Регрессия опорных векторов
Ранее мы везде настраивали коэффициенты линейной регрессии минимизируя квадрат ошибки:
Но их можно настраивать, используя и други�е функции потерь, более соответствующие смыслу задачи!
Например, когда для нас несущественны небольшие отклонения в пределах , а сверх этого потери возрастают линейно, то можно использовать для настройки -нечувствительную функцию потерь (-insensitive loss):
Регрессия опорных векторов (support vector regression) - это линейная регрессия, веса которой настраиваются, используя -нечувствительную функцию потерь с L2-регуляризацией. На графике ниже показан пример настроенной регрессии опорных векторов по точкам (слева) и -нечувствительная функция потерь (справа):
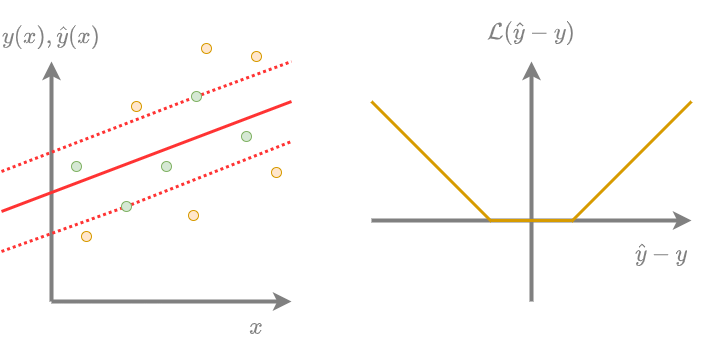
После настройки метода все объекты обучающей выборки разделятся на опорные (support vectors) и неинформативные (non-informative vectors).
Опорные объекты (выше обозначены желтыми кружками):
-
прогнозируются с ошибкой по модулю больше или равной ;
-
влияют на наклон прогнозирующей гиперплоскости .
В свою очередь, неинформативные объекты (обозначены зелёными кружками):
-
прогнозируются с ошибкой по модулю меньше ;
-
не влияют на наклон прогнозирующей гиперплоскости, поскольку на них функция потерь равна нулю.
Именно опорные объекты определяют решение задачи. Если же исключить неинформативные объекты из выборки, то итоговое решение не поменяется, поскольку потери на них равны нулю.
Если число опорных объектов невелико (а его можно контролировать, изменяя ), то можно интерпретировать модель, анализируя объекты, повлиявшие на решение.
Оптимизационную задачу для регрессии опорных векторов и формулу для построения прогноза можно переформулировать так, что прогноз будет зависеть только от скалярных произведений между векторами , а не от самих векторов . Методы, для которых выполнено это свойство, можно обобщить через ядра (применить так называемый kernel trick [1]), заменив все скалярные произведения на другую функцию, удовлетворяющую ряду свойств и называемую ядром Мерсера:
Регрессию опорных векторов таким образом можно обобщить и превратить из линейного метода в нелинейный!
Более детально с регрессией опорных векторов, её обобщениями и реализациями алгоритмов настройки параметров вы можете ознакомиться в [1].