, P_hat[:,1]) # мера Бриера на вер-ти положительного класса
print(f'Мера Бриера ошибки прогноза вероятностей: {loss:.2f}')
Больше информации. Полный код.
from sklearn.tree import DecisionTreeRegressor
from sklearn.metrics import mean_absolute_error
X_train, X_test, Y_train, Y_test = get_demo_regression_data()
# инициализация дерева (criterion - функция неопределённости):
model = DecisionTreeRegressor(criterion='absolute_error')
model.fit(X_train, Y_train) # обучение модели
Y_hat = model.predict(X_test) # построение прогнозов
print(f'Средний модуль ошибки (MAE): \
{mean_absolute_error(Y_test, Y_hat):.2f}')