Метод Ньютона
Метод оптимизации Ньютона (Newton's optimization method) позволяет ускорить метод градиентного спуска за счёт использования информации не только о градиенте, н�о и о матрице вторых производных, называемой матрицей Гессе (Hessian):
Использование вторых производный позволяет ускорить сходимость, поскольку содержит информацию о скорости изменения градиента. Там, где градиент меняется медленно, можно увеличить шаг обучения, а там, где быстро, - замедлить.
Метод Ньютона выглядит следующим образом:
инициализируем настраиваемые веса случайно
пока не выполнено условие остановки:
Как видим, за счёт использования информации о вторых производных удалось избавиться от явной спецификации шага обучения - он настраивается автоматически по скорости изменения градиента домножением на матрицу Гессе, состоящую из всех вторых производных функции потерь.
Обратим внимание, что домножение на матрицу подстраивает скорость изменения вдоль каждой оси, используя градиенты вдоль всех осей.
Геометрически метод Ньютона в каждой точке строит параболу (в многомерном пространстве - параболоид), после чего смещает оценку весов в точку минимума этой параболы:
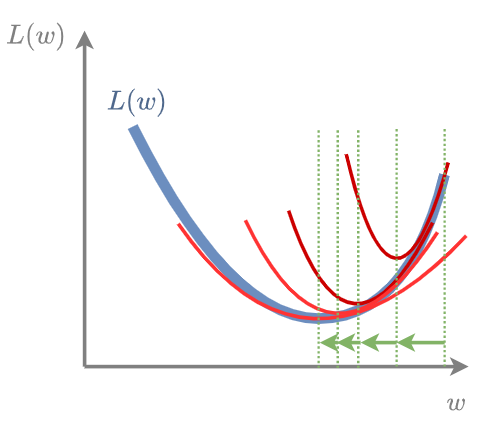
Обоснование метода Ньютона
Рассмотрим минимизацию дважды дифференцируемой функции потерь
Пусть
Тогда
Разложение Тейлора относительно в точке :
откуда
Получаем итоговое правило обновления весов, чтобы (приближённо!) переместиться в точку минимума:
При минимизации квадратичной функции погрешности , её квадратичная аппроксимация будет точной, поэтому метод Ньютона сойдётся за один шаг.
Достоинства и недостатки метода
Метод Ньютона обладает более высокой скоростью сходимости, чем метод градиентного спуска. В частности, он находит минимум квадратичного функционала всего лишь за одну итерацию. Однако практическому применению этого метода в машинному обучении мешают два аспекта:
-
Необходимость хранить в памяти матрицу Гессе, размера , а обычно велико при большом числе признаков и при использовании таких перепараметризованных моделей, как нейросети.
-
Необходимость обращать матрицу Гессе на каждой итерации, что имеет вычислительную сложность .
Детальнее о проблемах применения метода Ньютона в машинном обучении можно прочитать обсуждении [1]. Из-за перечисленных проблем на практике чаще используют квазиньютоновские методы [2], которые используют вычислительно эффективную аппроксимацию метода Ньютона.
Детальнее о методе Ньютона, условиях сходимости и альтернативных методах второго порядка рекомендуется прочитать в учебнике ШАД [3].