Локально-постоянная регрессия
Локально-постоянная регрессия (local constant regression), известная также как ядерная регрессия (kernel regression [1]) и регрессия Надарая-Ватсона (Nadaraya–Watson regression), представляет собой непараметрический метод для моделирования сложных регрессионных зависимостей. Она была впервые предложена в работах [2] и [3].
Допустим, нам нужно моделировать некоторую нелинейную зависимость , показанную ниже:
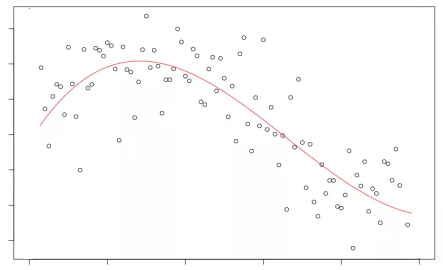
Можно было бы искать наилучший в среднеквадратичном смысле константный прогноз:
Докажите, что оптимальный константный прогноз, минимизирующий средний квадрат ошибки, это действительно выборочное среднее.
Подсказка: поскольку оптимизационный критерий по является выпуклым, то не только необходимым, но и достаточным условием оптимальности будет равенство нулю его производной.
Однако константный прогноз слишком прост и нам не подходит, поскольку целевая зависимость нелинейная. Поэтому для построения прогноза в точке будем использовать локально-постоянный прогноз, получаемый в результате минимизации квадратов ошибок в локальной окрестности от целевой точки:
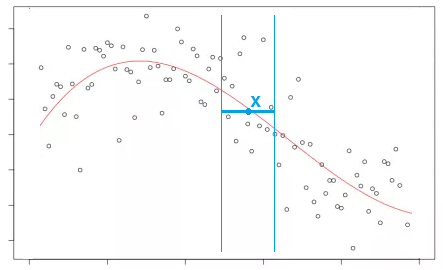
Усредняя лишь по близлежащим точкам к целевой получим нелинейную аппроксимацию общего вида, показанную на рисунке выше красной линией.
В общем случае локально-постоянная регрессия ищет наилучший константный прогноз, усредняя по всем объектам обучающей выборки, но с весами - чем объект более удалён от целевой точки, тем вес его меньше, и тем слабее он влияет на прогноз:
Докажите, что оптимальный константный прогноз, минимизирующий квадраты ошибок с весами, это действительно взвешенное среднее.
Веса определяются так же, как и в случае взвешенного учета ближайших соседей, через убывающую функцию ядра (kernel) от расстояния, нормированного на ширину окна (bandwidth):
Разница лишь в том, что теперь это веса для всех объектов обучающей выборки, а не только для ближайших соседей. Типовые ядра такие же, как раньше:
| Ядро | Формула |
|---|---|
| top-hat | |
| линейное | |
| Епанечникова | |
| экспоненциальное | |
| Гауссово | |
| квартическое |
а гиперпараметр ширины окна задаёт ширину усреднения. Для ядер top-hat, линейного, Епанечникова и квартического прогноз будет получаться усреднением только по точкам, лежащим на расстоянии не более чем от целевой. Для Гауссова и экспоненциального ядер усреднение всегда будет производиться по всем объектам, но основной вклад также будут давать объекты, лежащие в той же окрестности.
Вид ядра характеризует гладкость получаемой зависимости (рекомендуется Гауссово ядро и квартическое), однако на точность приближения больше всего влияет ширина окна - чем она выше, тем более плавной будет получаться моделируемая зависимость, которая при будет стремиться к константе (обоснуйте!).
Целесообразно варьировать гиперпараметр для разных частей признакового пространства: чем гуще лежат обучающие объекты, тем меньше мы можем взять , производя полноценное усреднение по всё еще большому числу объектов. Поэтому в общем виде этот гиперпараметр также можно сделать зависящим от :
При каком выборе и локально-постоянная регрессия превратится в метод K ближайших соседей?
Поскольку прогноз локально-постоянной регрессии зависит от объектов только через расстояния до них, то это метрический метод, который мы можем обобщать, выбирая различные функции расстояния!
Этот метод, будучи метрическим, наследует преимущества и недостатки метода ближайших соседей.
Литература
-
Nadaraya E. A. On estimating regression //Theory of Probability & Its Applications. – 1964. – Т. 9. – №. 1. – С. 141-142.
-
Watson G. S. Smooth regression analysis //Sankhyā: The Indian Journal of Statistics, Series A. – 1964. – С. 359-372.