Регуляризация в линейной регрессии
Идея регуляризации
Как известно, слишком простые (то есть недостаточно гибкие по выразительной способности) модели строят неточные прогнозы из-за недообучения, а слишком сложные (избыточно гибкие) - к неточным прогнозам из-за переобучения, что можно проиллюстрировать характерным графиком:
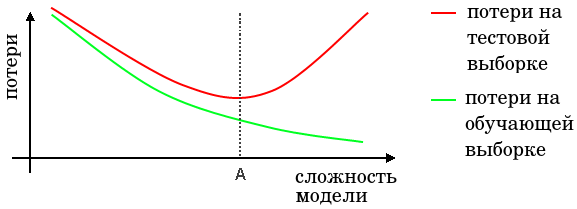
Поэтому важно подобрать сложность модели таким образом, чтобы её сложность соответствовала сложности реальных данных (точка A на граф�ике выше).
Сложность линейной регрессии можно контролировать, варьируя количество признаков, которые мы добавляем в модель, но этот подход обладает следующими недостатками:
-
Остаётся неясным, какие признаки удалять в первую очередь?
-
Характер влияния будет получаться дискретный, а не непрерывный, что препятствует более тонкой настройке сложности.
-
Если все признаки оказывают влияние, то удаление даже части из них будет ухудшать прогноз.
В связи с этими недостатками принято контролировать сложность модели, добавляя в её настройку дополнительное слагаемое (регуляризатор) , как говорилось во введении в регуляризацию:
Популярными способами выбора являются:
-
L2-регуляризация
-
L1-регуляризация
- ElasticNet-регуляризация
Гиперпараметр определяет силу регуляризации, то есть степень упрощения модели. Чем выше, тем сильнее оптимизатор при настройке весов будет ориентироваться на регуляризатор, прижимающий веса к нулю, а не на точность модели на обучающей выборке. При веса будут стремиться к нулю, а результирующий регрессионный прогноз будет вырождаться в максимально простую модель - константу.
Обратим внимание, что по формулам выше не рекомендуется подвергать регуляризации смещение , чтобы даже при слишком сильной регуляризации прогнозы оставались в среднем несмещёнными.
Для всех представленных видов регуляризации оптимизируемый критерий будет выпуклым, поэтому, найдя какой-либо минимум, мы можем быть уверены, что это глобальный минимум (докажите).
Линейная регрессия с L2-регуляризацией называется гребневой регрессией (ridge regression), а с L1-регуляризацией - лассо-регрессией (LASSO, Least Absolute Shrinkage and Selection Operator).
Сравнительные достоинства L1- и L2-регуляризации уже рассматривались ранее. Поэтому лишь напомним вкратце, что L1-регуляризация может выдавать оптимальное решение, в котором часть весов будет в точности равна нулю. В контексте линейной регрессии это означает автоматический отбор признаков, поскольку признаки при нулевых коэффициентах вообще не будут оказывать влияния на прогнозы модели. Чем выше гиперпараметр , тем больше признаков будет отброшено из модели.
Коэффициент полезно варьировать для обнаружения самых значимых признаков для прогнозирования в целях общего анализа данных и интерпретации зависимостей между ними.
L2-регуляризация, в свою очередь, способствует более равномерному распределению весов по признакам и более полному учёту входной информации.
ElasticNet-регуляризация обладает обоими свойствами и требует задания дополнительного гиперпараметра .
Гиперпараметр обычно подбирают по прогнозам на валидационной выборке или используя кросс-валидацию по логарифмической сетке значений . Найдя наилучшее значение, его можно уточнить по более мелкой сетке в окрестности найденного значения.
Решение для линейной регрессии с - и ElasticNet-регуляризацией находится численными методами, а для гребневой регрессии (L2-регуляризация) его можно найти аналитически.
Будет ли изменение масштаба признаков (после перенастройки модели с новым масштабом) влиять на решение линейной регрессии с регуляризацией?
Да, будет. Например, если признак уменьшим в 100 раз, то соответствующий коэффициент при признаке будет стремиться к увеличению в 100 раз, однако регуляризация не даст в полной мере это реализовать!
Поэтому, чтобы обеспечить регуляризацию одинаковой силы на все признаки, их необходимо предварител�ьно привести к одной шкале, используя нормализацию. Также нормализация важна, если мы хотим выявить самые значимые признаки посредством L1-регуляризации.
Версии линейной регрессии с регуляризациями L1, L2 и ElasticNet реализованы в библиотеке sklearn [1].
Пример запуска в Python
from sklearn.linear_model import Ridge
from sklearn.metrics import mean_absolute_error
X_train, X_test, Y_train, Y_test = get_demo_regression_data()
model = Ridge(alpha=1) # инициализация модели, alpha-вес при регуляризаторе
model.fit(X_train,Y_train) # обучение модели
Y_hat = model.predict(X_test) # построение прогнозов
print(f'Средний модуль ошибки (MAE): {mean_absolute_error(Y_test, Y_hat):.2f}')
Больше информации. Полный код.
from sklearn.linear_model import Lasso
from sklearn.metrics import mean_absolute_error
X_train, X_test, Y_train, Y_test = get_demo_regression_data()
model = Lasso(alpha=1) # инициализация модели, alpha-вес при регуляризаторе
model.fit(X_train,Y_train) # обучение модели
Y_hat = model.predict(X_test) # построение прогнозов
print(f'Средний модуль ошибки (MAE): {mean_absolute_error(Y_test, Y_hat):.2f}')
Больше информации. Полный код.
Зашумление признаков
Альтернативным способом регуляризации является обучение на признаках, к которым добавлен случайный шум . Это заставит модель не переобучаться под значения отдельных признаков, поскольку значения каждого признака становятся менее надёжными из-за шума. Чем дисперсия шума выше, тем сильнее регуляризующий эффект от зашумления.
Обратим внимание, что при применении модели шум не добавляется. Настроенная модель работает на исходных признаках.
Шум удовлетворяет двум свойствам:
-
нулевое мат. ожидание: ,
-
нескореллированные компоненты, каждая из которых имеет дисперсию :
где - единичная матрица.
Интересно, что если усреднять потери по всевозможным реализациям шума, то получим, что зашумление признаков эквивалентно L2-регуляризации!
Доказательство эквивалентности
где в предпоследней формуле мы использовали линейность мат. ожидания, равенство нулю мат. ожидания шума и его известную ковариационную матрицу.
Таким образом, зашумление признаков во время обучения эквивалентно в среднем добавлению L2-регуляризации. О связи зашумления признаков с регуляризацией в более общем случае нелинейных нейросетевых моделей можно прочитать в [1].