Локально-линейная регрессия
В традиционной линейной регрессии прогноз строится как линейная комбинация признаков:
где веса находятся из принципа минимизации наименьших квадратов:
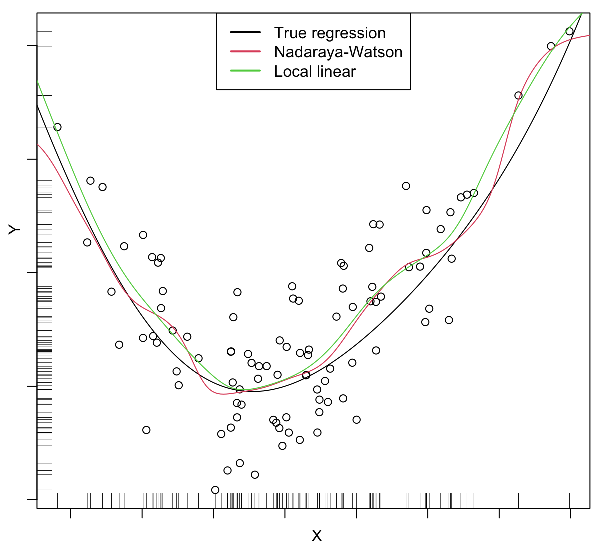
В качестве усложнения локально-постоянной регрессии мы можем использовать локально-линейную регрессию (local linear regression, locally weighted scatterplot smoothing, LOWESS), в которой прогноз также строится по формуле (1), однако параметры находятся в основном по объектам, лежащим недалеко от , за счёт минимизации взвешенной суммы квадратов ошибок, где объекты учитываются с весами :
Вес объекта определяется близостью к прогнозируемому объекту : чем он ближе, тем его вес больше. Это позволяет вычислять коэффициенты линейной регрессии адаптивно к той точке, в которой нужно построить прогноз. В другой точке зависимость также будет линейной, но уже с другими коэффициентами. Формально веса вычисляются точно так же, как веса в локально-постоянной регрессии.
Этот метод не является метрическим, поскольку оценки будут в явном виде зависеть от признаковых описаний объектов.
По сравнению с локально-постоянной регрессией, локально-линейная более вычислительно трудоёмкая (необходимо заново находить минимум (2) для каждого целевого объекта), однако она лучше экстраполирует зависимости в области, где обучающих примеров мало.