Стохастический градиентный спуск с инерцией
Метод стохастического градиентного спуска с инерцией (stochastic gradient descent with momentum, SGD+momentum [1]) - это небольшое усложнение метода стохастического градиентного спуска, которое позволяет ускорить сходимость и предотвратить застревание в локальных минимумах с небольшой окрестностью. Также он позволяет быстрее проскакивать точки перегиба и другие области медленных изменений функции потерь.
Напомним метод обычного стохастического градиентного спуска:
инициализируем , а начальные веса случайно
пока не выполнено условие остановки:
сэмплируем случайные объекты из
Метод стохастического градиентного спуска с инерцией считается аналогично, но в качестве вектора сдвига весов используется не только градиент по объектам минибатча, но и ранее посчитанные градиенты с небольшим весом, задаваемым гиперпараметром :
инициализируем , а начальные веса случайно
пока не выполнено условие остановки:
сэмплируем случайные объекты из
Компонента называется инерцией (momentum) и позволяет ускорить сходимость за счёт объединения информации о текущем градиенте с ранее посчитанными градиентами. За счёт этого градиент получается менее зашумлённым случайностью выбора объектов текущего минибатча, что позволяет использовать более высокий шаг обучения и ускорить сходимость.
Отметим, однако, что выбор высокого делает метод менее чувствительным к текущему направлению максимального снижения функции, что может, наоборот, замедлить сходимость. На практике чаще всего используют .
Рекурсивно подставляя вместо формулу их расчёта, получим, что изменение весов зависит от всех ранее посчитанных градиентов с экспоненциально убывающими весами по номеру итерации (докажите!).
Учёт инерции позволяет проскакивать локальные минимумы с малой окрестностью, сходясь к более устойчивым минимумам с большей окрестностью, как показано на рисунке:
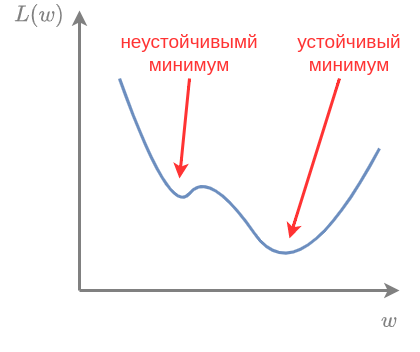
Детальное обоснование и анализ метода стохастического градиентного спуска представлено в [2].
Инерция Нестерова
Метод инерции Нестерова (Nestrov momentum [3]) позволяет ещё немного ускорить сходимость за счёт того, что градиент вычисляется в точке, более близкой к новой оценке весов на следующей итерации:
инициализируем , а начальные веса случайно
пока не выполнено условие остановки:
сэмплируем случайные объекты из
На шаге мы уже заранее знаем, что веса сдвинутся на величину инерции, поэтому можем считать градиент уже в сдвинутой точке. Подобное заглядывание вперёд позволяет заранее сместить градиент, если на следующей итерации предвидится изменение рельефа функции потерь.
Для оптимизируемых функций со сложным рельефом (особенно в настройке нейросетей) применяются более продвинутые методы, такие как RMSprop и Adam, ключевая идея которых заключается в том, что шаг обучения вычисляется независимо для каждой компоненты вектора весов. Это связано с тем, что вдоль одних осей в пространстве весов функция потерь меняется быстро, а вдоль других - медленно, поэтому, для ускорения сходимости, целесообразно адаптировать шаг обучения индивидуально для каждой оси. Эти методы описаны во второй части учебника, посвящённой нейросетям.